 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe ParClusterers Benchmark Suite (PCBS): A Fine-Grained Analysis of Scalable Graph Clustering
Nov 15, 2024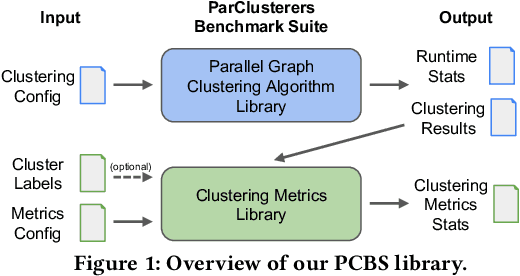
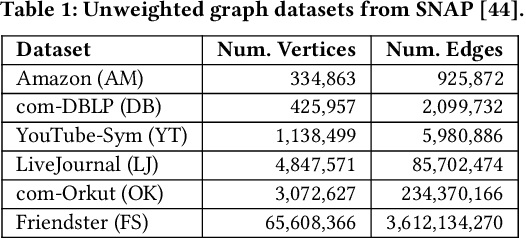
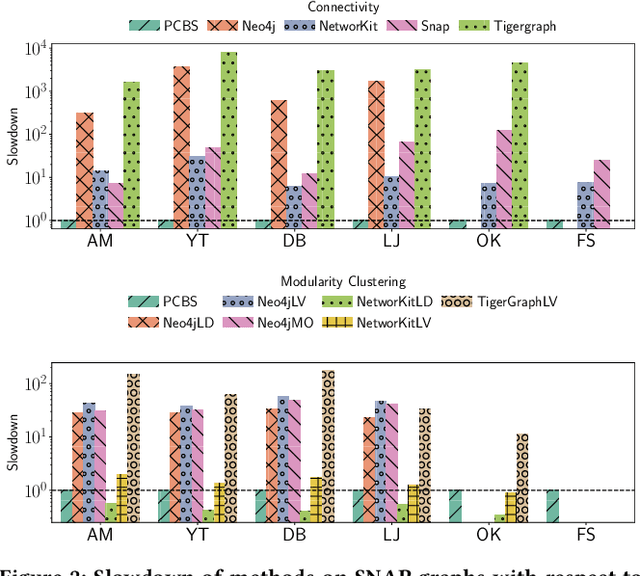
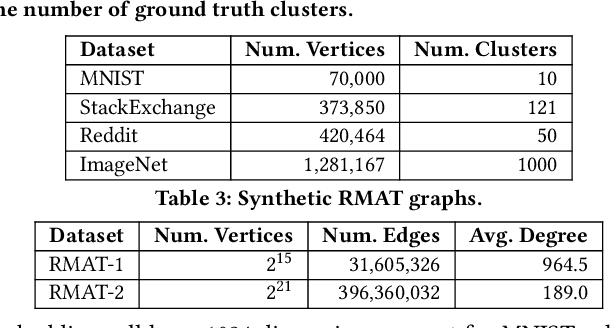
We introduce the ParClusterers Benchmark Suite (PCBS) -- a collection of highly scalable parallel graph clustering algorithms and benchmarking tools that streamline comparing different graph clustering algorithms and implementations. The benchmark includes clustering algorithms that target a wide range of modern clustering use cases, including community detection, classification, and dense subgraph mining. The benchmark toolkit makes it easy to run and evaluate multiple instances of different clustering algorithms, which can be useful for fine-tuning the performance of clustering on a given task, and for comparing different clustering algorithms based on different metrics of interest, including clustering quality and running time. Using PCBS, we evaluate a broad collection of real-world graph clustering datasets. Somewhat surprisingly, we find that the best quality results are obtained by algorithms that not included in many popular graph clustering toolkits. The PCBS provides a standardized way to evaluate and judge the quality-performance tradeoffs of the active research area of scalable graph clustering algorithms. We believe it will help enable fair, accurate, and nuanced evaluation of graph clustering algorithms in the future.
