 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOLT: An Automated Deep Learning Framework for Training and Deploying Large-Scale Neural Networks on Commodity CPU Hardware
Mar 30, 2023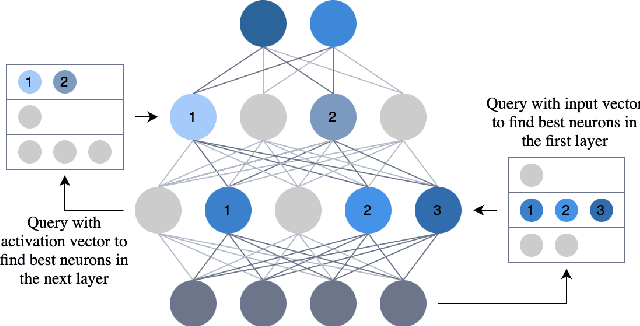
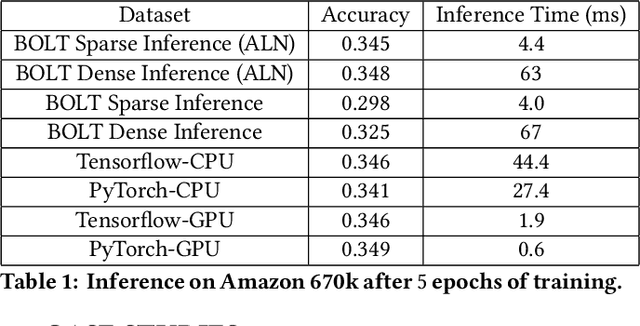
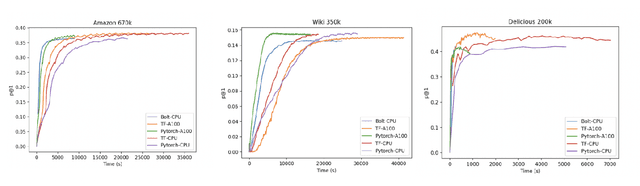
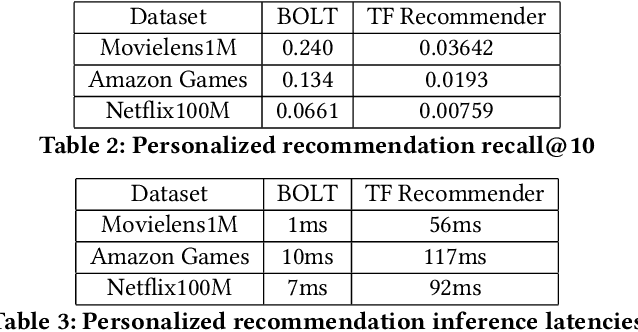
Efficient large-scale neural network training and inference on commodity CPU hardware is of immense practical significance in democratizing deep learning (DL) capabilities. Presently, the process of training massive models consisting of hundreds of millions to billions of parameters requires the extensive use of specialized hardware accelerators, such as GPUs, which are only accessible to a limited number of institutions with considerable financial resources. Moreover, there is often an alarming carbon footprint associated with training and deploying these models. In this paper, we address these challenges by introducing BOLT, a sparse deep learning library for training massive neural network models on standard CPU hardware. BOLT provides a flexible, high-level API for constructing models that will be familiar to users of existing popular DL frameworks. By automatically tuning specialized hyperparameters, BOLT also abstracts away the algorithmic details of sparse network training. We evaluate BOLT on a number of machine learning tasks drawn from recommendations, search, natural language processing, and personalization. We find that our proposed system achieves competitive performance with state-of-the-art techniques at a fraction of the cost and energy consumption and an order-of-magnitude faster inference time. BOLT has also been successfully deployed by multiple businesses to address critical problems, and we highlight one customer deployment case study in the field of e-commerce.
