 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Sampling for Deep Learning via Efficient Nonparametric Proxies
Paper and Code
Nov 22, 2023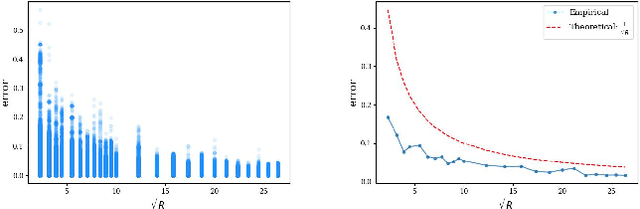
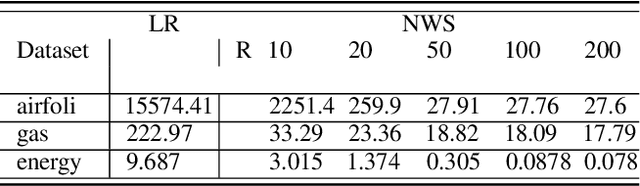
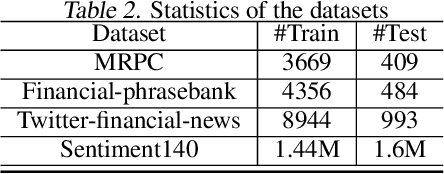
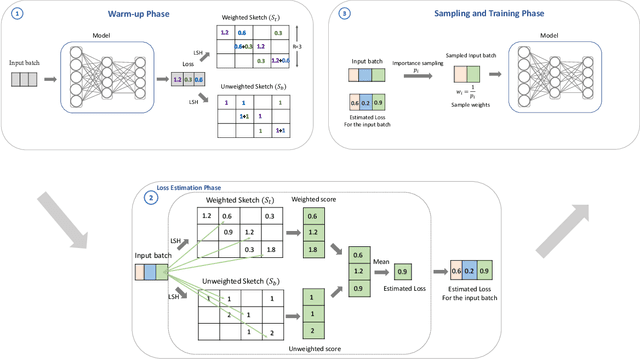
Data sampling is an effective method to improve the training speed of neural networks, with recent results demonstrating that it can even break the neural scaling laws. These results critically rely on high-quality scores to estimate the importance of an input to the network. We observe that there are two dominant strategies: static sampling, where the scores are determined before training, and dynamic sampling, where the scores can depend on the model weights. Static algorithms are computationally inexpensive but less effective than their dynamic counterparts, which can cause end-to-end slowdown due to their need to explicitly compute losses. To address this problem, we propose a novel sampling distribution based on nonparametric kernel regression that learns an effective importance score as the neural network trains. However, nonparametric regression models are too computationally expensive to accelerate end-to-end training. Therefore, we develop an efficient sketch-based approximation to the Nadaraya-Watson estimator. Using recent techniques from high-dimensional statistics and randomized algorithms, we prove that our Nadaraya-Watson sketch approximates the estimator with exponential convergence guarantees. Our sampling algorithm outperforms the baseline in terms of wall-clock time and accuracy on four datasets.