Approximate Nearest Neighbor Search with Window Filters
Feb 01, 2024
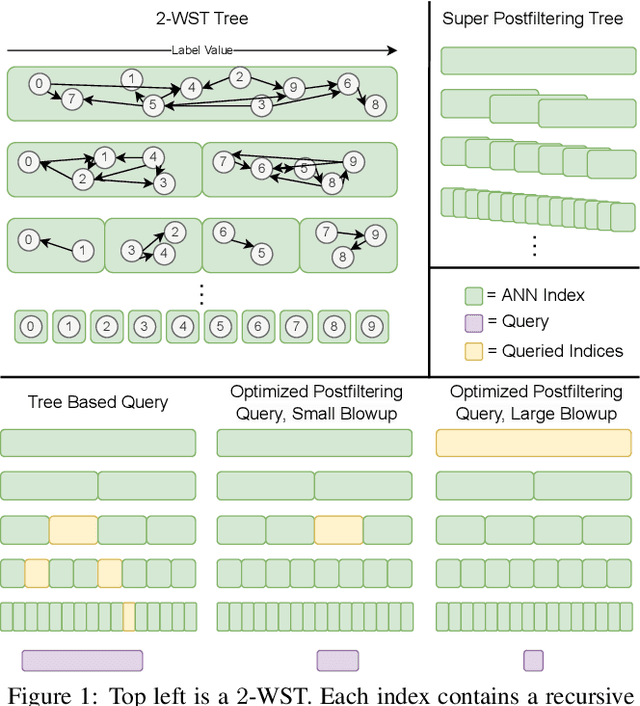
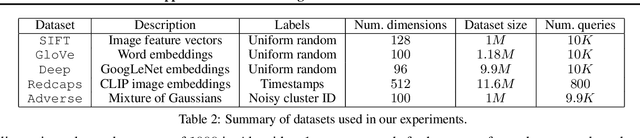
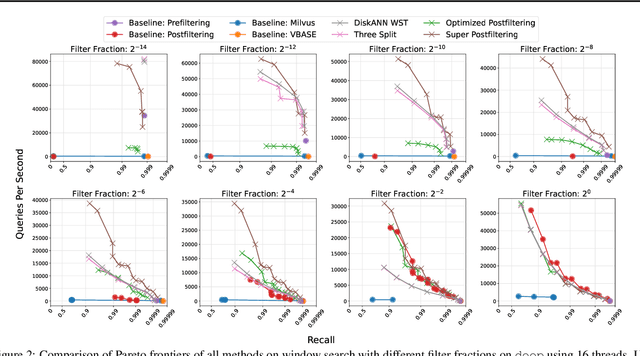
We define and investigate the problem of $\textit{c-approximate window search}$: approximate nearest neighbor search where each point in the dataset has a numeric label, and the goal is to find nearest neighbors to queries within arbitrary label ranges. Many semantic search problems, such as image and document search with timestamp filters, or product search with cost filters, are natural examples of this problem. We propose and theoretically analyze a modular tree-based framework for transforming an index that solves the traditional c-approximate nearest neighbor problem into a data structure that solves window search. On standard nearest neighbor benchmark datasets equipped with random label values, adversarially constructed embeddings, and image search embeddings with real timestamps, we obtain up to a $75\times$ speedup over existing solutions at the same level of recall.
PECANN: Parallel Efficient Clustering with Graph-Based Approximate Nearest Neighbor Search
Dec 13, 2023



This paper studies density-based clustering of point sets. These methods use dense regions of points to detect clusters of arbitrary shapes. In particular, we study variants of density peaks clustering, a popular type of algorithm that has been shown to work well in practice. Our goal is to cluster large high-dimensional datasets, which are prevalent in practice. Prior solutions are either sequential, and cannot scale to large data, or are specialized for low-dimensional data. This paper unifies the different variants of density peaks clustering into a single framework, PECANN, by abstracting out several key steps common to this class of algorithms. One such key step is to find nearest neighbors that satisfy a predicate function, and one of the main contributions of this paper is an efficient way to do this predicate search using graph-based approximate nearest neighbor search (ANNS). To provide ample parallelism, we propose a doubling search technique that enables points to find an approximate nearest neighbor satisfying the predicate in a small number of rounds. Our technique can be applied to many existing graph-based ANNS algorithms, which can all be plugged into PECANN. We implement five clustering algorithms with PECANN and evaluate them on synthetic and real-world datasets with up to 1.28 million points and up to 1024 dimensions on a 30-core machine with two-way hyper-threading. Compared to the state-of-the-art FASTDP algorithm for high-dimensional density peaks clustering, which is sequential, our best algorithm is 45x-734x faster while achieving competitive ARI scores. Compared to the state-of-the-art parallel DPC-based algorithm, which is optimized for low dimensions, we show that PECANN is two orders of magnitude faster. As far as we know, our work is the first to evaluate DPC variants on large high-dimensional real-world image and text embedding datasets.
