 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChamfer-Linkage for Hierarchical Agglomerative Clustering
Feb 11, 2026Hierarchical Agglomerative Clustering (HAC) is a widely-used clustering method based on repeatedly merging the closest pair of clusters, where inter-cluster distances are determined by a linkage function. Unlike many clustering methods, HAC does not optimize a single explicit global objective; clustering quality is therefore primarily evaluated empirically, and the choice of linkage function plays a crucial role in practice. However, popular classical linkages, such as single-linkage, average-linkage and Ward's method show high variability across real-world datasets and do not consistently produce high-quality clusterings in practice. In this paper, we propose \emph{Chamfer-linkage}, a novel linkage function that measures the distance between clusters using the Chamfer distance, a popular notion of distance between point-clouds in machine learning and computer vision. We argue that Chamfer-linkage satisfies desirable concept representation properties that other popular measures struggle to satisfy. Theoretically, we show that Chamfer-linkage HAC can be implemented in $O(n^2)$ time, matching the efficiency of classical linkage functions. Experimentally, we find that Chamfer-linkage consistently yields higher-quality clusterings than classical linkages such as average-linkage and Ward's method across a diverse collection of datasets. Our results establish Chamfer-linkage as a practical drop-in replacement for classical linkage functions, broadening the toolkit for hierarchical clustering in both theory and practice.
JAG: Joint Attribute Graphs for Filtered Nearest Neighbor Search
Feb 10, 2026Despite filtered nearest neighbor search being a fundamental task in modern vector search systems, the performance of existing algorithms is highly sensitive to query selectivity and filter type. In particular, existing solutions excel either at specific filter categories (e.g., label equality) or within narrow selectivity bands (e.g., pre-filtering for low selectivity) and are therefore a poor fit for practical deployments that demand generalization to new filter types and unknown query selectivities. In this paper, we propose JAG (Joint Attribute Graphs), a graph-based algorithm designed to deliver robust performance across the entire selectivity spectrum and support diverse filter types. Our key innovation is the introduction of attribute and filter distances, which transform binary filter constraints into continuous navigational guidance. By constructing a proximity graph that jointly optimizes for both vector similarity and attribute proximity, JAG prevents navigational dead-ends and allows JAG to consistently outperform prior graph-based filtered nearest neighbor search methods. Our experimental results across five datasets and four filter types (Label, Range, Subset, Boolean) demonstrate that JAG significantly outperforms existing state-of-the-art baselines in both throughput and recall robustness.
Efficiently Constructing Sparse Navigable Graphs
Jul 17, 2025



Graph-based nearest neighbor search methods have seen a surge of popularity in recent years, offering state-of-the-art performance across a wide variety of applications. Central to these methods is the task of constructing a sparse navigable search graph for a given dataset endowed with a distance function. Unfortunately, doing so is computationally expensive, so heuristics are universally used in practice. In this work, we initiate the study of fast algorithms with provable guarantees for search graph construction. For a dataset with $n$ data points, the problem of constructing an optimally sparse navigable graph can be framed as $n$ separate but highly correlated minimum set cover instances. This yields a naive $O(n^3)$ time greedy algorithm that returns a navigable graph whose sparsity is at most $O(\log n)$ higher than optimal. We improve significantly on this baseline, taking advantage of correlation between the set cover instances to leverage techniques from streaming and sublinear-time set cover algorithms. Combined with problem-specific pre-processing techniques, we present an $\tilde{O}(n^2)$ time algorithm for constructing an $O(\log n)$-approximate sparsest navigable graph under any distance function. The runtime of our method is optimal up to logarithmic factors under the Strong Exponential Time Hypothesis via a reduction from Monochromatic Closest Pair. Moreover, we prove that, as with general set cover, obtaining better than an $O(\log n)$-approximation is NP-hard, despite the significant additional structure present in the navigable graph problem. Finally, we show that our techniques can also beat cubic time for the closely related and practically important problems of constructing $\alpha$-shortcut reachable and $\tau$-monotonic graphs, which are also used for nearest neighbor search. For such graphs, we obtain $\tilde{O}(n^{2.5})$ time or better algorithms.