Distributed SLIDE: Enabling Training Large Neural Networks on Low Bandwidth and Simple CPU-Clusters via Model Parallelism and Sparsity
Jan 29, 2022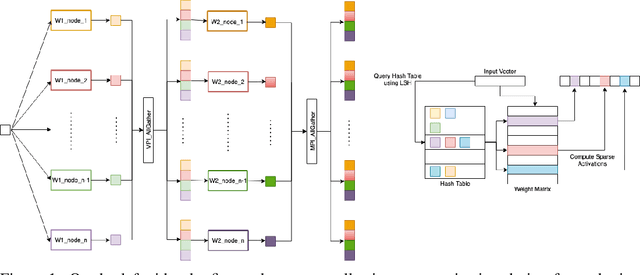
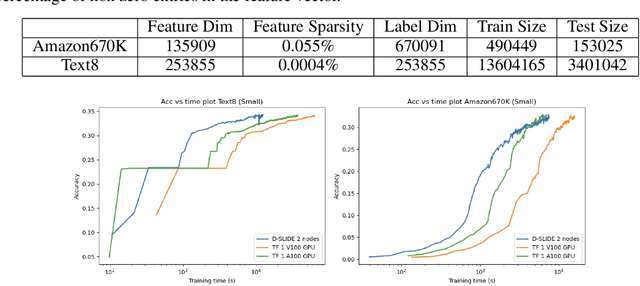
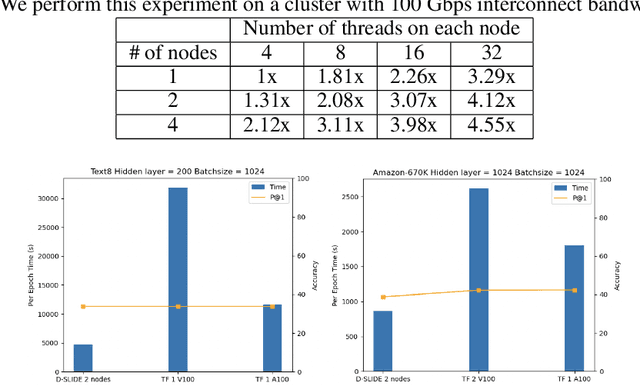

More than 70% of cloud computing is paid for but sits idle. A large fraction of these idle compute are cheap CPUs with few cores that are not utilized during the less busy hours. This paper aims to enable those CPU cycles to train heavyweight AI models. Our goal is against mainstream frameworks, which focus on leveraging expensive specialized ultra-high bandwidth interconnect to address the communication bottleneck in distributed neural network training. This paper presents a distributed model-parallel training framework that enables training large neural networks on small CPU clusters with low Internet bandwidth. We build upon the adaptive sparse training framework introduced by the SLIDE algorithm. By carefully deploying sparsity over distributed nodes, we demonstrate several orders of magnitude faster model parallel training than Horovod, the main engine behind most commercial software. We show that with reduced communication, due to sparsity, we can train close to a billion parameter model on simple 4-16 core CPU nodes connected by basic low bandwidth interconnect. Moreover, the training time is at par with some of the best hardware accelerators.
