 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Self-Play For Data-Free Training
Sep 09, 2025Large language models (LLMs) have advanced rapidly in recent years, driven by scale, abundant high-quality training data, and reinforcement learning. Yet this progress faces a fundamental bottleneck: the need for ever more data from which models can continue to learn. In this work, we propose a reinforcement learning approach that removes this dependency by enabling models to improve without additional data. Our method leverages a game-theoretic framework of self-play, where a model's capabilities are cast as performance in a competitive game and stronger policies emerge by having the model play against itself - a process we call Language Self-Play (LSP). Experiments with Llama-3.2-3B-Instruct on instruction-following benchmarks show that pretrained models can not only enhance their performance on challenging tasks through self-play alone, but can also do so more effectively than data-driven baselines.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Extreme Classification in Log Memory using Count-Min Sketch: A Case Study of Amazon Search with 50M Products
Oct 28, 2019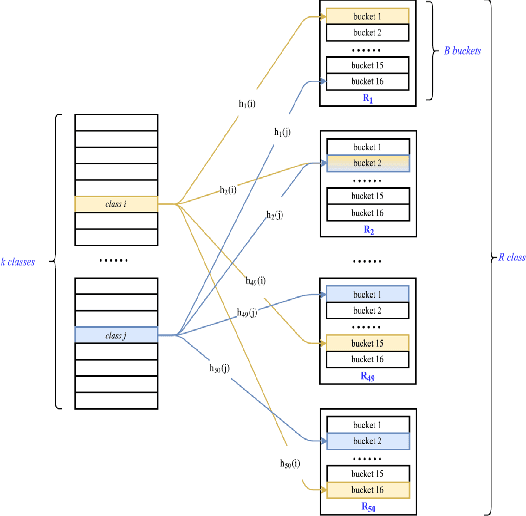

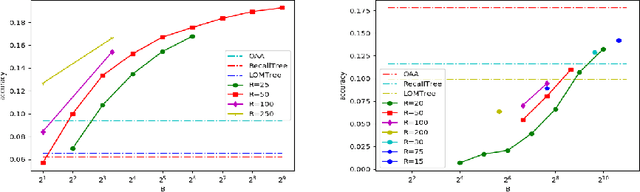
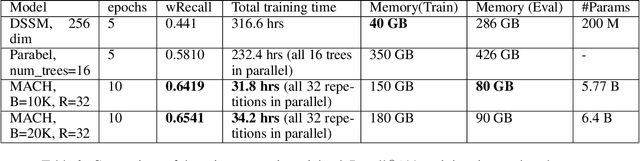
In the last decade, it has been shown that many hard AI tasks, especially in NLP, can be naturally modeled as extreme classification problems leading to improved precision. However, such models are prohibitively expensive to train due to the memory blow-up in the last layer. For example, a reasonable softmax layer for the dataset of interest in this paper can easily reach well beyond 100 billion parameters (>400 GB memory). To alleviate this problem, we present Merged-Average Classifiers via Hashing (MACH), a generic K-classification algorithm where memory provably scales at O(logK) without any strong assumption on the classes. MACH is subtly a count-min sketch structure in disguise, which uses universal hashing to reduce classification with a large number of classes to few embarrassingly parallel and independent classification tasks with a small (constant) number of classes. MACH naturally provides a technique for zero communication model parallelism. We experiment with 6 datasets; some multiclass and some multilabel, and show consistent improvement over respective state-of-the-art baselines. In particular, we train an end-to-end deep classifier on a private product search dataset sampled from Amazon Search Engine with 70 million queries and 49.46 million products. MACH outperforms, by a significant margin,the state-of-the-art extreme classification models deployed on commercial search engines: Parabel and dense embedding models. Our largest model has 6.4 billion parameters and trains in less than 35 hours on a single p3.16x machine. Our training times are 7-10x faster, and our memory footprints are 2-4x smaller than the best baselines. This training time is also significantly lower than the one reported by Google's mixture of experts (MoE) language model on a comparable model size and hardware.
Semantic Product Search
Jul 01, 2019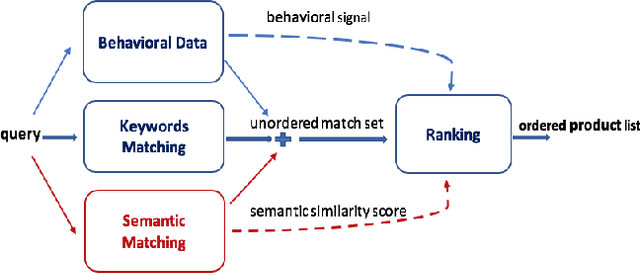
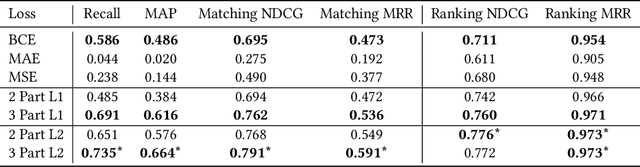
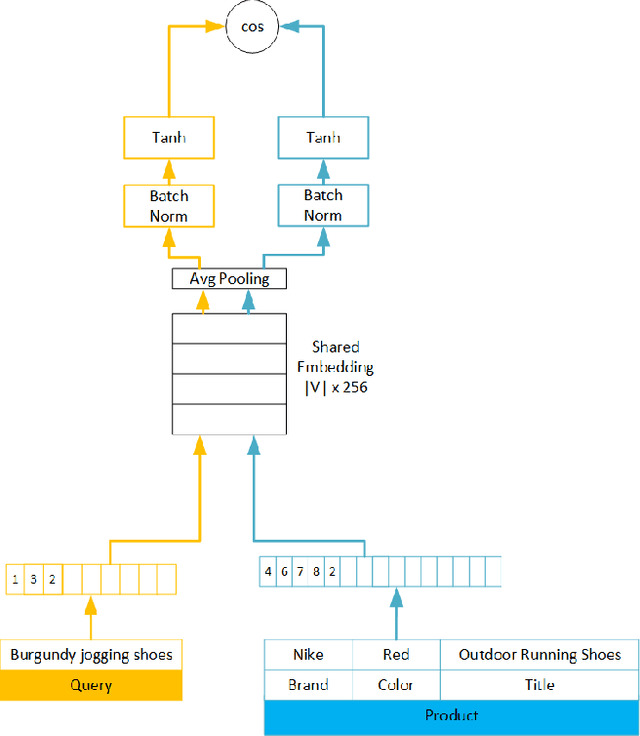
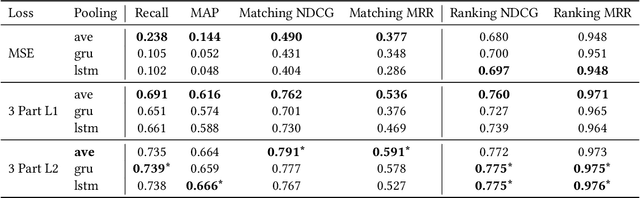
We study the problem of semantic matching in product search, that is, given a customer query, retrieve all semantically related products from the catalog. Pure lexical matching via an inverted index falls short in this respect due to several factors: a) lack of understanding of hypernyms, synonyms, and antonyms, b) fragility to morphological variants (e.g. "woman" vs. "women"), and c) sensitivity to spelling errors. To address these issues, we train a deep learning model for semantic matching using customer behavior data. Much of the recent work on large-scale semantic search using deep learning focuses on ranking for web search. In contrast, semantic matching for product search presents several novel challenges, which we elucidate in this paper. We address these challenges by a) developing a new loss function that has an inbuilt threshold to differentiate between random negative examples, impressed but not purchased examples, and positive examples (purchased items), b) using average pooling in conjunction with n-grams to capture short-range linguistic patterns, c) using hashing to handle out of vocabulary tokens, and d) using a model parallel training architecture to scale across 8 GPUs. We present compelling offline results that demonstrate at least 4.7% improvement in Recall@100 and 14.5% improvement in mean average precision (MAP) over baseline state-of-the-art semantic search methods using the same tokenization method. Moreover, we present results and discuss learnings from online A/B tests which demonstrate the efficacy of our method.
Compressing Gradient Optimizers via Count-Sketches
Feb 26, 2019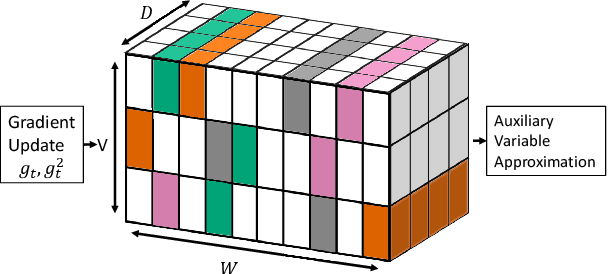