The ParClusterers Benchmark Suite (PCBS): A Fine-Grained Analysis of Scalable Graph Clustering
Nov 15, 2024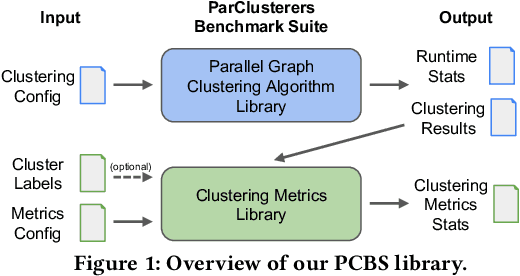
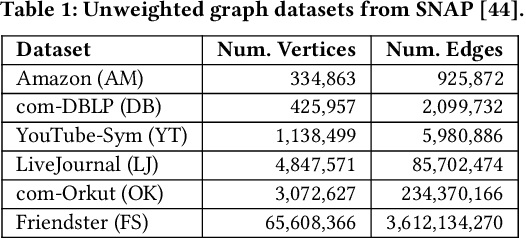
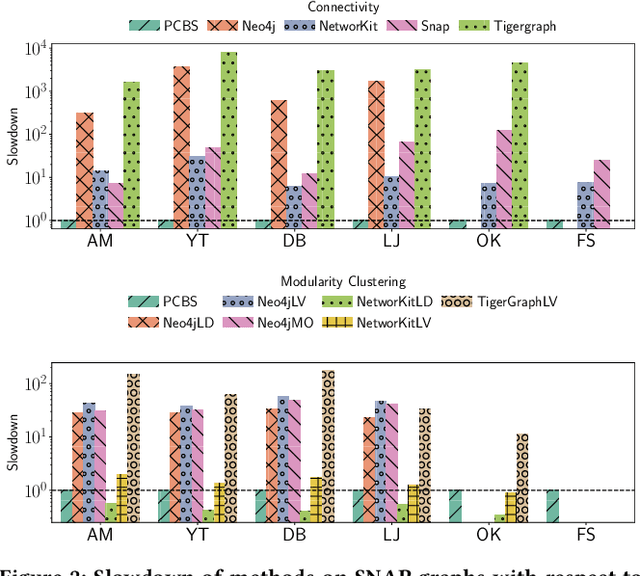
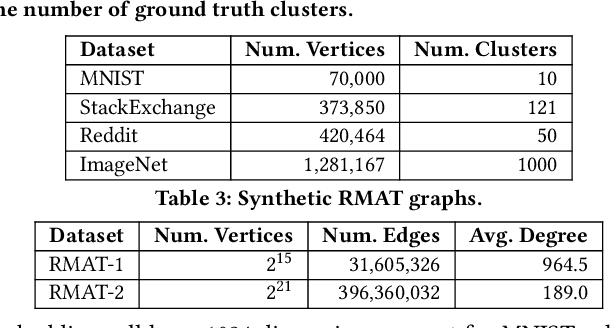
We introduce the ParClusterers Benchmark Suite (PCBS) -- a collection of highly scalable parallel graph clustering algorithms and benchmarking tools that streamline comparing different graph clustering algorithms and implementations. The benchmark includes clustering algorithms that target a wide range of modern clustering use cases, including community detection, classification, and dense subgraph mining. The benchmark toolkit makes it easy to run and evaluate multiple instances of different clustering algorithms, which can be useful for fine-tuning the performance of clustering on a given task, and for comparing different clustering algorithms based on different metrics of interest, including clustering quality and running time. Using PCBS, we evaluate a broad collection of real-world graph clustering datasets. Somewhat surprisingly, we find that the best quality results are obtained by algorithms that not included in many popular graph clustering toolkits. The PCBS provides a standardized way to evaluate and judge the quality-performance tradeoffs of the active research area of scalable graph clustering algorithms. We believe it will help enable fair, accurate, and nuanced evaluation of graph clustering algorithms in the future.