AuthentiGPT: Detecting Machine-Generated Text via Black-Box Language Models Denoising
Nov 13, 2023



Large language models (LLMs) have opened up enormous opportunities while simultaneously posing ethical dilemmas. One of the major concerns is their ability to create text that closely mimics human writing, which can lead to potential misuse, such as academic misconduct, disinformation, and fraud. To address this problem, we present AuthentiGPT, an efficient classifier that distinguishes between machine-generated and human-written texts. Under the assumption that human-written text resides outside the distribution of machine-generated text, AuthentiGPT leverages a black-box LLM to denoise input text with artificially added noise, and then semantically compares the denoised text with the original to determine if the content is machine-generated. With only one trainable parameter, AuthentiGPT eliminates the need for a large training dataset, watermarking the LLM's output, or computing the log-likelihood. Importantly, the detection capability of AuthentiGPT can be easily adapted to any generative language model. With a 0.918 AUROC score on a domain-specific dataset, AuthentiGPT demonstrates its effectiveness over other commercial algorithms, highlighting its potential for detecting machine-generated text in academic settings.
Dr. LLaMA: Improving Small Language Models on PubMedQA via Generative Data Augmentation
May 17, 2023



Large Language Models (LLMs) have made remarkable strides in natural language processing, but their expanding size poses challenges in terms of computational expense and inefficiency. Conversely, Small Language Models (SLMs) are known for their efficiency but often encounter difficulties in tasks with limited capacity and training data, particularly in domain-specific scenarios. In this paper, we introduce Dr. LLaMA, a method that improves SLMs in the medical domain through generative data augmentation utilizing LLMs. The objective is to develop more efficient and capable models tailored for specialized applications. Our preliminary results on the PubMedQA dataset demonstrate that LLMs effectively refine and diversify existing question-answer pairs, leading to improved performance of a significantly smaller model after fine-tuning. The best SLM surpasses few-shot GPT-4 with under 1.6 billion parameters on the PubMedQA. Our code and generated data are publicly available to facilitate further explorations.
ParChain: A Framework for Parallel Hierarchical Agglomerative Clustering using Nearest-Neighbor Chain
Jun 08, 2021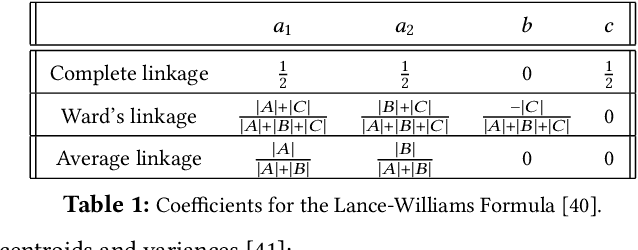
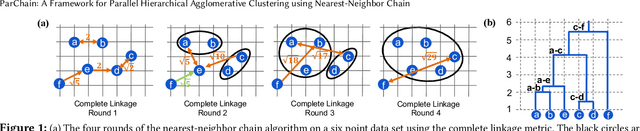
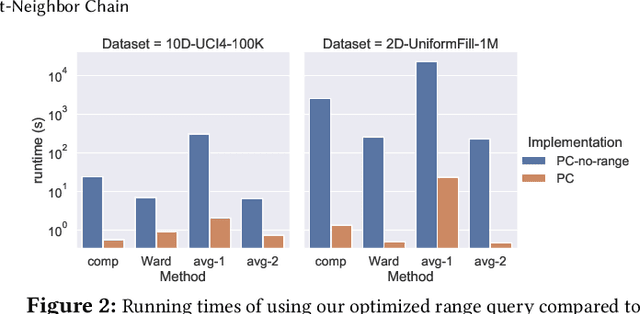
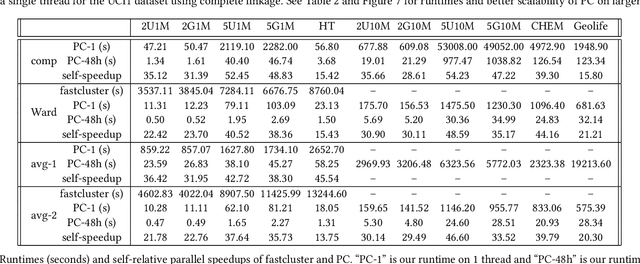