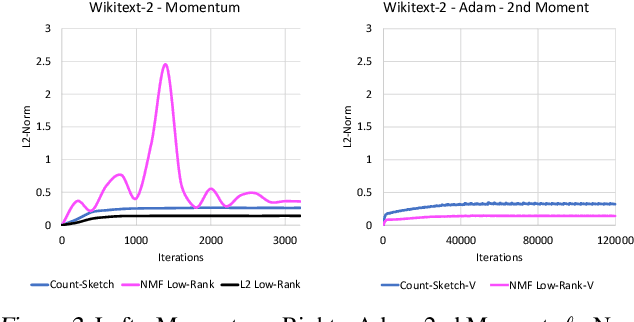
Many popular first-order optimization methods (e.g., Momentum, AdaGrad, Adam) accelerate the convergence rate of deep learning models. However, these algorithms require auxiliary parameters, which cost additional memory proportional to the number of parameters in the model. The problem is becoming more severe as deep learning models continue to grow larger in order to learn from complex, large-scale datasets. Our proposed solution is to maintain a linear sketch to compress the auxiliary variables. We demonstrate that our technique has the same performance as the full-sized baseline, while using significantly less space for the auxiliary variables. Theoretically, we prove that count-sketch optimization maintains the SGD convergence rate, while gracefully reducing memory usage for large-models. On the large-scale 1-Billion Word dataset, we save 25% of the memory used during training (8.6 GB instead of 11.7 GB) by compressing the Adam optimizer in the Embedding and Softmax layers with negligible accuracy and performance loss. For an Amazon extreme classification task with over 49.5 million classes, we also reduce the training time by 38%, by increasing the mini-batch size 3.5x using our count-sketch optimizer.
Adaptive, Personalized Diversity for Visual Discovery
Oct 02, 2018

Search queries are appropriate when users have explicit intent, but they perform poorly when the intent is difficult to express or if the user is simply looking to be inspired. Visual browsing systems allow e-commerce platforms to address these scenarios while offering the user an engaging shopping experience. Here we explore extensions in the direction of adaptive personalization and item diversification within Stream, a new form of visual browsing and discovery by Amazon. Our system presents the user with a diverse set of interesting items while adapting to user interactions. Our solution consists of three components (1) a Bayesian regression model for scoring the relevance of items while leveraging uncertainty, (2) a submodular diversification framework that re-ranks the top scoring items based on category, and (3) personalized category preferences learned from the user's behavior. When tested on live traffic, our algorithms show a strong lift in click-through-rate and session duration.
* Best Paper Award