 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIRLI: Iterative Re-partitioning for Learning to Index
Paper and Code
Mar 17, 2021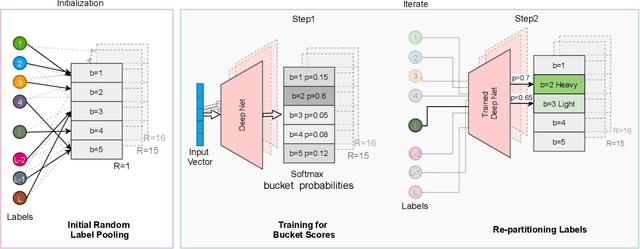
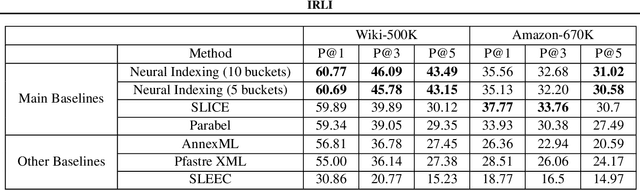
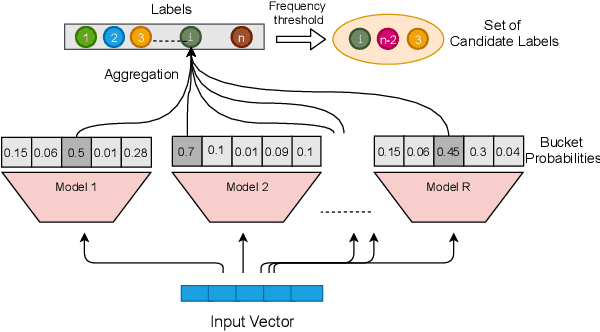
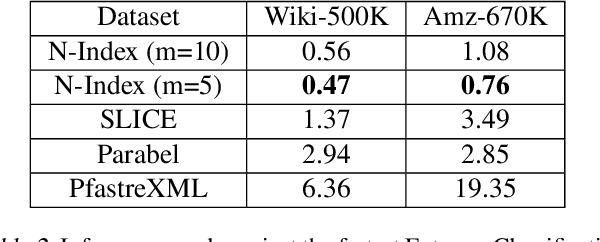
Neural models have transformed the fundamental information retrieval problem of mapping a query to a giant set of items. However, the need for efficient and low latency inference forces the community to reconsider efficient approximate near-neighbor search in the item space. To this end, learning to index is gaining much interest in recent times. Methods have to trade between obtaining high accuracy while maintaining load balance and scalability in distributed settings. We propose a novel approach called IRLI (pronounced `early'), which iteratively partitions the items by learning the relevant buckets directly from the query-item relevance data. Furthermore, IRLI employs a superior power-of-$k$-choices based load balancing strategy. We mathematically show that IRLI retrieves the correct item with high probability under very natural assumptions and provides superior load balancing. IRLI surpasses the best baseline's precision on multi-label classification while being $5x$ faster on inference. For near-neighbor search tasks, the same method outperforms the state-of-the-art Learned Hashing approach NeuralLSH by requiring only ~ {1/6}^th of the candidates for the same recall. IRLI is both data and model parallel, making it ideal for distributed GPU implementation. We demonstrate this advantage by indexing 100 million dense vectors and surpassing the popular FAISS library by >10% on recall.