 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Quantization on the Robustness of Transformer-based Text Classifiers
Mar 08, 2024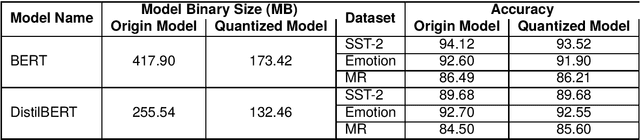

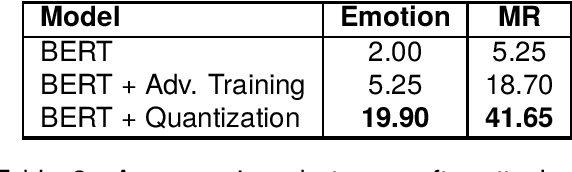
Transformer-based models have made remarkable advancements in various NLP areas. Nevertheless, these models often exhibit vulnerabilities when confronted with adversarial attacks. In this paper, we explore the effect of quantization on the robustness of Transformer-based models. Quantization usually involves mapping a high-precision real number to a lower-precision value, aiming at reducing the size of the model at hand. To the best of our knowledge, this work is the first application of quantization on the robustness of NLP models. In our experiments, we evaluate the impact of quantization on BERT and DistilBERT models in text classification using SST-2, Emotion, and MR datasets. We also evaluate the performance of these models against TextFooler, PWWS, and PSO adversarial attacks. Our findings show that quantization significantly improves (by an average of 18.68%) the adversarial accuracy of the models. Furthermore, we compare the effect of quantization versus that of the adversarial training approach on robustness. Our experiments indicate that quantization increases the robustness of the model by 18.80% on average compared to adversarial training without imposing any extra computational overhead during training. Therefore, our results highlight the effectiveness of quantization in improving the robustness of NLP models.
Improving Question Answering Performance Using Knowledge Distillation and Active Learning
Sep 26, 2021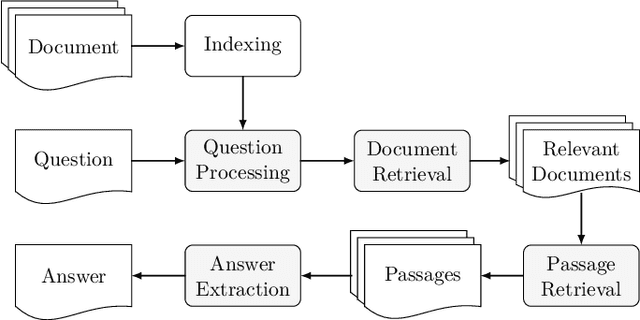

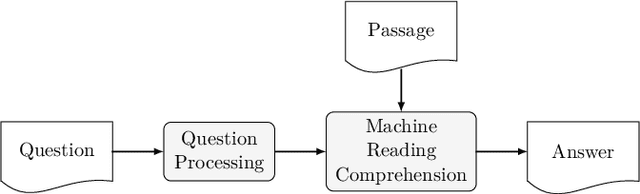
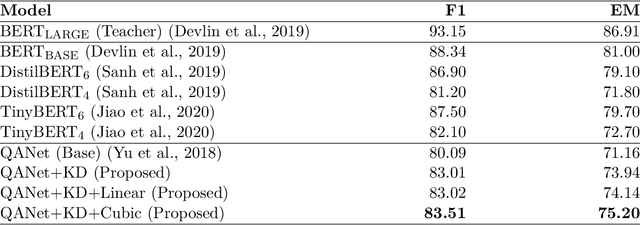
Contemporary question answering (QA) systems, including transformer-based architectures, suffer from increasing computational and model complexity which render them inefficient for real-world applications with limited resources. Further, training or even fine-tuning such models requires a vast amount of labeled data which is often not available for the task at hand. In this manuscript, we conduct a comprehensive analysis of the mentioned challenges and introduce suitable countermeasures. We propose a novel knowledge distillation (KD) approach to reduce the parameter and model complexity of a pre-trained BERT system and utilize multiple active learning (AL) strategies for immense reduction in annotation efforts. In particular, we demonstrate that our model achieves the performance of a 6-layer TinyBERT and DistilBERT, whilst using only 2% of their total parameters. Finally, by the integration of our AL approaches into the BERT framework, we show that state-of-the-art results on the SQuAD dataset can be achieved when we only use 20% of the training data.
LexiPers: An ontology based sentiment lexicon for Persian
Nov 13, 2019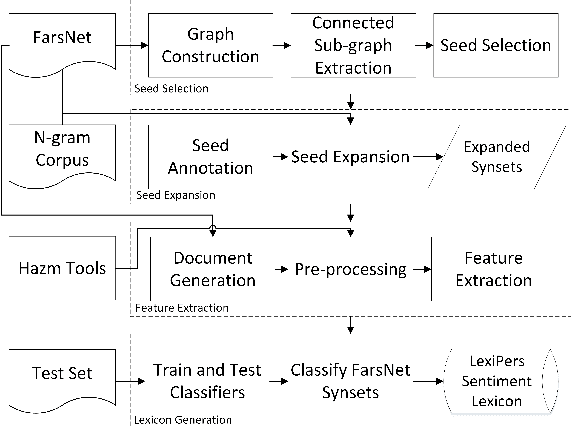