Results of the Big ANN: NeurIPS'23 competition
Sep 25, 2024

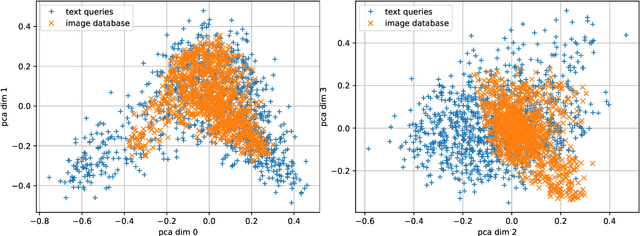

The 2023 Big ANN Challenge, held at NeurIPS 2023, focused on advancing the state-of-the-art in indexing data structures and search algorithms for practical variants of Approximate Nearest Neighbor (ANN) search that reflect the growing complexity and diversity of workloads. Unlike prior challenges that emphasized scaling up classical ANN search ~\cite{DBLP:conf/nips/SimhadriWADBBCH21}, this competition addressed filtered search, out-of-distribution data, sparse and streaming variants of ANNS. Participants developed and submitted innovative solutions that were evaluated on new standard datasets with constrained computational resources. The results showcased significant improvements in search accuracy and efficiency over industry-standard baselines, with notable contributions from both academic and industrial teams. This paper summarizes the competition tracks, datasets, evaluation metrics, and the innovative approaches of the top-performing submissions, providing insights into the current advancements and future directions in the field of approximate nearest neighbor search.
MUVERA: Multi-Vector Retrieval via Fixed Dimensional Encodings
May 29, 2024Neural embedding models have become a fundamental component of modern information retrieval (IR) pipelines. These models produce a single embedding $x \in \mathbb{R}^d$ per data-point, allowing for fast retrieval via highly optimized maximum inner product search (MIPS) algorithms. Recently, beginning with the landmark ColBERT paper, multi-vector models, which produce a set of embedding per data point, have achieved markedly superior performance for IR tasks. Unfortunately, using these models for IR is computationally expensive due to the increased complexity of multi-vector retrieval and scoring. In this paper, we introduce MUVERA (MUlti-VEctor Retrieval Algorithm), a retrieval mechanism which reduces multi-vector similarity search to single-vector similarity search. This enables the usage of off-the-shelf MIPS solvers for multi-vector retrieval. MUVERA asymmetrically generates Fixed Dimensional Encodings (FDEs) of queries and documents, which are vectors whose inner product approximates multi-vector similarity. We prove that FDEs give high-quality $\epsilon$-approximations, thus providing the first single-vector proxy for multi-vector similarity with theoretical guarantees. Empirically, we find that FDEs achieve the same recall as prior state-of-the-art heuristics while retrieving 2-5$\times$ fewer candidates. Compared to prior state of the art implementations, MUVERA achieves consistently good end-to-end recall and latency across a diverse set of the BEIR retrieval datasets, achieving an average of 10$\%$ improved recall with $90\%$ lower latency.
Unleashing Graph Partitioning for Large-Scale Nearest Neighbor Search
Mar 04, 2024

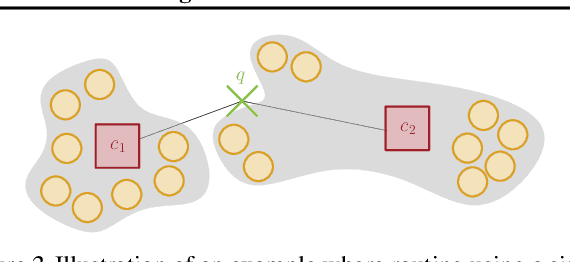
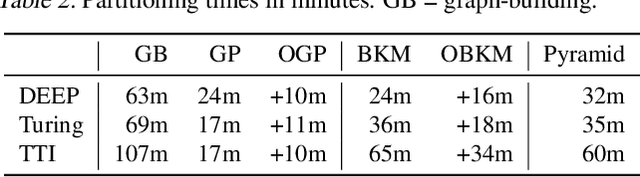
We consider the fundamental problem of decomposing a large-scale approximate nearest neighbor search (ANNS) problem into smaller sub-problems. The goal is to partition the input points into neighborhood-preserving shards, so that the nearest neighbors of any point are contained in only a few shards. When a query arrives, a routing algorithm is used to identify the shards which should be searched for its nearest neighbors. This approach forms the backbone of distributed ANNS, where the dataset is so large that it must be split across multiple machines. In this paper, we design simple and highly efficient routing methods, and prove strong theoretical guarantees on their performance. A crucial characteristic of our routing algorithms is that they are inherently modular, and can be used with any partitioning method. This addresses a key drawback of prior approaches, where the routing algorithms are inextricably linked to their associated partitioning method. In particular, our new routing methods enable the use of balanced graph partitioning, which is a high-quality partitioning method without a naturally associated routing algorithm. Thus, we provide the first methods for routing using balanced graph partitioning that are extremely fast to train, admit low latency, and achieve high recall. We provide a comprehensive evaluation of our full partitioning and routing pipeline on billion-scale datasets, where it outperforms existing scalable partitioning methods by significant margins, achieving up to 2.14x higher QPS at 90% recall$@10$ than the best competitor.