IRLI: Iterative Re-partitioning for Learning to Index
Mar 17, 2021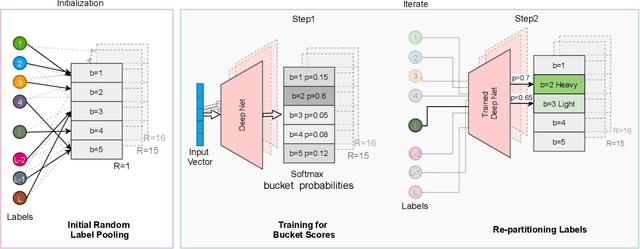
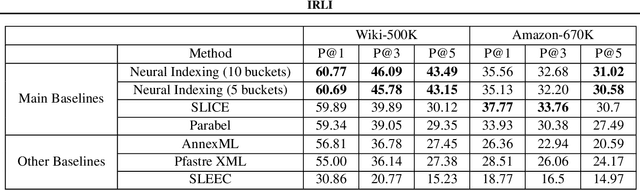
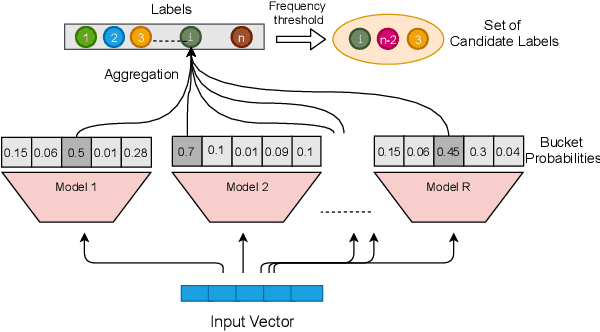
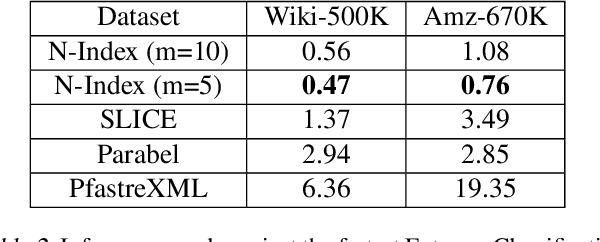
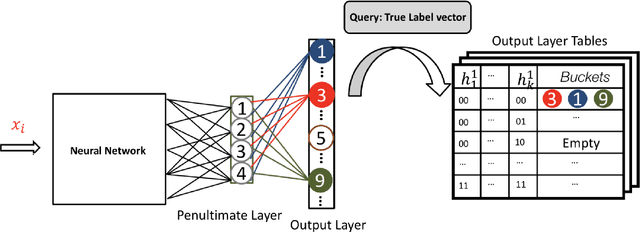
Neural models have transformed the fundamental information retrieval problem of mapping a query to a giant set of items. However, the need for efficient and low latency inference forces the community to reconsider efficient approximate near-neighbor search in the item space. To this end, learning to index is gaining much interest in recent times. Methods have to trade between obtaining high accuracy while maintaining load balance and scalability in distributed settings. We propose a novel approach called IRLI (pronounced `early'), which iteratively partitions the items by learning the relevant buckets directly from the query-item relevance data. Furthermore, IRLI employs a superior power-of-$k$-choices based load balancing strategy. We mathematically show that IRLI retrieves the correct item with high probability under very natural assumptions and provides superior load balancing. IRLI surpasses the best baseline's precision on multi-label classification while being $5x$ faster on inference. For near-neighbor search tasks, the same method outperforms the state-of-the-art Learned Hashing approach NeuralLSH by requiring only ~ {1/6}^th of the candidates for the same recall. IRLI is both data and model parallel, making it ideal for distributed GPU implementation. We demonstrate this advantage by indexing 100 million dense vectors and surpassing the popular FAISS library by >10% on recall.
A Constant-time Adaptive Negative Sampling
Dec 31, 2020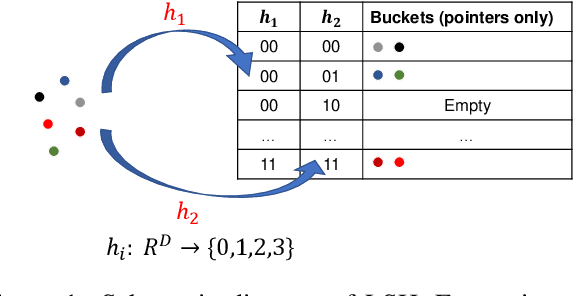

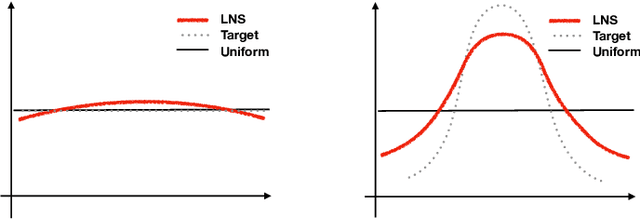
Softmax classifiers with a very large number of classes naturally occur in many applications such as natural language processing and information retrieval. The calculation of full-softmax is very expensive from the computational and energy perspective. There have been a variety of sampling approaches to overcome this challenge, popularly known as negative sampling (NS). Ideally, NS should sample negative classes from a distribution that is dependent on the input data, the current parameters, and the correct positive class. Unfortunately, due to the dynamically updated parameters and data samples, there does not exist any sampling scheme that is truly adaptive and also samples the negative classes in constant time every iteration. Therefore, alternative heuristics like random sampling, static frequency-based sampling, or learning-based biased sampling, which primarily trade either the sampling cost or the adaptivity of samples per iteration, are adopted. In this paper, we show a class of distribution where the sampling scheme is truly adaptive and provably generates negative samples in constant time. Our implementation in C++ on commodity CPU is significantly faster, in terms of wall clock time, compared to the most optimized TensorFlow implementations of standard softmax or other sampling approaches on modern GPUs (V100s).
