 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficiently Constructing Sparse Navigable Graphs
Jul 17, 2025



Graph-based nearest neighbor search methods have seen a surge of popularity in recent years, offering state-of-the-art performance across a wide variety of applications. Central to these methods is the task of constructing a sparse navigable search graph for a given dataset endowed with a distance function. Unfortunately, doing so is computationally expensive, so heuristics are universally used in practice. In this work, we initiate the study of fast algorithms with provable guarantees for search graph construction. For a dataset with $n$ data points, the problem of constructing an optimally sparse navigable graph can be framed as $n$ separate but highly correlated minimum set cover instances. This yields a naive $O(n^3)$ time greedy algorithm that returns a navigable graph whose sparsity is at most $O(\log n)$ higher than optimal. We improve significantly on this baseline, taking advantage of correlation between the set cover instances to leverage techniques from streaming and sublinear-time set cover algorithms. Combined with problem-specific pre-processing techniques, we present an $\tilde{O}(n^2)$ time algorithm for constructing an $O(\log n)$-approximate sparsest navigable graph under any distance function. The runtime of our method is optimal up to logarithmic factors under the Strong Exponential Time Hypothesis via a reduction from Monochromatic Closest Pair. Moreover, we prove that, as with general set cover, obtaining better than an $O(\log n)$-approximation is NP-hard, despite the significant additional structure present in the navigable graph problem. Finally, we show that our techniques can also beat cubic time for the closely related and practically important problems of constructing $\alpha$-shortcut reachable and $\tau$-monotonic graphs, which are also used for nearest neighbor search. For such graphs, we obtain $\tilde{O}(n^{2.5})$ time or better algorithms.
Distance Adaptive Beam Search for Provably Accurate Graph-Based Nearest Neighbor Search
May 21, 2025Nearest neighbor search is central in machine learning, information retrieval, and databases. For high-dimensional datasets, graph-based methods such as HNSW, DiskANN, and NSG have become popular thanks to their empirical accuracy and efficiency. These methods construct a directed graph over the dataset and perform beam search on the graph to find nodes close to a given query. While significant work has focused on practical refinements and theoretical understanding of graph-based methods, many questions remain. We propose a new distance-based termination condition for beam search to replace the commonly used condition based on beam width. We prove that, as long as the search graph is navigable, our resulting Adaptive Beam Search method is guaranteed to approximately solve the nearest-neighbor problem, establishing a connection between navigability and the performance of graph-based search. We also provide extensive experiments on our new termination condition for both navigable graphs and approximately navigable graphs used in practice, such as HNSW and Vamana graphs. We find that Adaptive Beam Search outperforms standard beam search over a range of recall values, data sets, graph constructions, and target number of nearest neighbors. It thus provides a simple and practical way to improve the performance of popular methods.
Beyond Quantile Methods: Improved Top-K Threshold Estimation for Traditional and Learned Sparse Indexes
Dec 14, 2024Top-k threshold estimation is the problem of estimating the score of the k-th highest ranking result of a search query. A good estimate can be used to speed up many common top-k query processing algorithms, and thus a number of researchers have recently studied the problem. Among the various approaches that have been proposed, quantile methods appear to give the best estimates overall at modest computational costs, followed by sampling-based methods in certain cases. In this paper, we make two main contributions. First, we study how to get even better estimates than the state of the art. Starting from quantile-based methods, we propose a series of enhancements that give improved estimates in terms of the commonly used mean under-prediction fraction (MUF). Second, we study the threshold estimation problem on recently proposed learned sparse index structures, showing that our methods also work well for these cases. Our best methods substantially narrow the gap between the state of the art and the ideal MUF of 1.0, at some additional cost in time and space.