Approximate Nearest Neighbor Search with Window Filters
Feb 01, 2024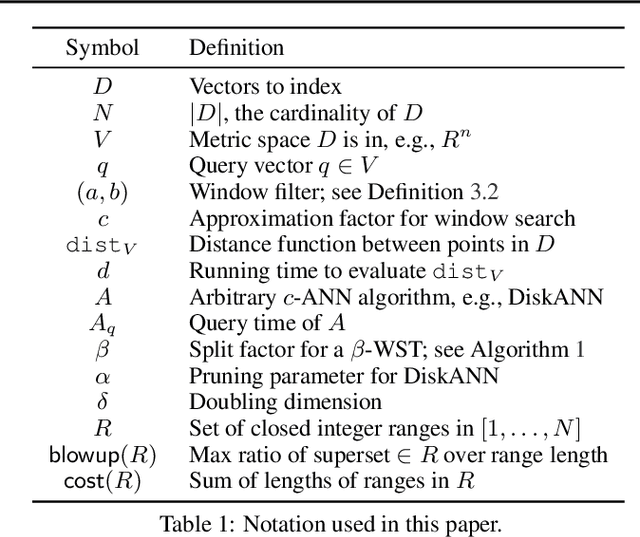
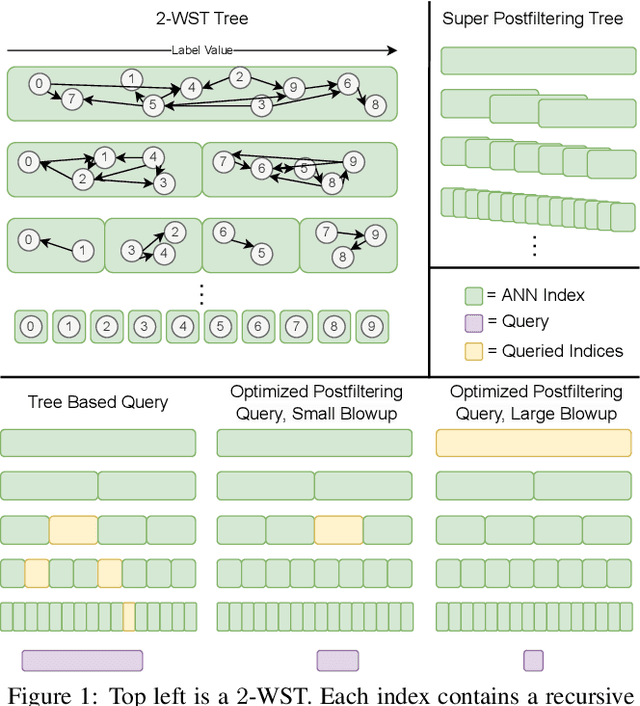
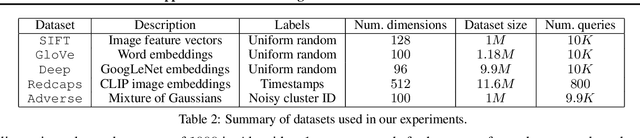
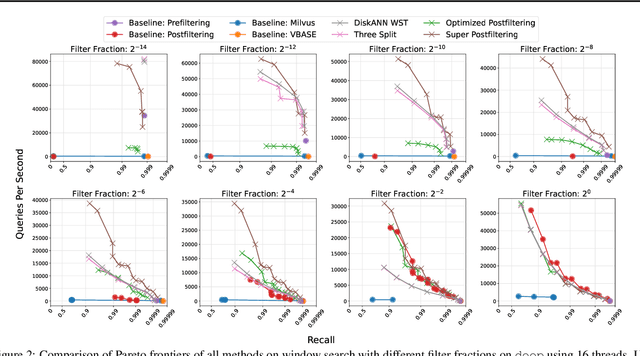
We define and investigate the problem of $\textit{c-approximate window search}$: approximate nearest neighbor search where each point in the dataset has a numeric label, and the goal is to find nearest neighbors to queries within arbitrary label ranges. Many semantic search problems, such as image and document search with timestamp filters, or product search with cost filters, are natural examples of this problem. We propose and theoretically analyze a modular tree-based framework for transforming an index that solves the traditional c-approximate nearest neighbor problem into a data structure that solves window search. On standard nearest neighbor benchmark datasets equipped with random label values, adversarially constructed embeddings, and image search embeddings with real timestamps, we obtain up to a $75\times$ speedup over existing solutions at the same level of recall.