SOLAR: Sparse Orthogonal Learned and Random Embeddings
Aug 30, 2020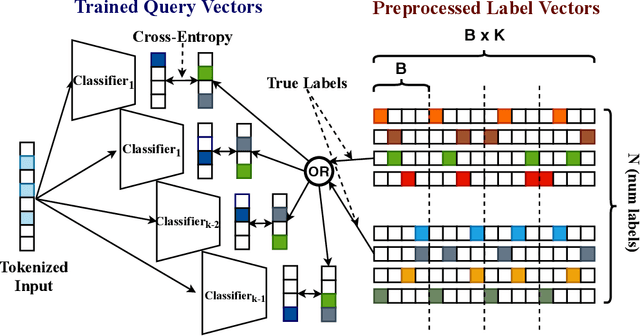
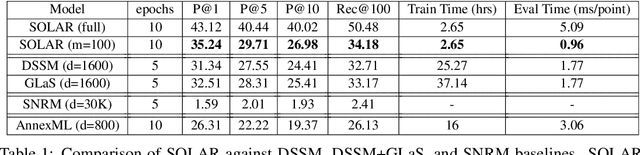
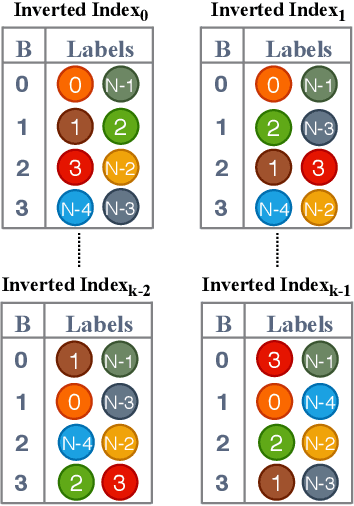
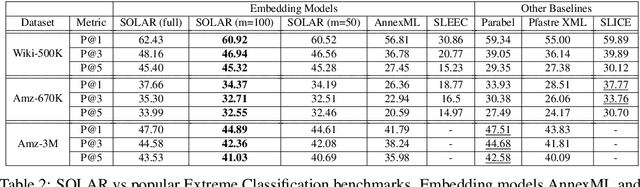
Dense embedding models are commonly deployed in commercial search engines, wherein all the document vectors are pre-computed, and near-neighbor search (NNS) is performed with the query vector to find relevant documents. However, the bottleneck of indexing a large number of dense vectors and performing an NNS hurts the query time and accuracy of these models. In this paper, we argue that high-dimensional and ultra-sparse embedding is a significantly superior alternative to dense low-dimensional embedding for both query efficiency and accuracy. Extreme sparsity eliminates the need for NNS by replacing them with simple lookups, while its high dimensionality ensures that the embeddings are informative even when sparse. However, learning extremely high dimensional embeddings leads to blow up in the model size. To make the training feasible, we propose a partitioning algorithm that learns such high dimensional embeddings across multiple GPUs without any communication. This is facilitated by our novel asymmetric mixture of Sparse, Orthogonal, Learned and Random (SOLAR) Embeddings. The label vectors are random, sparse, and near-orthogonal by design, while the query vectors are learned and sparse. We theoretically prove that our way of one-sided learning is equivalent to learning both query and label embeddings. With these unique properties, we can successfully train 500K dimensional SOLAR embeddings for the tasks of searching through 1.6M books and multi-label classification on the three largest public datasets. We achieve superior precision and recall compared to the respective state-of-the-art baselines for each of the tasks with up to 10 times faster speed.
