 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Sampling for Deep Learning via Efficient Nonparametric Proxies
Nov 22, 2023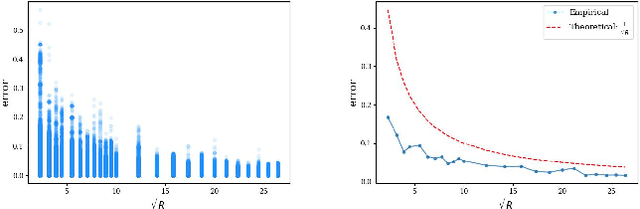
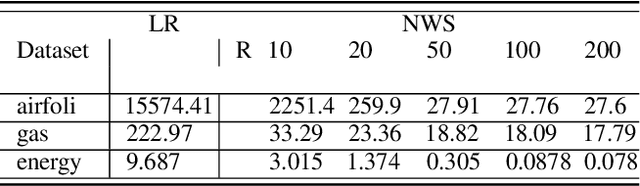
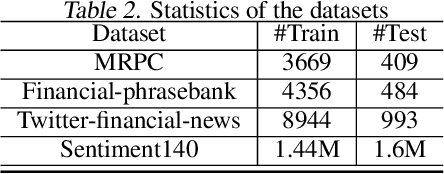
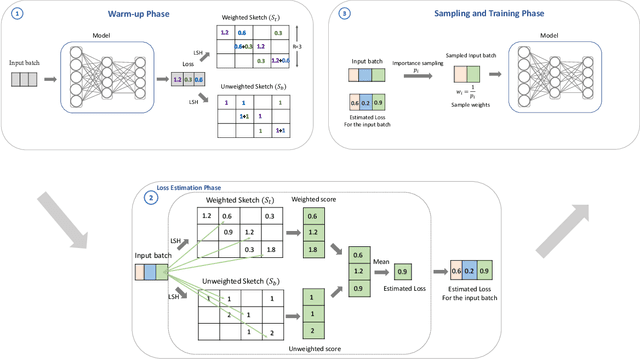
Data sampling is an effective method to improve the training speed of neural networks, with recent results demonstrating that it can even break the neural scaling laws. These results critically rely on high-quality scores to estimate the importance of an input to the network. We observe that there are two dominant strategies: static sampling, where the scores are determined before training, and dynamic sampling, where the scores can depend on the model weights. Static algorithms are computationally inexpensive but less effective than their dynamic counterparts, which can cause end-to-end slowdown due to their need to explicitly compute losses. To address this problem, we propose a novel sampling distribution based on nonparametric kernel regression that learns an effective importance score as the neural network trains. However, nonparametric regression models are too computationally expensive to accelerate end-to-end training. Therefore, we develop an efficient sketch-based approximation to the Nadaraya-Watson estimator. Using recent techniques from high-dimensional statistics and randomized algorithms, we prove that our Nadaraya-Watson sketch approximates the estimator with exponential convergence guarantees. Our sampling algorithm outperforms the baseline in terms of wall-clock time and accuracy on four datasets.
Accelerating SLIDE Deep Learning on Modern CPUs: Vectorization, Quantizations, Memory Optimizations, and More
Mar 06, 2021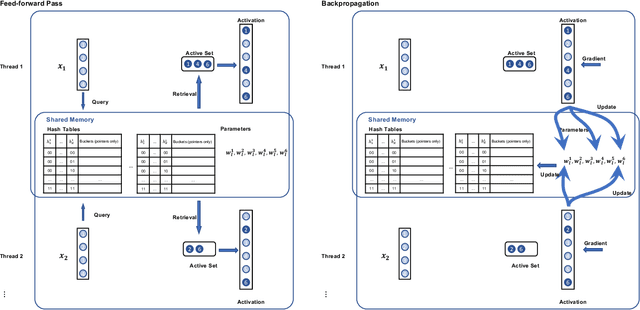


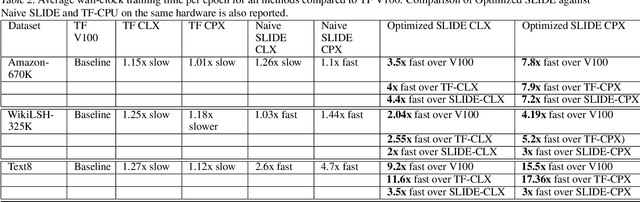
Deep learning implementations on CPUs (Central Processing Units) are gaining more traction. Enhanced AI capabilities on commodity x86 architectures are commercially appealing due to the reuse of existing hardware and virtualization ease. A notable work in this direction is the SLIDE system. SLIDE is a C++ implementation of a sparse hash table based back-propagation, which was shown to be significantly faster than GPUs in training hundreds of million parameter neural models. In this paper, we argue that SLIDE's current implementation is sub-optimal and does not exploit several opportunities available in modern CPUs. In particular, we show how SLIDE's computations allow for a unique possibility of vectorization via AVX (Advanced Vector Extensions)-512. Furthermore, we highlight opportunities for different kinds of memory optimization and quantizations. Combining all of them, we obtain up to 7x speedup in the computations on the same hardware. Our experiments are focused on large (hundreds of millions of parameters) recommendation and NLP models. Our work highlights several novel perspectives and opportunities for implementing randomized algorithms for deep learning on modern CPUs. We provide the code and benchmark scripts at https://github.com/RUSH-LAB/SLIDE
A Constant-time Adaptive Negative Sampling
