 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unsupervised Learning of Temporal Relations between Events
Paper and Code
Jan 23, 2014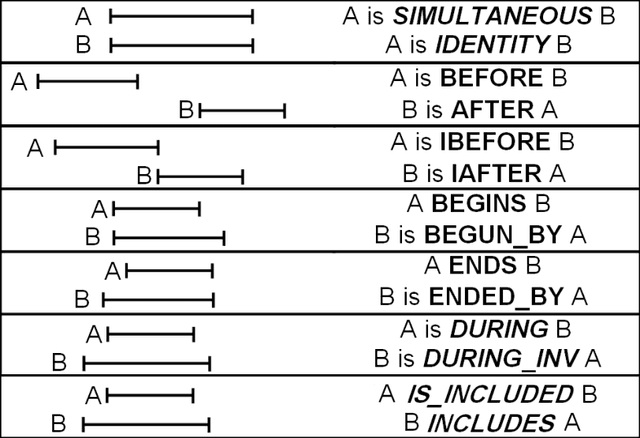


Automatic extraction of temporal relations between event pairs is an important task for several natural language processing applications such as Question Answering, Information Extraction, and Summarization. Since most existing methods are supervised and require large corpora, which for many languages do not exist, we have concentrated our efforts to reduce the need for annotated data as much as possible. This paper presents two different algorithms towards this goal. The first algorithm is a weakly supervised machine learning approach for classification of temporal relations between events. In the first stage, the algorithm learns a general classifier from an annotated corpus. Then, inspired by the hypothesis of "one type of temporal relation per discourse, it extracts useful information from a cluster of topically related documents. We show that by combining the global information of such a cluster with local decisions of a general classifier, a bootstrapping cross-document classifier can be built to extract temporal relations between events. Our experiments show that without any additional annotated data, the accuracy of the proposed algorithm is higher than that of several previous successful systems. The second proposed method for temporal relation extraction is based on the expectation maximization (EM) algorithm. Within EM, we used different techniques such as a greedy best-first search and integer linear programming for temporal inconsistency removal. We think that the experimental results of our EM based algorithm, as a first step toward a fully unsupervised temporal relation extraction method, is encouraging.