 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePassive Detection in Multi-Static ISAC Systems: Performance Analysis and Joint Beamforming Optimization
Jun 08, 2025This paper investigates the passive detection problem in multi-static integrated sensing and communication (ISAC) systems, where multiple sensing receivers (SRs) jointly detect a target using random unknown communication signals transmitted by a collaborative base station. Unlike traditional active detection, the considered passive detection does not require complete prior knowledge of the transmitted communication signals at each SR. First, we derive a generalized likelihood ratio test detector and conduct an asymptotic analysis of the detection statistic under the large-sample regime. We examine how the signal-to-noise ratios (SNRs) of the target paths and direct paths influence the detection performance. Then, we propose two joint transmit beamforming designs based on the analyses. In the first design, the asymptotic detection probability is maximized while satisfying the signal-to-interference-plus-noise ratio requirement for each communication user under the total transmit power constraint. Given the non-convex nature of the problem, we develop an alternating optimization algorithm based on the quadratic transform and semi-definite relaxation. The second design adopts a heuristic approach that aims to maximize the target energy, subject to a minimum SNR threshold on the direct path, and offers lower computational complexity. Numerical results validate the asymptotic analysis and demonstrate the superiority of the proposed beamforming designs in balancing passive detection performance and communication quality. This work highlights the promise of target detection using unknown communication data signals in multi-static ISAC systems.
Deep Learning-Based Extended Target Tracking in ISAC Systems
Apr 01, 2025In this paper, we explore the feasibility of using communication signals for extended target (ET) tracking in an integrated sensing and communication (ISAC) system. The ET is characterized by its center range, azimuth, orientation, and contour shape, for which conventional scatterer-based tracking algorithms are hardly feasible due to the limited scatterer resolution in ISAC. To address this challenge, we propose ISACTrackNet, a deep learning-based tracking model that directly estimates ET kinematic and contour parameters from noisy received echoes. The model consists of three modules: Denoising module for clutter and self-interference suppression, Encoder module for instantaneous state estimation, and KalmanNet module for prediction refinement within a constant-velocity state-space model. Simulation results show that ISACTrackNet achieves near-optimal accuracy in position and angle estimation compared to radar-based tracking methods, even under limited measurement resolution and partial occlusions, but orientation and contour shape estimation remains slightly suboptimal. These results clearly demonstrate the feasibility of using communication-only signals for reliable ET tracking.
Cramér-Rao Bound Analysis and Beamforming Design for Integrated Sensing and Communication with Extended Targets
Jun 04, 2024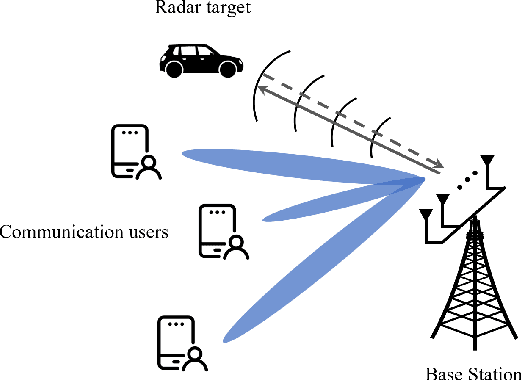



This paper studies an integrated sensing and communication (ISAC) system, where a multi-antenna base station transmits beamformed signals for joint downlink multi-user communication and radar sensing of an extended target (ET). By considering echo signals as reflections from valid elements on the ET contour, a set of novel Cram\'er-Rao bounds (CRBs) is derived for parameter estimation of the ET, including central range, direction, and orientation. The ISAC transmit beamforming design is then formulated as an optimization problem, aiming to minimize the CRB associated with radar sensing, while satisfying a minimum signal-to-interference-pulse-noise ratio requirement for each communication user, along with a 3-dB beam coverage constraint tailored for the ET. To solve this non-convex problem, we utilize semidefinite relaxation (SDR) and propose a rank-one solution extraction scheme for non-tight relaxation circumstances. To reduce the computation complexity, we further employ an efficient zero-forcing (ZF) based beamforming design, where the sensing task is performed in the null space of communication channels. Numerical results validate the effectiveness of the obtained CRB, revealing the diverse features of CRB for differently shaped ETs. The proposed SDR beamforming design outperforms benchmark designs with lower estimation error and CRB, while the ZF beamforming design greatly improves computation efficiency with minor sensing performance loss.