Extreme Classification in Log Memory using Count-Min Sketch: A Case Study of Amazon Search with 50M Products
Oct 28, 2019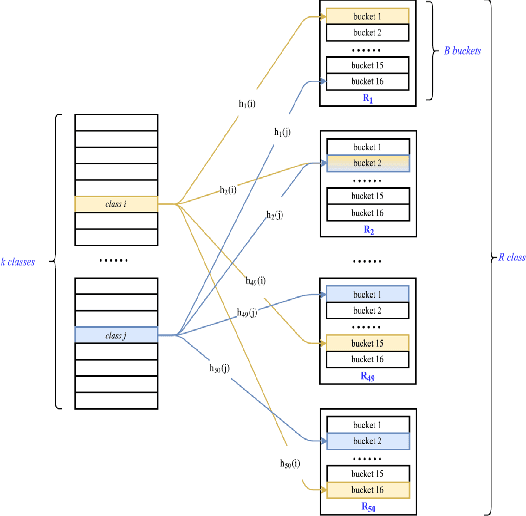

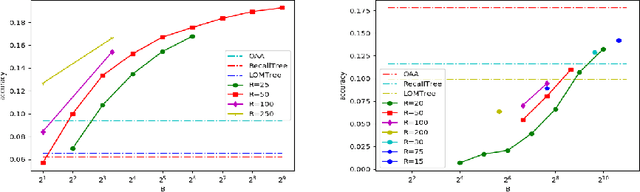
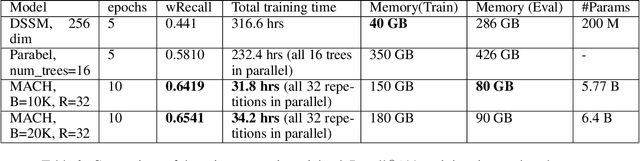
In the last decade, it has been shown that many hard AI tasks, especially in NLP, can be naturally modeled as extreme classification problems leading to improved precision. However, such models are prohibitively expensive to train due to the memory blow-up in the last layer. For example, a reasonable softmax layer for the dataset of interest in this paper can easily reach well beyond 100 billion parameters (>400 GB memory). To alleviate this problem, we present Merged-Average Classifiers via Hashing (MACH), a generic K-classification algorithm where memory provably scales at O(logK) without any strong assumption on the classes. MACH is subtly a count-min sketch structure in disguise, which uses universal hashing to reduce classification with a large number of classes to few embarrassingly parallel and independent classification tasks with a small (constant) number of classes. MACH naturally provides a technique for zero communication model parallelism. We experiment with 6 datasets; some multiclass and some multilabel, and show consistent improvement over respective state-of-the-art baselines. In particular, we train an end-to-end deep classifier on a private product search dataset sampled from Amazon Search Engine with 70 million queries and 49.46 million products. MACH outperforms, by a significant margin,the state-of-the-art extreme classification models deployed on commercial search engines: Parabel and dense embedding models. Our largest model has 6.4 billion parameters and trains in less than 35 hours on a single p3.16x machine. Our training times are 7-10x faster, and our memory footprints are 2-4x smaller than the best baselines. This training time is also significantly lower than the one reported by Google's mixture of experts (MoE) language model on a comparable model size and hardware.