Dec 31, 2020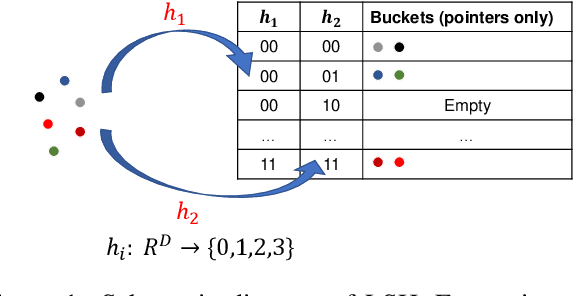

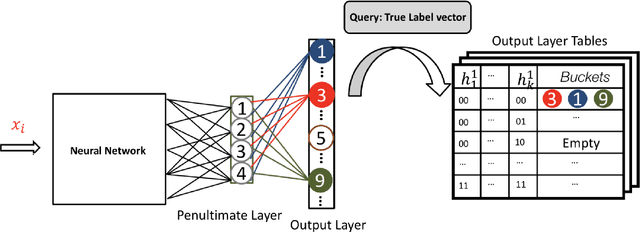
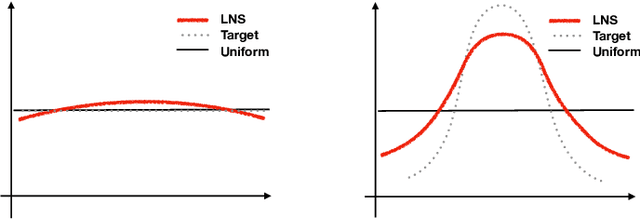
Softmax classifiers with a very large number of classes naturally occur in many applications such as natural language processing and information retrieval. The calculation of full-softmax is very expensive from the computational and energy perspective. There have been a variety of sampling approaches to overcome this challenge, popularly known as negative sampling (NS). Ideally, NS should sample negative classes from a distribution that is dependent on the input data, the current parameters, and the correct positive class. Unfortunately, due to the dynamically updated parameters and data samples, there does not exist any sampling scheme that is truly adaptive and also samples the negative classes in constant time every iteration. Therefore, alternative heuristics like random sampling, static frequency-based sampling, or learning-based biased sampling, which primarily trade either the sampling cost or the adaptivity of samples per iteration, are adopted. In this paper, we show a class of distribution where the sampling scheme is truly adaptive and provably generates negative samples in constant time. Our implementation in C++ on commodity CPU is significantly faster, in terms of wall clock time, compared to the most optimized TensorFlow implementations of standard softmax or other sampling approaches on modern GPUs (V100s).
Semantic Similarity Based Softmax Classifier for Zero-Shot Learning
Sep 10, 2019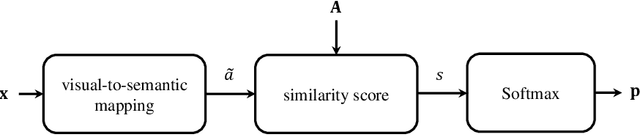
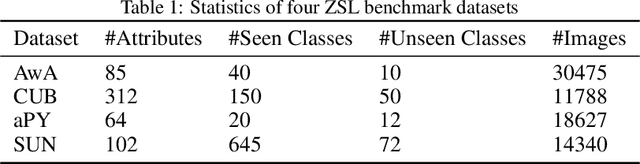
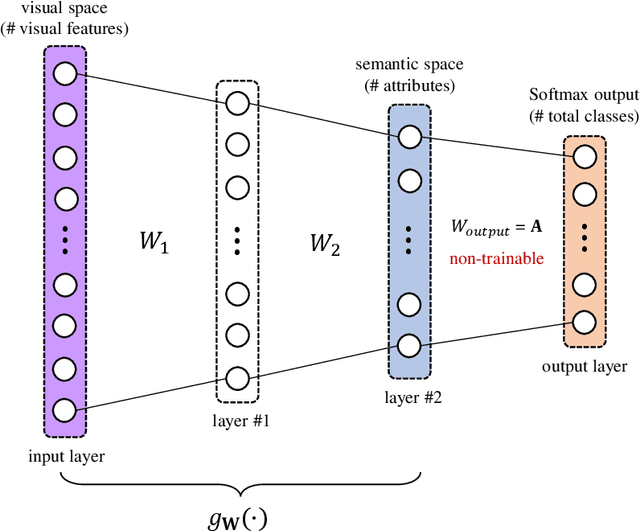
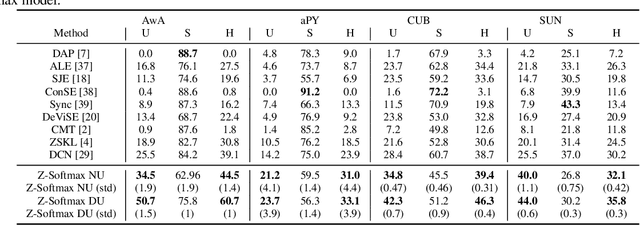
Zero-Shot Learning (ZSL) is a classification task where we do not have even a single training labeled example from a set of unseen classes. Instead, we only have prior information (or description) about seen and unseen classes, often in the form of physically realizable or descriptive attributes. Lack of any single training example from a set of classes prohibits use of standard classification techniques and losses, including the popular crossentropy loss. Currently, state-of-the-art approaches encode the prior class information into dense vectors and optimize some distance between the learned projections of the input vector and the corresponding class vector (collectively known as embedding models). In this paper, we propose a novel architecture of casting zero-shot learning as a standard neural-network with crossentropy loss. During training our approach performs soft-labeling by combining the observed training data for the seen classes with the similarity information from the attributes for which we have no training data or unseen classes. To the best of our knowledge, such similarity based soft-labeling is not explored in the field of deep learning. We evaluate the proposed model on the four benchmark datasets for zero-shot learning, AwA, aPY, SUN and CUB datasets, and show that our model achieves significant improvement over the state-of-the-art methods in Generalized-ZSL and ZSL settings on all of these datasets consistently.