Beamforming Design for Integrated Sensing and Communication with Extended Target
Dec 17, 2023This paper studies transmit beamforming design in an integrated sensing and communication (ISAC) system, where a base station sends symbols to perform downlink multi-user communication and sense an extended target simultaneously. We first model the extended target contour with truncated Fourier series. By considering echo signals as reflections from the valid elements on the target contour, a novel Cram\'er-Rao bound (CRB) on the direction estimation of extended target is derived. We then formulate the transmit beamforming design as an optimization problem by minimizing the CRB of radar sensing, and satisfying a minimum signal-to-interference-plus-noise ratio requirement for each communication user, as well as a 3-dB beam coverage requirement tailored for the extended sensing target under a total transmit power constraint. In view of the non-convexity of the above problem, we employ semidefinite relaxation (SDR) technique for convex relaxation, followed by a rank-one extraction scheme for non-tight relaxation circumstances. Numerical results show that the proposed SDR beamforming scheme outperforms benchmark beampattern design methods with lower CRBs for the circumstances considered.
ParChain: A Framework for Parallel Hierarchical Agglomerative Clustering using Nearest-Neighbor Chain
Jun 08, 2021
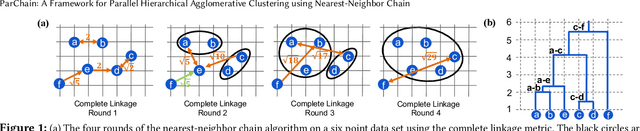
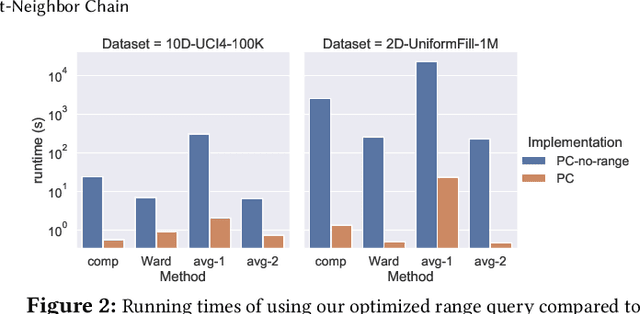
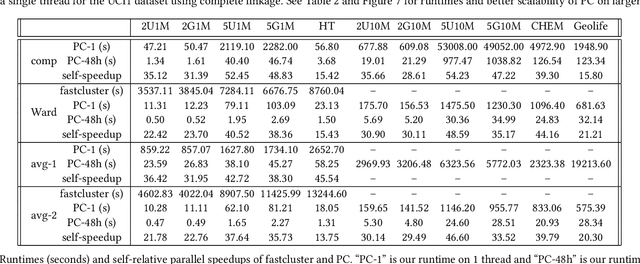
This paper studies the hierarchical clustering problem, where the goal is to produce a dendrogram that represents clusters at varying scales of a data set. We propose the ParChain framework for designing parallel hierarchical agglomerative clustering (HAC) algorithms, and using the framework we obtain novel parallel algorithms for the complete linkage, average linkage, and Ward's linkage criteria. Compared to most previous parallel HAC algorithms, which require quadratic memory, our new algorithms require only linear memory, and are scalable to large data sets. ParChain is based on our parallelization of the nearest-neighbor chain algorithm, and enables multiple clusters to be merged on every round. We introduce two key optimizations that are critical for efficiency: a range query optimization that reduces the number of distance computations required when finding nearest neighbors of clusters, and a caching optimization that stores a subset of previously computed distances, which are likely to be reused. Experimentally, we show that our highly-optimized implementations using 48 cores with two-way hyper-threading achieve 5.8--110.1x speedup over state-of-the-art parallel HAC algorithms and achieve 13.75--54.23x self-relative speedup. Compared to state-of-the-art algorithms, our algorithms require up to 237.3x less space. Our algorithms are able to scale to data set sizes with tens of millions of points, which existing algorithms are not able to handle.
