 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Question Answering Models From Synthetic Data
Feb 22, 2020
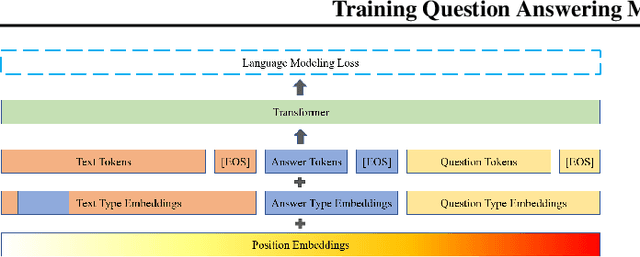
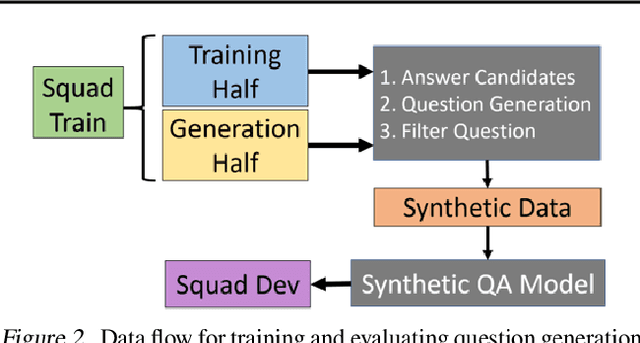
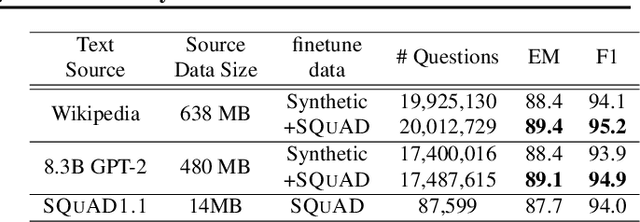
Question and answer generation is a data augmentation method that aims to improve question answering (QA) models given the limited amount of human labeled data. However, a considerable gap remains between synthetic and human-generated question-answer pairs. This work aims to narrow this gap by taking advantage of large language models and explores several factors such as model size, quality of pretrained models, scale of data synthesized, and algorithmic choices. On the SQuAD1.1 question answering task, we achieve higher accuracy using solely synthetic questions and answers than when using the SQuAD1.1 training set questions alone. Removing access to real Wikipedia data, we synthesize questions and answers from a synthetic corpus generated by an 8.3 billion parameter GPT-2 model. With no access to human supervision and only access to other models, we are able to train state of the art question answering networks on entirely model-generated data that achieve 88.4 Exact Match (EM) and 93.9 F1 score on the SQuAD1.1 dev set. We further apply our methodology to SQuAD2.0 and show a 2.8 absolute gain on EM score compared to prior work using synthetic data.
Compressing Gradient Optimizers via Count-Sketches
Feb 26, 2019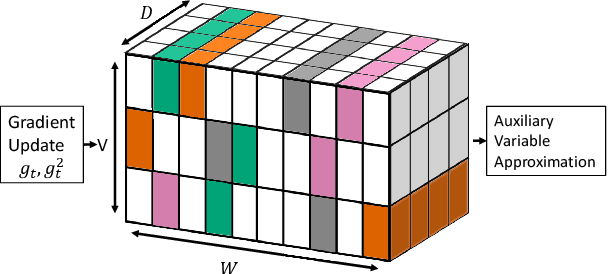

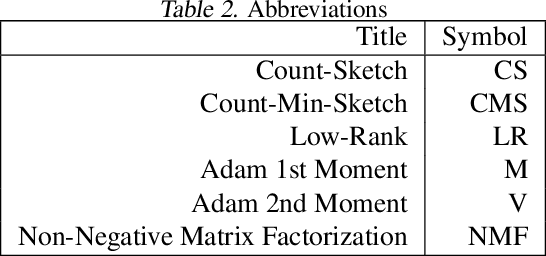
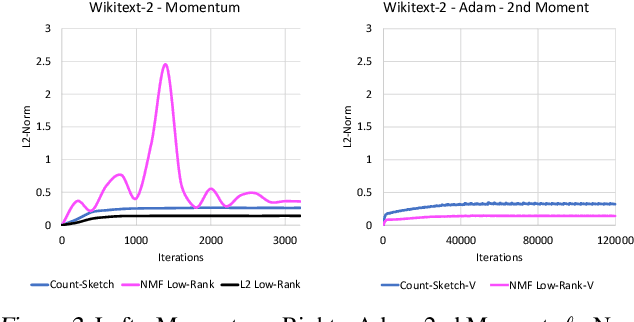
Many popular first-order optimization methods (e.g., Momentum, AdaGrad, Adam) accelerate the convergence rate of deep learning models. However, these algorithms require auxiliary parameters, which cost additional memory proportional to the number of parameters in the model. The problem is becoming more severe as deep learning models continue to grow larger in order to learn from complex, large-scale datasets. Our proposed solution is to maintain a linear sketch to compress the auxiliary variables. We demonstrate that our technique has the same performance as the full-sized baseline, while using significantly less space for the auxiliary variables. Theoretically, we prove that count-sketch optimization maintains the SGD convergence rate, while gracefully reducing memory usage for large-models. On the