Navigable Graphs for High-Dimensional Nearest Neighbor Search: Constructions and Limits
May 29, 2024There has been significant recent interest in graph-based nearest neighbor search methods, many of which are centered on the construction of navigable graphs over high-dimensional point sets. A graph is navigable if we can successfully move from any starting node to any target node using a greedy routing strategy where we always move to the neighbor that is closest to the destination according to a given distance function. The complete graph is navigable for any point set, but the important question for applications is if sparser graphs can be constructed. While this question is fairly well understood in low-dimensions, we establish some of the first upper and lower bounds for high-dimensional point sets. First, we give a simple and efficient way to construct a navigable graph with average degree $O(\sqrt{n \log n })$ for any set of $n$ points, in any dimension, for any distance function. We compliment this result with a nearly matching lower bound: even under the Euclidean metric in $O(\log n)$ dimensions, a random point set has no navigable graph with average degree $O(n^{\alpha})$ for any $\alpha < 1/2$. Our lower bound relies on sharp anti-concentration bounds for binomial random variables, which we use to show that the near-neighborhoods of a set of random points do not overlap significantly, forcing any navigable graph to have many edges.
DeeperImpact: Optimizing Sparse Learned Index Structures
May 27, 2024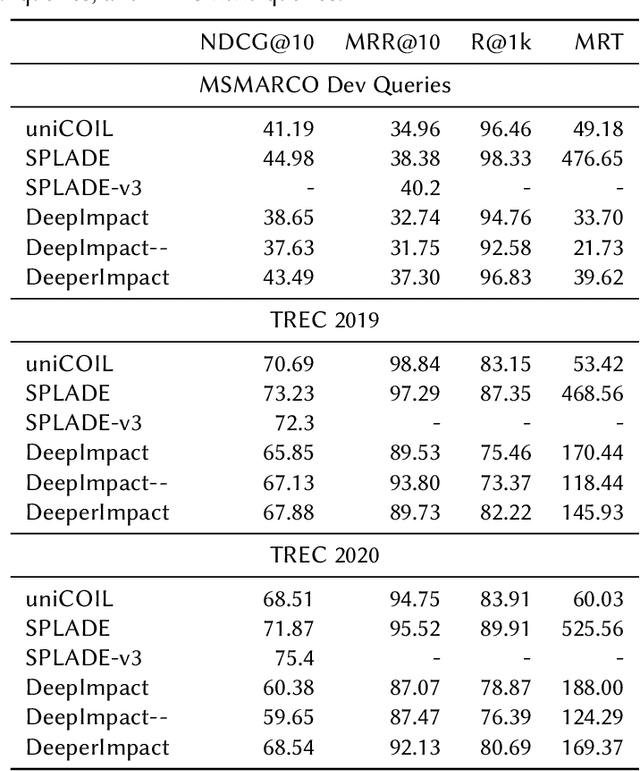
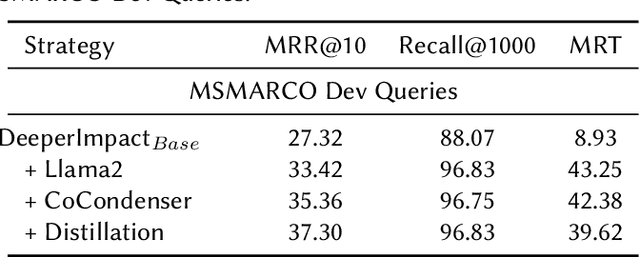
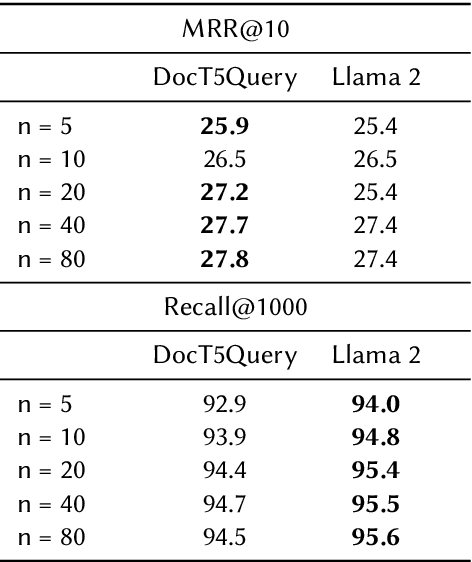
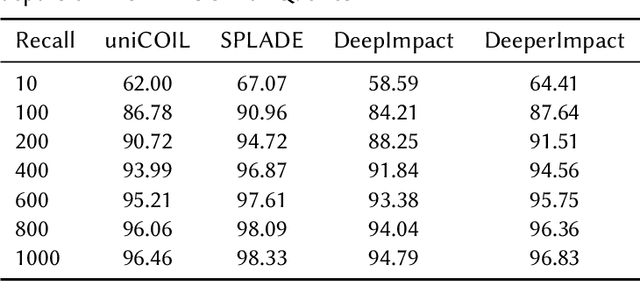
A lot of recent work has focused on sparse learned indexes that use deep neural architectures to significantly improve retrieval quality while keeping the efficiency benefits of the inverted index. While such sparse learned structures achieve effectiveness far beyond those of traditional inverted index-based rankers, there is still a gap in effectiveness to the best dense retrievers, or even to sparse methods that leverage more expensive optimizations such as query expansion and query term weighting. We focus on narrowing this gap by revisiting and