 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Trainable Multi-Instance Pose Estimation with Transformers
Paper and Code
Mar 22, 2021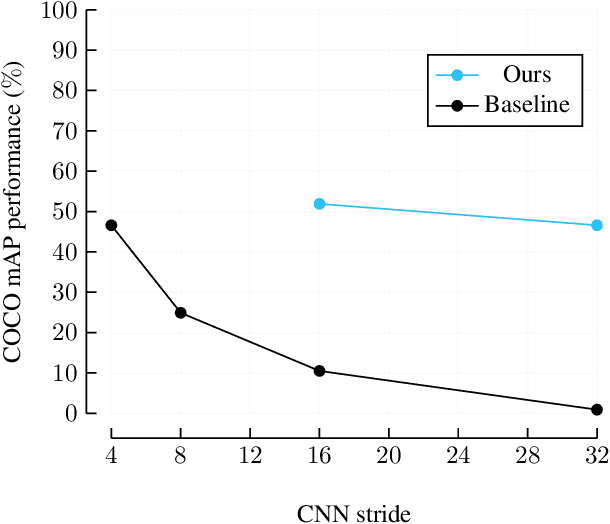
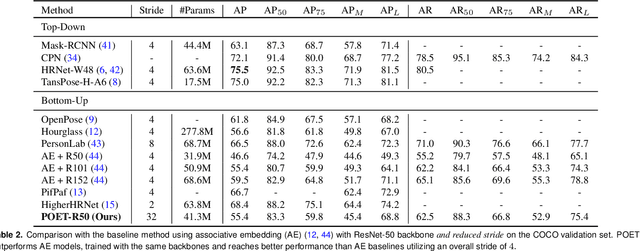
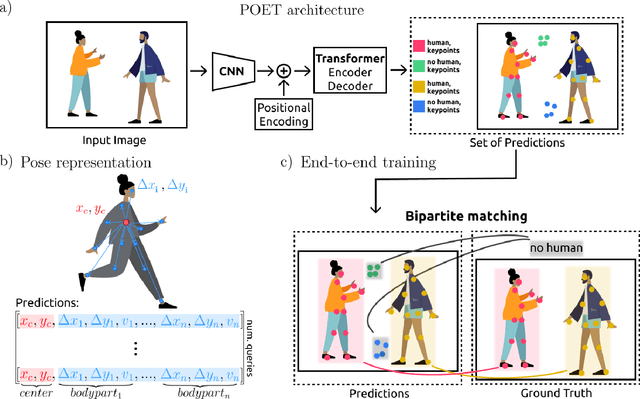

We propose a new end-to-end trainable approach for multi-instance pose estimation by combining a convolutional neural network with a transformer. We cast multi-instance pose estimation from images as a direct set prediction problem. Inspired by recent work on end-to-end trainable object detection with transformers, we use a transformer encoder-decoder architecture together with a bipartite matching scheme to directly regress the pose of all individuals in a given image. Our model, called POse Estimation Transformer (POET), is trained using a novel set-based global loss that consists of a keypoint loss, a keypoint visibility loss, a center loss and a class loss. POET reasons about the relations between detected humans and the full image context to directly predict the poses in parallel. We show that POET can achieve high accuracy on the challenging COCO keypoint detection task. To the best of our knowledge, this model is the first end-to-end trainable multi-instance human pose estimation method.