Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFQuAD: French Question Answering Dataset
Feb 14, 2020
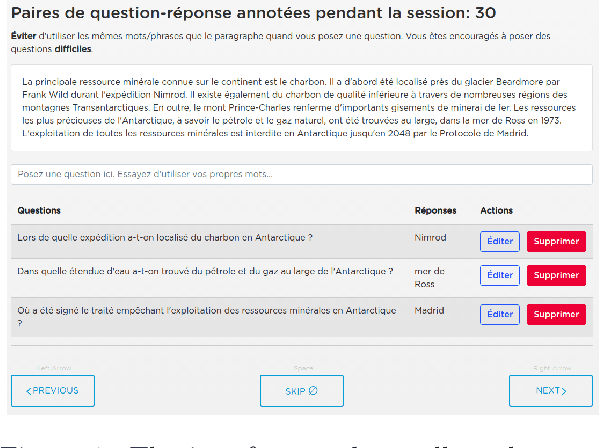
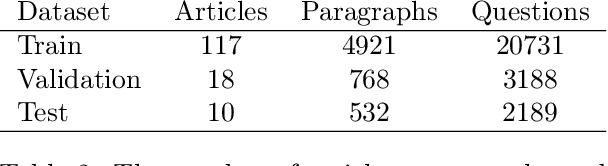

Recent advances in the field of language modeling have improved state-of-the-art results on many Natural Language Processing tasks. Among them, the Machine Reading Comprehension task has made significant progress. However, most of the results are reported in English since labeled resources available in other languages, such as French, remain scarce. In the present work, we introduce the French Question Answering Dataset (FQuAD). FQuAD is French Native Reading Comprehension dataset that consists of 25,000+ questions on a set of Wikipedia articles. A baseline model is trained which achieves an F1 score of 88.0% and an exact match ratio of 77.9% on the test set. The dataset is made freely available at https://fquad.illuin.tech.
* 12 pages, 4 figures
Via