large-scale 1-Billion Word dataset, we save 25% of the memory used during training (8.6 GB instead of 11.7 GB) by compressing the Adam optimizer in the Embedding and Softmax layers with negligible accuracy and performance loss. For an Amazon extreme classification task with over 49.5 million classes, we also reduce the training time by 38%, by increasing the mini-batch size 3.5x using our count-sketch optimizer.
MISSION: Ultra Large-Scale Feature Selection using Count-Sketches
Jun 12, 2018



Feature selection is an important challenge in machine learning. It plays a crucial role in the explainability of machine-driven decisions that are rapidly permeating throughout modern society. Unfortunately, the explosion in the size and dimensionality of real-world datasets poses a severe challenge to standard feature selection algorithms. Today, it is not uncommon for datasets to have billions of dimensions. At such scale, even storing the feature vector is impossible, causing most existing feature selection methods to fail. Workarounds like feature hashing, a standard approach to large-scale machine learning, helps with the computational feasibility, but at the cost of losing the interpretability of features. In this paper, we present MISSION, a novel framework for ultra large-scale feature selection that performs stochastic gradient descent while maintaining an efficient representation of the features in memory using a Count-Sketch data structure. MISSION retains the simplicity of feature hashing without sacrificing the interpretability of the features while using only O(log^2(p)) working memory. We demonstrate that MISSION accurately and efficiently performs feature selection on real-world, large-scale datasets with billions of dimensions.
A New Unbiased and Efficient Class of LSH-Based Samplers and Estimators for Partition Function Computation in Log-Linear Models
Mar 15, 2017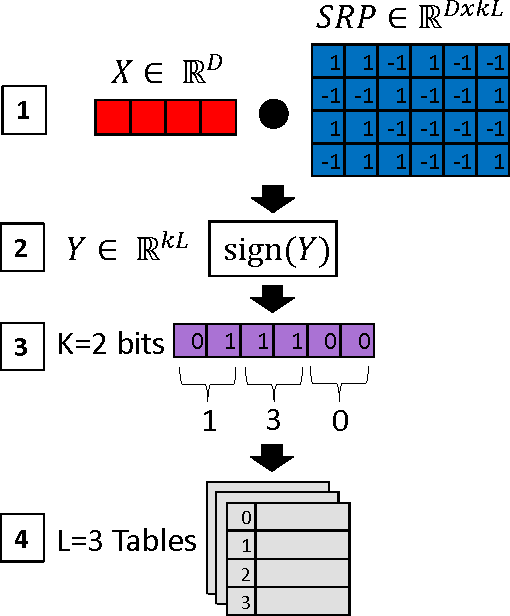
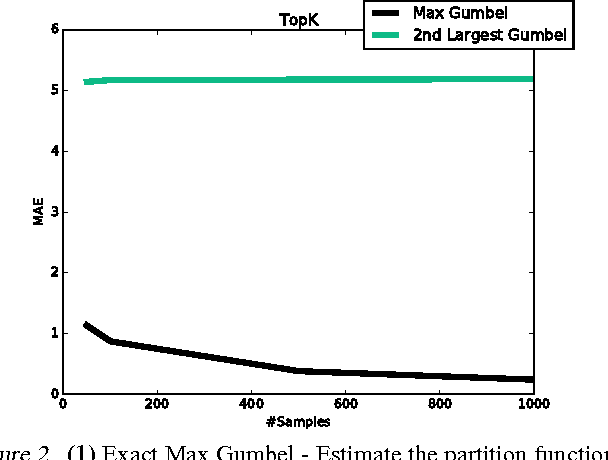

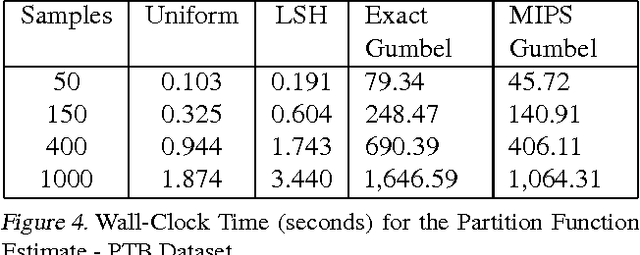
Log-linear models are arguably the most successful class of graphical models for large-scale applications because of their simplicity and tractability. Learning and inference with these models require calculating the partition function, which is a major bottleneck and intractable for large state spaces. Importance Sampling (IS) and MCMC-based approaches are