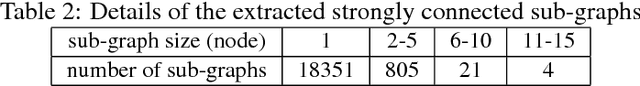
Sentiment analysis refers to the use of natural language processing to identify and extract subjective information from textual resources. One approach for sentiment extraction is using a sentiment lexicon. A sentiment lexicon is a set of words associated with the sentiment orientation that they express. In this paper, we describe the process of generating a general purpose sentiment lexicon for Persian. A new graph-based method is introduced for seed selection and expansion based on an ontology. Sentiment lexicon generation is then mapped to a document classification problem. We used the K-nearest neighbors and nearest centroid methods for classification. These classifiers have been evaluated based on a set of hand labeled synsets. The final sentiment lexicon has been generated by the best classifier. The results show an acceptable performance in terms of accuracy and F-measure in the generated sentiment lexicon.
Towards Unsupervised Learning of Temporal Relations between Events
Jan 23, 2014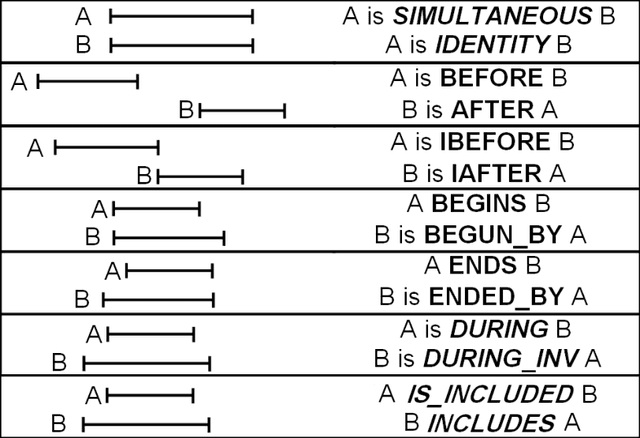

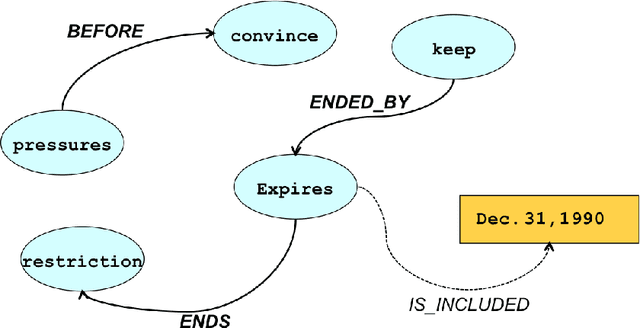

Automatic extraction of temporal relations between event pairs is an important task for several natural language processing applications such as Question Answering, Information Extraction, and Summarization. Since most existing methods are supervised and require large corpora, which for many languages do not exist, we have concentrated our efforts to reduce the need for annotated data as much as possible. This paper presents two different algorithms towards this goal. The first algorithm is a weakly supervised machine learning approach for classification of temporal relations between events. In the first stage, the algorithm learns a general classifier from an annotated corpus. Then, inspired by the hypothesis of "one type of temporal relation per discourse, it extracts useful information from a cluster of topically related documents. We show that by combining the global information of such a cluster with local decisions of a general classifier, a bootstrapping cross-document classifier can be built to extract temporal relations between events. Our experiments show that without any additional annotated data, the accuracy of the proposed algorithm is higher than that of several previous successful systems. The second proposed method for temporal relation extraction is based on the expectation maximization (EM) algorithm. Within EM, we used different techniques such as a greedy best-first search and integer linear programming for temporal inconsistency removal. We think that the experimental results of our EM based algorithm, as a first step toward a fully unsupervised temporal relation extraction method, is encouraging.