Semantic Similarity Based Softmax Classifier for Zero-Shot Learning
Sep 10, 2019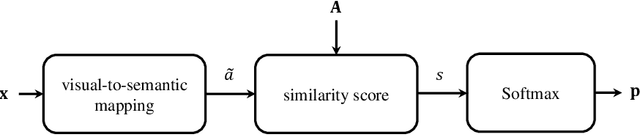
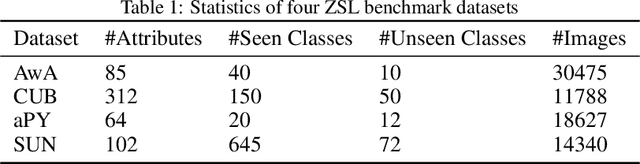
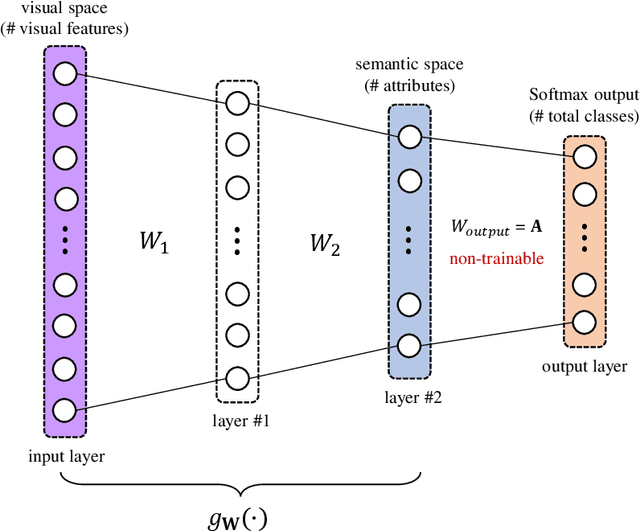
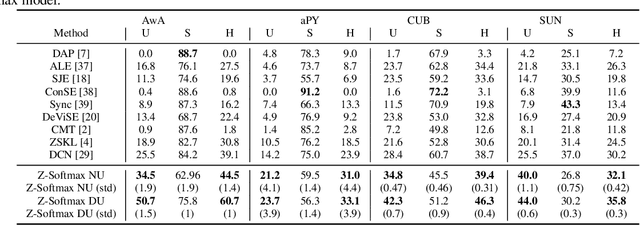
Zero-Shot Learning (ZSL) is a classification task where we do not have even a single training labeled example from a set of unseen classes. Instead, we only have prior information (or description) about seen and unseen classes, often in the form of physically realizable or descriptive attributes. Lack of any single training example from a set of classes prohibits use of standard classification techniques and losses, including the popular crossentropy loss. Currently, state-of-the-art approaches encode the prior class information into dense vectors and optimize some distance between the learned projections of the input vector and the corresponding class vector (collectively known as embedding models). In this paper, we propose a novel architecture of casting zero-shot learning as a standard neural-network with crossentropy loss. During training our approach performs soft-labeling by combining the observed training data for the seen classes with the similarity information from the attributes for which we have no training data or unseen classes. To the best of our knowledge, such similarity based soft-labeling is not explored in the field of deep learning. We evaluate the proposed model on the four benchmark datasets for zero-shot learning, AwA, aPY, SUN and CUB datasets, and show that our model achieves significant improvement over the state-of-the-art methods in Generalized-ZSL and ZSL settings on all of these datasets consistently.