optimizing DeepImpact, a sparse retrieval approach that uses DocT5Query for document expansion followed by a BERT language model to learn impact scores for document terms. We first reinvestigate the expansion process and find that the recently proposed Doc2Query query filtration does not enhance retrieval quality when used with DeepImpact. Instead, substituting T5 with a fine-tuned Llama 2 model for query prediction results in a considerable improvement. Subsequently, we study training strategies that have proven effective for other models, in particular the use of hard negatives, distillation, and pre-trained CoCondenser model initialization. Our results significantly narrow the effectiveness gap with the most effective versions of SPLADE.
Faster Learned Sparse Retrieval with Guided Traversal
Apr 24, 2022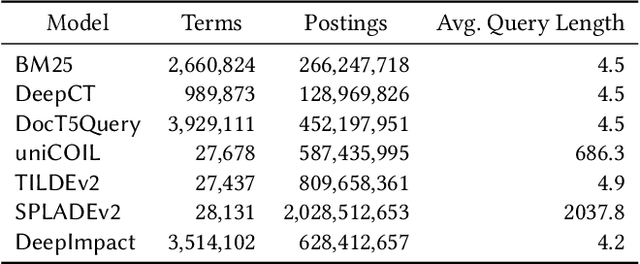
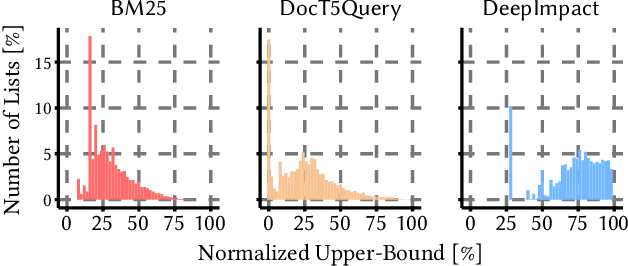
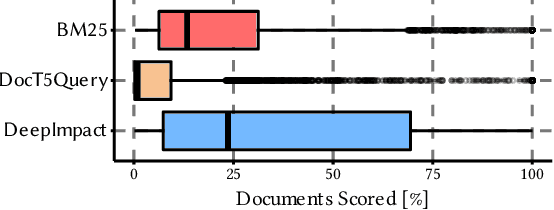
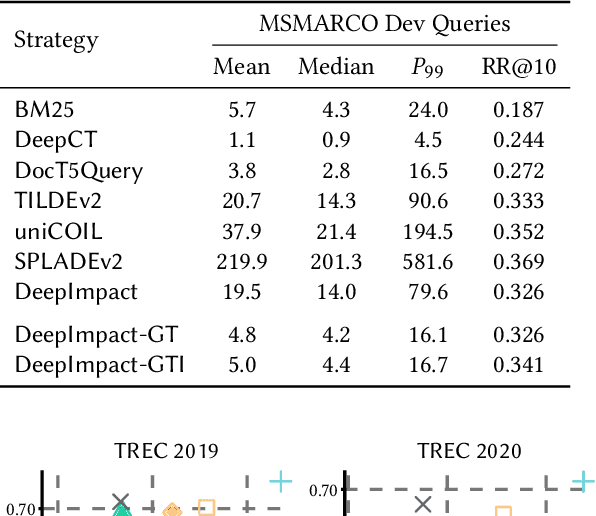
Neural information retrieval architectures based on transformers such as BERT are able to significantly improve system effectiveness over traditional sparse models such as BM25. Though highly effective, these neural approaches are very expensive to run, making them difficult to deploy under strict latency constraints. To address this limitation, recent studies have proposed new families of learned sparse models that try to match the effectiveness of learned dense models, while leveraging the traditional inverted index data structure for efficiency. Current learned sparse models learn the weights of terms in documents and, sometimes, queries; however, they exploit different vocabulary structures, document expansion techniques, and query expansion strategies, which can make them slower than traditional sparse models such as BM25. In this work, we propose a novel indexing and query processing technique that exploits a traditional sparse model's "guidance" to efficiently traverse the index, allowing the more effective learned model to execute fewer scoring operations. Our experiments show that our guided processing heuristic is able to boost the efficiency of the underlying learned sparse model by a factor of four without any measurable loss of effectiveness.
