 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Community Detection via Parallel Correlation Clustering
Paper and Code
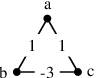
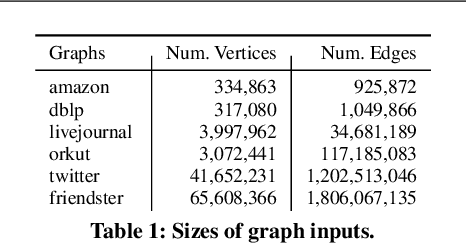
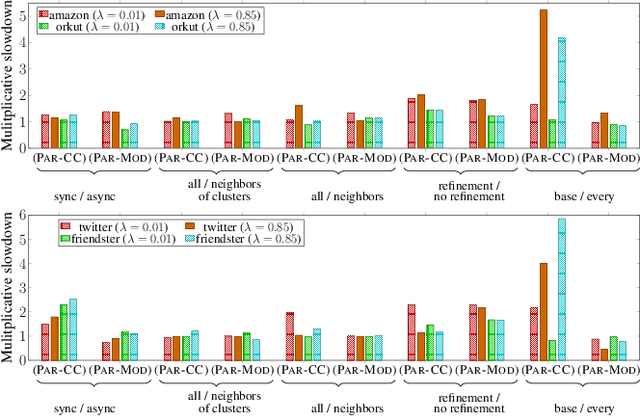
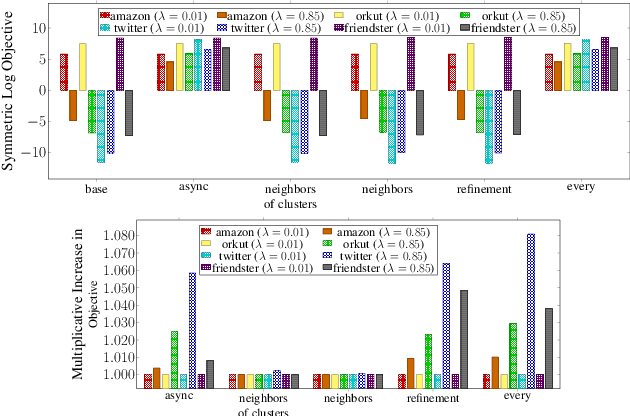
Graph clustering and community detection are central problems in modern data mining. The increasing need for analyzing billion-scale data calls for faster and more scalable algorithms for these problems. There are certain trade-offs between the quality and speed of such clustering algorithms. In this paper, we design scalable algorithms that achieve high quality when evaluated based on ground truth. We develop a generalized sequential and shared-memory parallel framework based on the LambdaCC objective (introduced by Veldt et al.), which encompasses modularity and correlation clustering. Our framework consists of highly-optimized implementations that scale to large data sets of billions of edges and that obtain high-quality clusters compared to ground-truth data, on both unweighted and weighted graphs. Our empirical evaluation shows that this framework improves the state-of-the-art trade-offs between speed and quality of scalable community detection. For example, on a 30-core machine with two-way hyper-threading, our implementations achieve orders of magnitude speedups over other correlation clustering baselines, and up to 28.44x speedups over our own sequential baselines while maintaining or improving quality.