Fast Parallel Algorithms for Euclidean Minimum Spanning Tree and Hierarchical Spatial Clustering
Apr 02, 2021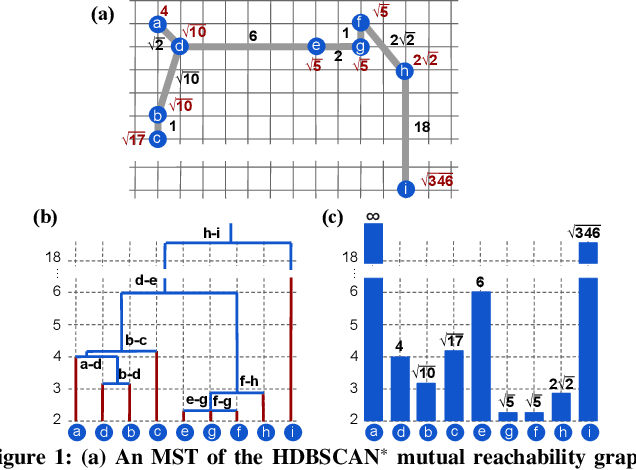

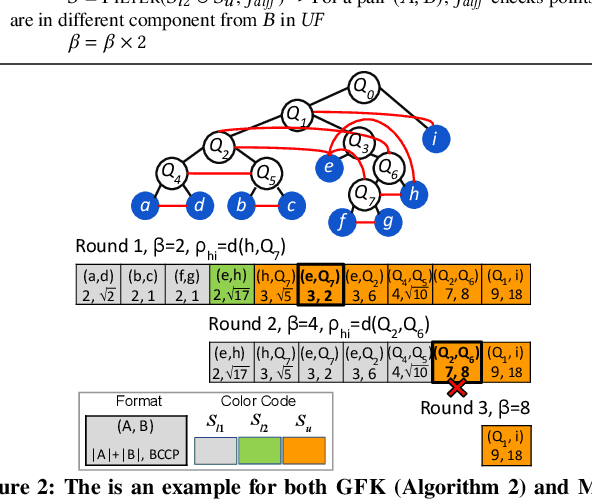
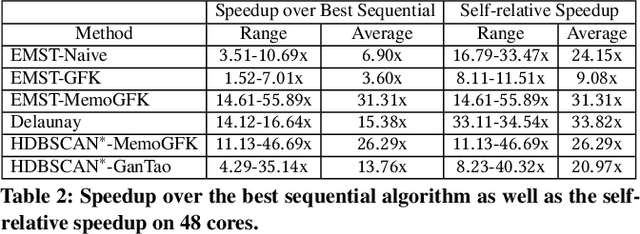
This paper presents new parallel algorithms for generating Euclidean minimum spanning trees and spatial clustering hierarchies (known as HDBSCAN$^*$). Our approach is based on generating a well-separated pair decomposition followed by using Kruskal's minimum spanning tree algorithm and bichromatic closest pair computations. We introduce a new notion of well-separation to reduce the work and space of our algorithm for HDBSCAN$^*$. We also present a parallel approximate algorithm for OPTICS based on a recent sequential algorithm by Gan and Tao. Finally, we give a new parallel divide-and-conquer algorithm for computing the dendrogram and reachability plots, which are used in visualizing clusters of different scale that arise for both EMST and HDBSCAN$^*$. We show that our algorithms are theoretically efficient: they have work (number of operations) matching their sequential counterparts, and polylogarithmic depth (parallel time). We implement our algorithms and propose a memory optimization that requires only a subset of well-separated pairs to be computed and materialized, leading to savings in both space (up to 10x) and time (up to 8x). Our experiments on large real-world and synthetic data sets using a 48-core machine show that our fastest algorithms outperform the best serial algorithms for the problems by 11.13--55.89x, and existing parallel algorithms by at least an order of magnitude.