Learning Passage Impacts for Inverted Indexes
Apr 24, 2021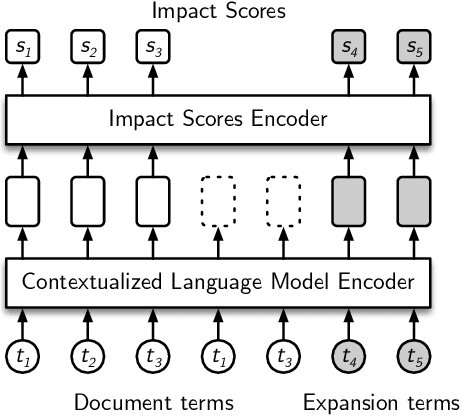

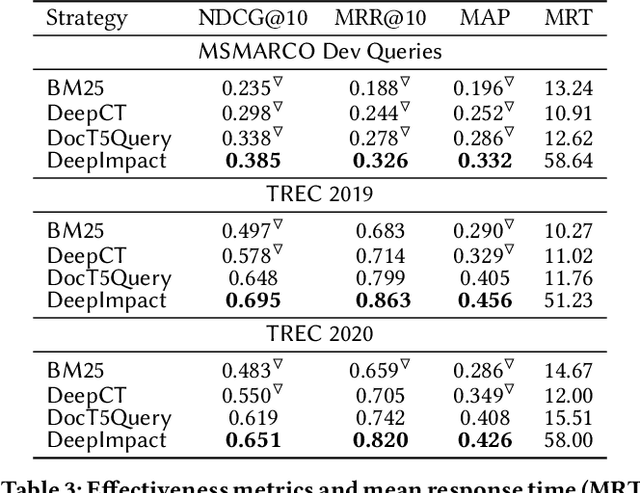
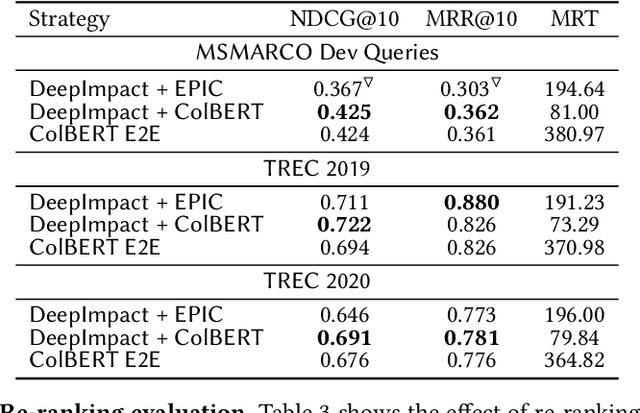
Neural information retrieval systems typically use a cascading pipeline, in which a first-stage model retrieves a candidate set of documents and one or more subsequent stages re-rank this set using contextualized language models such as BERT. In this paper, we propose DeepImpact, a new document term-weighting scheme suitable for efficient retrieval using a standard inverted index. Compared to existing methods, DeepImpact improves impact-score modeling and tackles the vocabulary-mismatch problem. In particular, DeepImpact leverages DocT5Query to enrich the document collection and, using a contextualized language model, directly estimates the semantic importance of tokens in a document, producing a single-value representation for each token in each document. Our experiments show that DeepImpact significantly outperforms prior first-stage retrieval approaches by up to 17% on effectiveness metrics w.r.t. DocT5Query, and, when deployed in a re-ranking scenario, can reach the same effectiveness of state-of-the-art approaches with up to 5.1x speedup in efficiency.