 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural analysis of an all-purpose question answering model
Paper and Code
Apr 13, 2021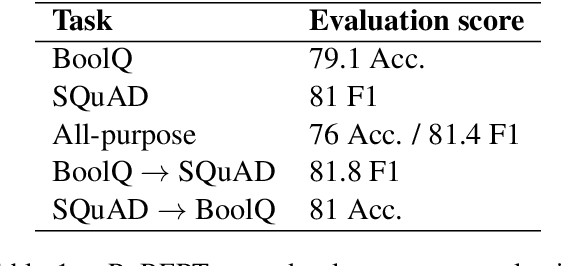
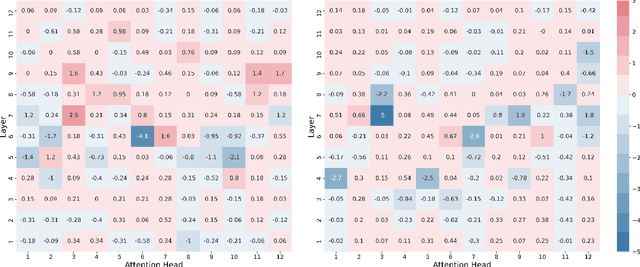
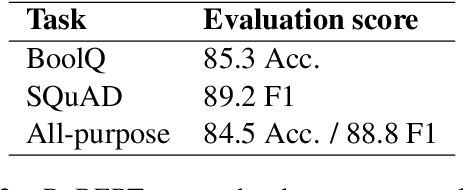
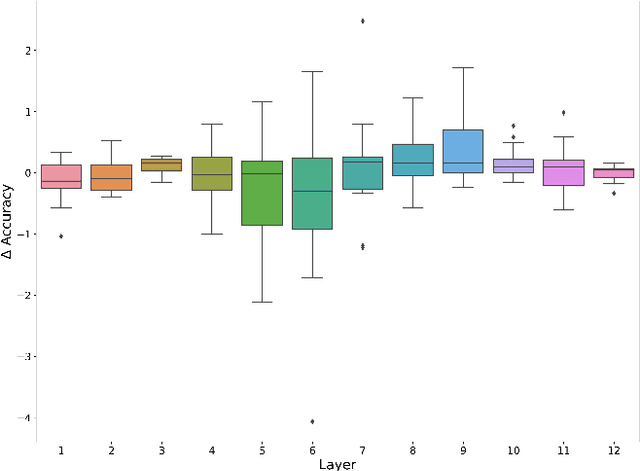
Attention is a key component of the now ubiquitous pre-trained language models. By learning to focus on relevant pieces of information, these Transformer-based architectures have proven capable of tackling several tasks at once and sometimes even surpass their single-task counterparts. To better understand this phenomenon, we conduct a structural analysis of a new all-purpose question answering model that we introduce. Surprisingly, this model retains single-task performance even in the absence of a strong transfer effect between tasks. Through attention head importance scoring, we observe that attention heads specialize in a particular task and that some heads are more conducive to learning than others in both the multi-task and single-task settings.