Theoretically-Efficient and Practical Parallel DBSCAN
Dec 12, 2019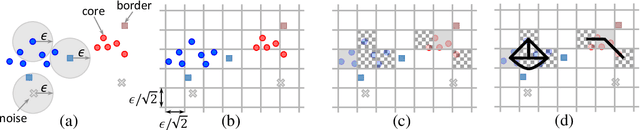
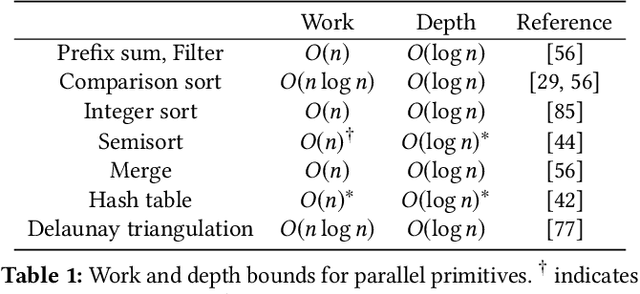

The DBSCAN method for spatial clustering has received significant attention due to its applicability in a variety of data analysis tasks. There are fast sequential algorithms for DBSCAN in Euclidean space that take $O(n\log n)$ work for two dimensions, sub-quadratic work for three or more dimensions, and can be computed approximately in linear work for any constant number of dimensions. However, existing parallel DBSCAN algorithms require quadratic work in the worst case, making them inefficient for large datasets. This paper bridges the gap between theory and practice of parallel DBSCAN by presenting new parallel algorithms for Euclidean exact DBSCAN and approximate DBSCAN that match the work bounds of their sequential counterparts, and are highly parallel (polylogarithmic depth). We present implementations of our algorithms along with optimizations that improve their practical performance. We perform a comprehensive experimental evaluation of our algorithms on a variety of datasets and parameter settings. Our experiments on a 36-core machine with hyper-threading show that we outperform existing parallel DBSCAN implementations by up to several orders of magnitude, and achieve speedups by up to 33x over the best sequential algorithms.
Extreme Classification in Log Memory using Count-Min Sketch: A Case Study of Amazon Search with 50M Products
Oct 28, 2019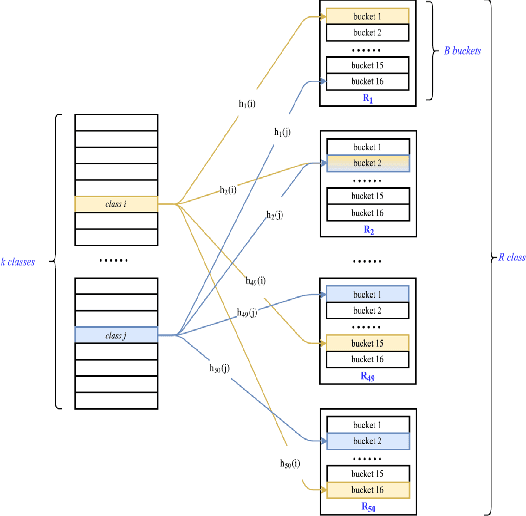

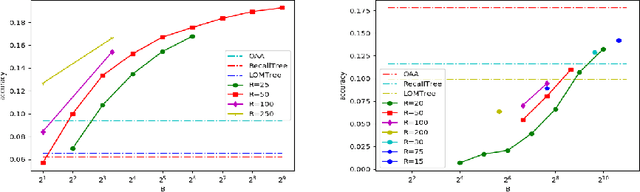
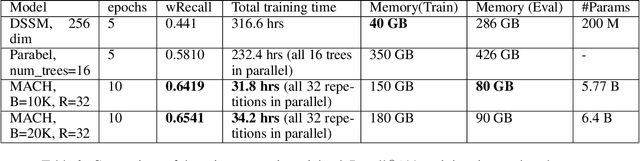
In the last decade, it has been shown that many hard AI tasks, especially in NLP, can be naturally modeled as extreme classification problems leading to improved precision. However, such models are prohibitively expensive to train due to the memory blow-up in the last layer. For example, a reasonable softmax layer for the dataset of interest in this paper can easily reach well beyond 100 billion parameters (>400 GB memory). To alleviate this problem, we present Merged-Average Classifiers via Hashing (MACH), a generic K-classification algorithm where memory provably scales at O(logK) without any strong assumption on the classes. MACH is subtly a count-min sketch structure in disguise, which uses universal hashing to reduce classification with a large number of classes to few embarrassingly parallel and independent classification tasks with a small (constant) number of classes. MACH