 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtreme Classification in Log Memory
Paper and Code
Oct 09, 2018
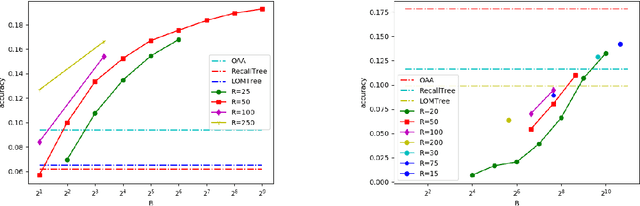
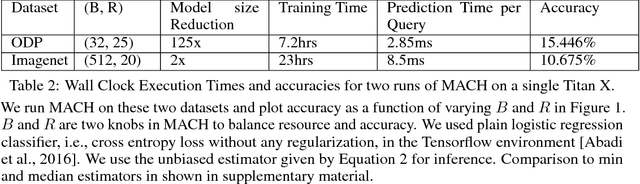
We present Merged-Averaged Classifiers via Hashing (MACH) for K-classification with ultra-large values of K. Compared to traditional one-vs-all classifiers that require O(Kd) memory and inference cost, MACH only need O(d log K) (d is dimensionality )memory while only requiring O(K log K + d log K) operation for inference. MACH is a generic K-classification algorithm, with provably theoretical guarantees, which requires O(log K) memory without any assumption on the relationship between classes. MACH uses universal hashing to reduce classification with a large number of classes to few independent classification tasks with small (constant) number of classes. We provide theoretical quantification of discriminability-memory tradeoff. With MACH we can train ODP dataset with 100,000 classes and 400,000 features on a single Titan X GPU, with the classification accuracy of 19.28%, which is the best-reported accuracy on this dataset. Before this work, the best performing baseline is a one-vs-all classifier that requires 40 billion parameters (160 GB model size) and achieves 9% accuracy. In contrast, MACH can achieve 9% accuracy with 480x reduction in the model size (of mere 0.3GB). With MACH, we also demonstrate complete training of fine-grained imagenet dataset (compressed size 104GB), with 21,000 classes, on a single GPU. To the best of our knowledge, this is the first work to demonstrate complete training of these extreme-class datasets on a single Titan X.