TeraHAC: Hierarchical Agglomerative Clustering of Trillion-Edge Graphs
Aug 07, 2023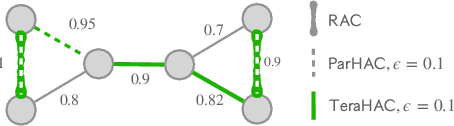
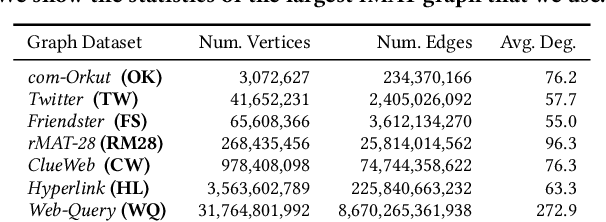
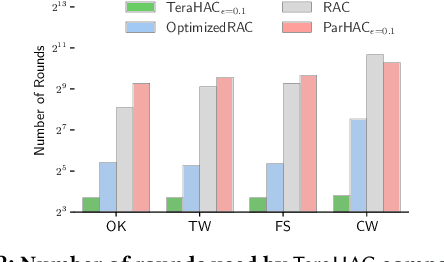
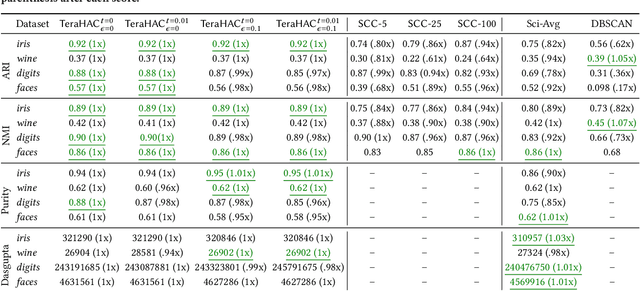
We introduce TeraHAC, a $(1+\epsilon)$-approximate hierarchical agglomerative clustering (HAC) algorithm which scales to trillion-edge graphs. Our algorithm is based on a new approach to computing $(1+\epsilon)$-approximate HAC, which is a novel combination of the nearest-neighbor chain algorithm and the notion of $(1+\epsilon)$-approximate HAC. Our approach allows us to partition the graph among multiple machines and make significant progress in computing the clustering within each partition before any communication with other partitions is needed. We evaluate TeraHAC on a number of real-world and synthetic graphs of up to 8 trillion edges. We show that TeraHAC requires over 100x fewer rounds compared to previously known approaches for computing HAC. It is up to 8.3x faster than SCC, the state-of-the-art distributed algorithm for hierarchical clustering, while achieving 1.16x higher quality. In fact, TeraHAC essentially retains the quality of the celebrated HAC algorithm while significantly improving the running time.
Scaling Graph-Based ANNS Algorithms to Billion-Size Datasets: A Comparative Analysis
May 07, 2023



Algorithms for approximate nearest-neighbor search (ANNS) have been the topic of significant recent interest in the research community. However, evaluations of such algorithms are usually restricted to a small number of datasets with millions or tens of millions of points, whereas real-world applications require algorithms that work on the scale of billions of points. Furthermore, existing evaluations of ANNS algorithms are typically heavily focused on measuring and optimizing for queries-per second (QPS) at a given accuracy, which can be hardware-dependent and ignores important metrics such as build time. In this paper, we propose a set of principled measures for evaluating ANNS algorithms which refocuses on their scalability to billion-size datasets. These measures include ability to be efficiently parallelized, build times, and scaling relationships as dataset size increases. We also expand on the QPS measure with machine-agnostic measures such as the number of distance computations per query, and we evaluate ANNS data structures on their accuracy in more demanding settings required in modern applications, such as evaluating range queries and running on out-of-distribution data. We optimize four graph-based algorithms for the billion-scale setting, and in the process provide a general framework for making many incremental ANNS graph algorithms lock-free. We use our framework to evaluate the aforementioned graph-based ANNS algorithms as well as two alternative approaches.