SLIDE : In Defense of Smart Algorithms over Hardware Acceleration for Large-Scale Deep Learning Systems
Mar 07, 2019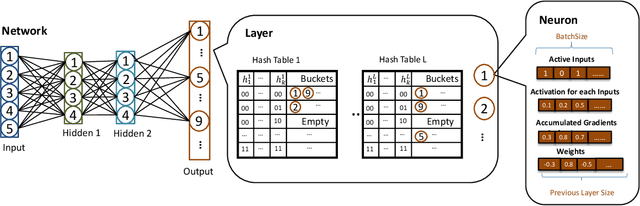

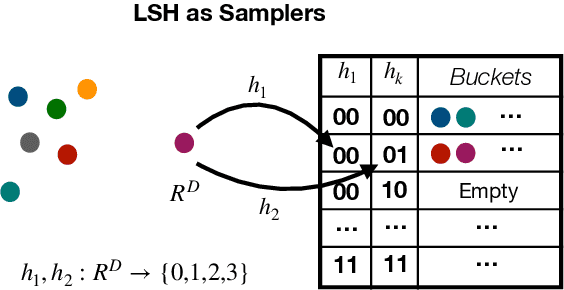
Deep Learning (DL) algorithms are the central focus of modern machine learning systems. As data volumes keep growing, it has become customary to train large neural networks with hundreds of millions of parameters with enough capacity to memorize these volumes and obtain state-of-the-art accuracy. To get around the costly computations associated with large models and data, the community is increasingly investing in specialized hardware for model training. However, with the end of Moore's law, there is a limit to such scaling. The progress on the algorithmic front has failed to demonstrate a direct advantage over powerful hardware such as NVIDIA-V100 GPUs. This paper provides an exception. We propose SLIDE (Sub-LInear Deep learning Engine) that uniquely blends smart randomized algorithms, which drastically reduce the computation during both training and inference, with simple multi-core parallelism on a modest CPU. SLIDE is an auspicious illustration of the power of smart randomized algorithms over CPUs in outperforming the best available GPU with an optimized implementation. Our evaluations on large industry-scale datasets, with some large fully connected architectures, show that training with SLIDE on a 44 core CPU is more than 2.7 times (2 hours vs. 5.5 hours) faster than the same network trained using Tensorflow on Tesla V100 at any given accuracy level. We provide codes and benchmark scripts for reproducibility.
Extreme Classification in Log Memory
Oct 09, 2018
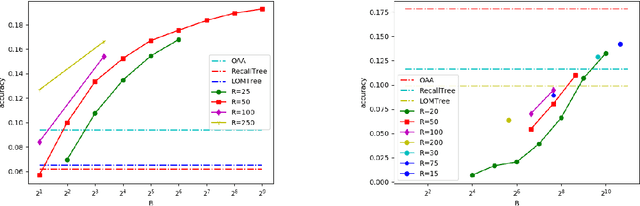
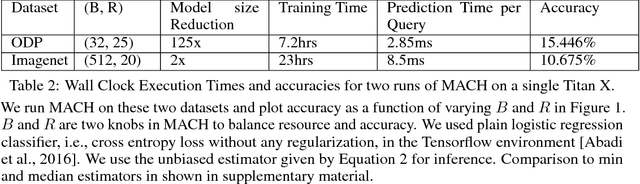
We present Merged-Averaged Classifiers via Hashing (MACH) for K-classification with ultra-large values of K. Compared to traditional one-vs-all classifiers that require O(Kd) memory and inference cost, MACH only need O(d log K) (d is dimensionality )memory while only requiring O(K log K + d log K) operation for inference. MACH is a generic K-classification algorithm, with provably theoretical guarantees, which requires O(log K) memory without any assumption on the relationship between classes. MACH uses universal hashing to reduce classification with a large number of classes to few independent classification tasks with small (constant) number of classes. We provide theoretical quantification of discriminability-memory tradeoff. With MACH we can train ODP dataset with 100,000 classes and 400,000 features on a single Titan X GPU, with the classification accuracy of 19.28%, which is the best-reported accuracy on this dataset. Before this work, the best performing baseline is a one-vs-all classifier that requires 40 billion parameters (160 GB model size) and achieves 9% accuracy. In contrast, MACH can achieve 9% accuracy with 480x reduction in the model size (of mere 0.3GB). With MACH, we also demonstrate complete training of fine-grained imagenet dataset (compressed size 104GB), with 21,000 classes, on a single GPU. To the best of our knowledge, this is the first work to demonstrate complete training of these extreme-class datasets on a single Titan X.