lucrative. However, the condition of having a "good" proposal distribution is often not satisfied in practice. In this paper, we add a new dimension to efficient estimation via sampling. We propose a new sampling scheme and an unbiased estimator that estimates the partition function accurately in sub-linear time. Our samples are generated in near-constant time using locality sensitive hashing (LSH), and so are correlated and unnormalized. We demonstrate the effectiveness of our proposed approach by comparing the accuracy and speed of estimating the partition function against other state-of-the-art estimation techniques including IS and the efficient variant of Gumbel-Max sampling. With our efficient sampling scheme, we accurately train real-world language models using only 1-2% of computations.
Scalable and Sustainable Deep Learning via Randomized Hashing
Dec 05, 2016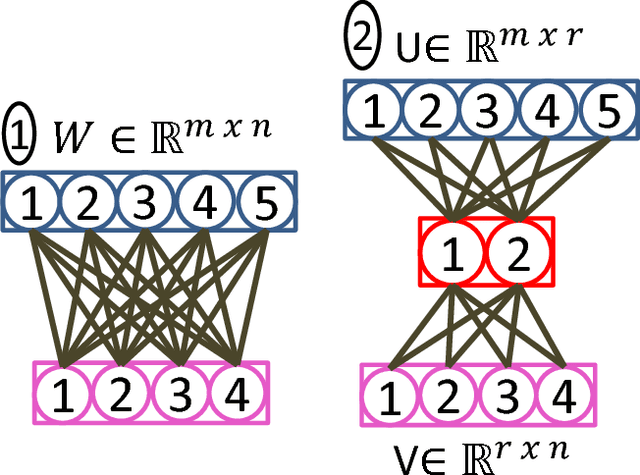


Current deep learning architectures are growing larger in order to learn from complex datasets. These architectures require giant matrix multiplication operations to train millions of parameters. Conversely, there is another growing trend to bring deep learning to low-power, embedded devices. The matrix operations, associated with both training and testing of deep networks, are very expensive from a computational and energy standpoint. We present a novel hashing based technique to drastically reduce the amount of computation needed to train and test deep networks. Our approach combines recent ideas from adaptive dropouts and randomized hashing for maximum inner product search to select the nodes with the highest activation efficiently. Our new algorithm for deep learning reduces the overall computational cost of forward and back-propagation by operating on significantly fewer (sparse) nodes. As a consequence, our algorithm uses only 5% of the total multiplications, while keeping on average within 1% of the accuracy of the original model. A unique property of the proposed hashing based back-propagation is that the updates are always sparse. Due to the sparse gradient updates, our algorithm is ideally suited for asynchronous and parallel training leading to near linear speedup with increasing number of cores. We demonstrate the scalability and sustainability (energy efficiency) of our proposed algorithm via rigorous experimental evaluations on several real datasets.