naturally provides a technique for zero communication model parallelism. We experiment with 6 datasets; some multiclass and some multilabel, and show consistent improvement over respective state-of-the-art baselines. In particular, we train an end-to-end deep classifier on a private product search dataset sampled from Amazon Search Engine with 70 million queries and 49.46 million products. MACH outperforms, by a significant margin,the state-of-the-art extreme classification models deployed on commercial search engines: Parabel and dense embedding models. Our largest model has 6.4 billion parameters and trains in less than 35 hours on a single p3.16x machine. Our training times are 7-10x faster, and our memory footprints are 2-4x smaller than the best baselines. This training time is also significantly lower than the one reported by Google's mixture of experts (MoE) language model on a comparable model size and hardware.
Extreme Classification in Log Memory
Oct 09, 2018
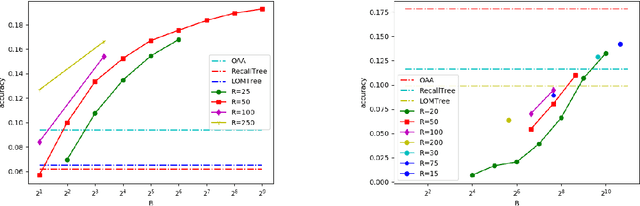
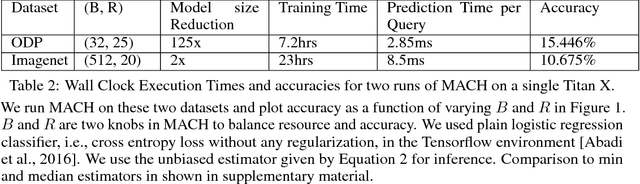
We present Merged-Averaged Classifiers via Hashing (MACH) for K-classification with ultra-large values of K. Compared to traditional one-vs-all classifiers that require O(Kd) memory and inference cost, MACH only need O(d log K) (d is dimensionality )memory while only requiring O(K log K + d log K) operation for inference. MACH is a generic K-classification algorithm, with provably theoretical guarantees, which requires O(log K) memory without any assumption on the relationship between classes. MACH uses universal hashing to reduce classification with a large number of classes to few independent classification tasks with small (constant) number of classes. We provide theoretical quantification of discriminability-memory tradeoff. With MACH we can train ODP dataset with 100,000 classes and 400,000 features on a single Titan X GPU, with the classification accuracy of 19.28%, which is the best-reported accuracy on this dataset. Before this work, the best performing baseline is a one-vs-all classifier that requires 40 billion parameters (160 GB model size) and achieves 9% accuracy. In contrast, MACH can achieve 9% accuracy with 480x reduction in the model size (of mere 0.3GB). With MACH, we also demonstrate complete training of fine-grained imagenet dataset (compressed size 104GB), with 21,000 classes, on a single GPU. To the best of our knowledge, this is the first work to demonstrate complete training of these extreme-class datasets on a single Titan X.