This paper studies the hierarchical clustering problem, where the goal is to produce a dendrogram that represents clusters at varying scales of a data set. We propose the ParChain framework for designing parallel hierarchical agglomerative clustering (HAC) algorithms, and using the framework we obtain novel parallel algorithms for the complete linkage, average linkage, and Ward's linkage criteria. Compared to most previous parallel HAC algorithms, which require quadratic memory, our new algorithms require only linear memory, and are scalable to large data sets. ParChain is based on our parallelization of the nearest-neighbor chain algorithm, and enables multiple clusters to be merged on every round. We introduce two key optimizations that are critical for efficiency: a range query optimization that reduces the number of distance computations required when finding nearest neighbors of clusters, and a caching optimization that stores a subset of previously computed distances, which are likely to be reused. Experimentally, we show that our highly-optimized implementations using 48 cores with two-way hyper-threading achieve 5.8--110.1x speedup over state-of-the-art parallel HAC algorithms and achieve 13.75--54.23x self-relative speedup. Compared to state-of-the-art algorithms, our algorithms require up to 237.3x less space. Our algorithms are able to scale to data set sizes with tens of millions of points, which existing algorithms are not able to handle.
Fast Parallel Algorithms for Euclidean Minimum Spanning Tree and Hierarchical Spatial Clustering
Apr 02, 2021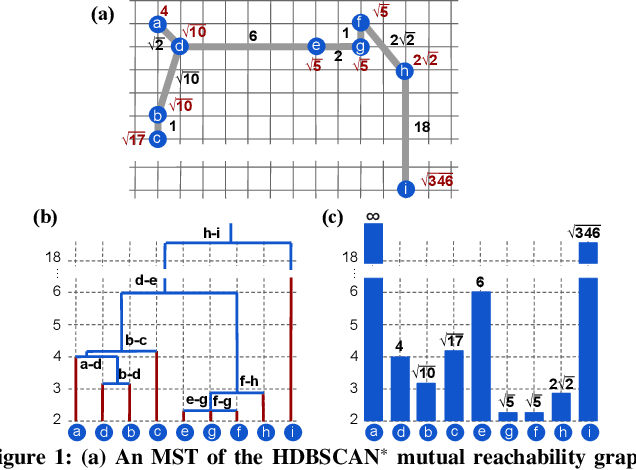

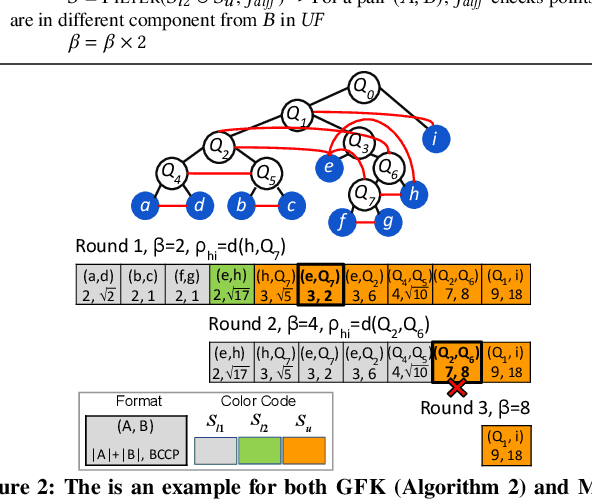
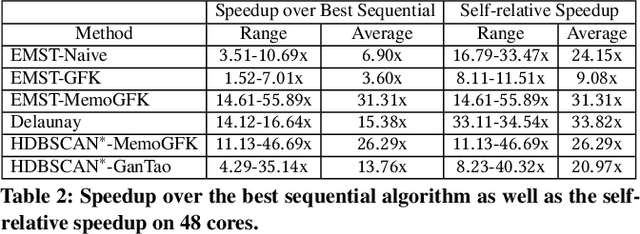
This paper presents new parallel algorithms for generating Euclidean minimum spanning trees and spatial clustering hierarchies (known as HDBSCAN$^*$). Our approach is based on generating a well-separated pair decomposition followed by using Kruskal's minimum spanning tree algorithm and bichromatic closest pair computations. We introduce a new notion of well-separation to reduce the work and space of our algorithm for HDBSCAN$^*$. We also present a parallel approximate algorithm for OPTICS based on a recent sequential algorithm by Gan and Tao. Finally, we give a new parallel divide-and-conquer algorithm for computing the dendrogram and reachability plots, which are used in visualizing clusters of different scale that arise for both EMST and HDBSCAN$^*$. We show that our algorithms are theoretically efficient: they have work (number of operations) matching their sequential counterparts, and polylogarithmic depth (parallel time). We implement our algorithms and propose a memory optimization that requires only a subset of well-separated pairs to be computed and materialized, leading to savings in both space (up to 10x) and time (up to 8x). Our experiments on large real-world and synthetic data sets using a 48-core machine show that our fastest algorithms outperform the best serial algorithms for the problems by 11.13--55.89x, and existing parallel algorithms by at least an order of magnitude.
