 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOLT: An Automated Deep Learning Framework for Training and Deploying Large-Scale Neural Networks on Commodity CPU Hardware
Mar 30, 2023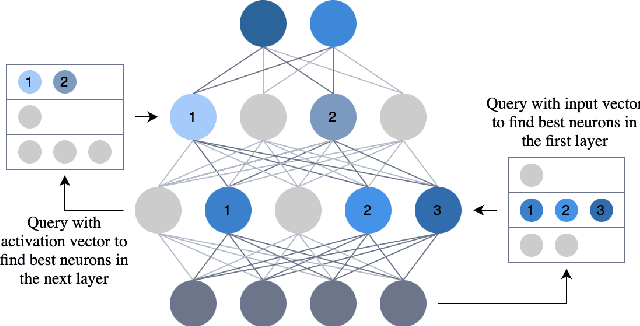
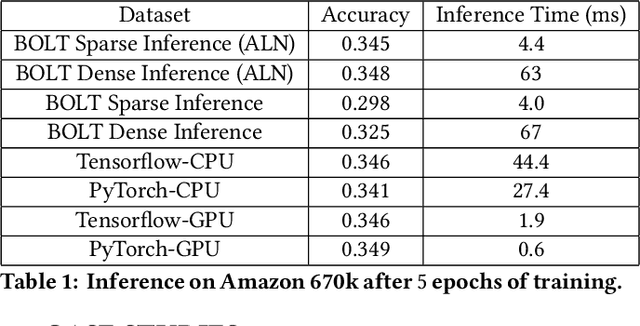
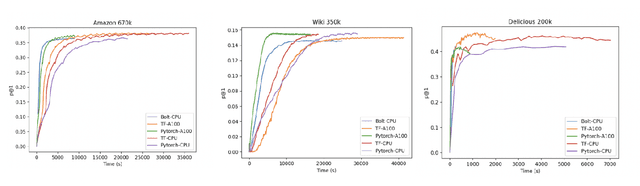
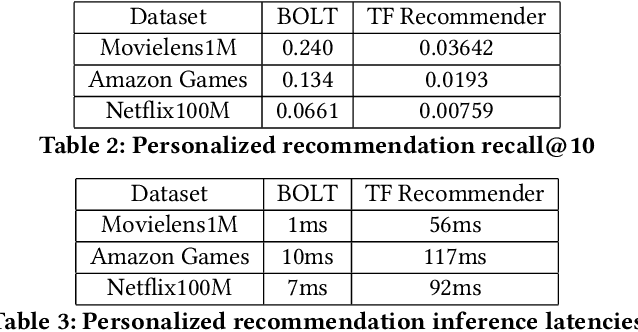
Efficient large-scale neural network training and inference on commodity CPU hardware is of immense practical significance in democratizing deep learning (DL) capabilities. Presently, the process of training massive models consisting of hundreds of millions to billions of parameters requires the extensive use of specialized hardware accelerators, such as GPUs, which are only accessible to a limited number of institutions with considerable financial resources. Moreover, there is often an alarming carbon footprint associated with training and deploying these models. In this paper, we address these challenges by introducing BOLT, a sparse deep learning library for training massive neural network models on standard CPU hardware. BOLT provides a flexible, high-level API for constructing models that will be familiar to users of existing popular DL frameworks. By automatically tuning specialized hyperparameters, BOLT also abstracts away the algorithmic details of sparse network training. We evaluate BOLT on a number of machine learning tasks drawn from recommendations, search, natural language processing, and personalization. We find that our proposed system achieves competitive performance with state-of-the-art techniques at a fraction of the cost and energy consumption and an order-of-magnitude faster inference time. BOLT has also been successfully deployed by multiple businesses to address critical problems, and we highlight one customer deployment case study in the field of e-commerce.