Modeling and Analysis of Tagging Networks in Stack Exchange Communities
Feb 06, 2019
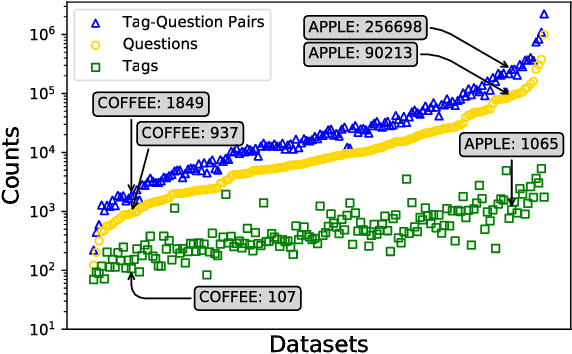
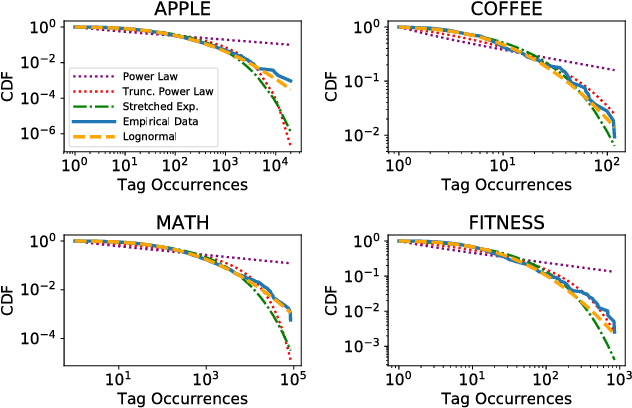
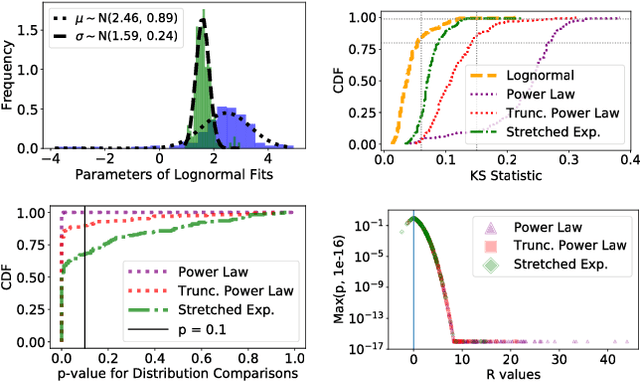
Large Question-and-Answer (Q&A) platforms support diverse knowledge curation on the Web. While researchers have studied user behavior on the platforms in a variety of contexts, there is relatively little insight into important by-products of user behavior that also encode knowledge. Here, we analyze and model the macroscopic structure of tags applied by users to annotate and catalog questions, using a collection of 168 Stack Exchange websites. We find striking similarity in tagging structure across these Stack Exchange communities, even though each community evolves independently (albeit under similar guidelines). Using our empirical findings, we develop a simple generative model that creates random bipartite graphs of tags and questions. Our model accounts for the tag frequency distribution but does not explicitly account for co-tagging correlations. Even under these constraints, we demonstrate empirically and theoretically that our model can reproduce a number of statistical properties of the co-tagging graph that links tags appearing in the same post.