Distributed SLIDE: Enabling Training Large Neural Networks on Low Bandwidth and Simple CPU-Clusters via Model Parallelism and Sparsity
Jan 29, 2022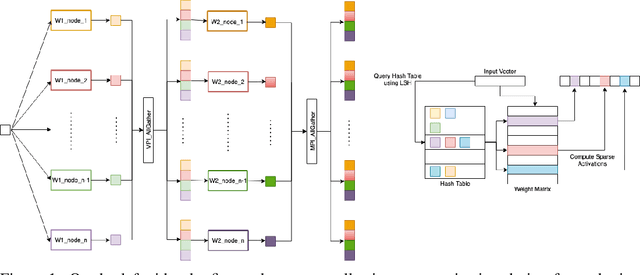
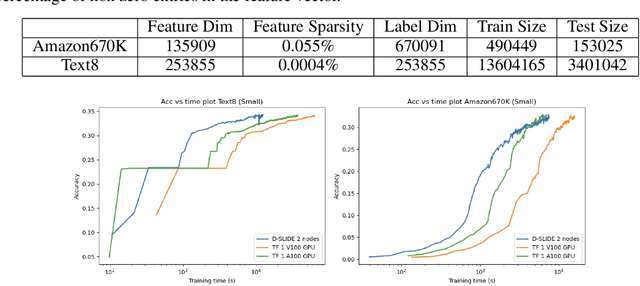
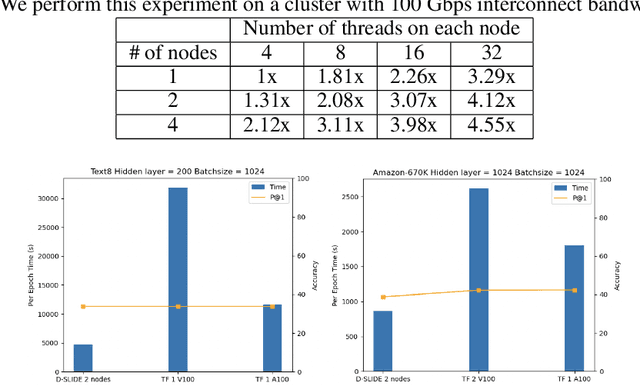

More than 70% of cloud computing is paid for but sits idle. A large fraction of these idle compute are cheap CPUs with few cores that are not utilized during the less busy hours. This paper aims to enable those CPU cycles to train heavyweight AI models. Our goal is against mainstream frameworks, which focus on leveraging expensive specialized ultra-high bandwidth interconnect to address the communication bottleneck in distributed neural network training. This paper presents a distributed model-parallel training framework that enables training large neural networks on small CPU clusters with low Internet bandwidth. We build upon the adaptive sparse training framework introduced by the SLIDE algorithm. By carefully deploying sparsity over distributed nodes, we demonstrate several orders of magnitude faster model parallel training than Horovod, the main engine behind most commercial software. We show that with reduced communication, due to sparsity, we can train close to a billion parameter model on simple 4-16 core CPU nodes connected by basic low bandwidth interconnect. Moreover, the training time is at par with some of the best hardware accelerators.
Accelerating SLIDE Deep Learning on Modern CPUs: Vectorization, Quantizations, Memory Optimizations, and More
Mar 06, 2021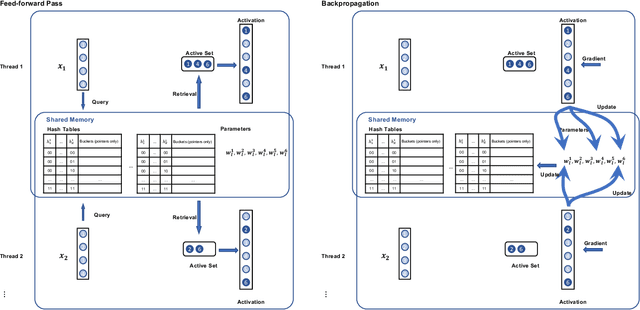


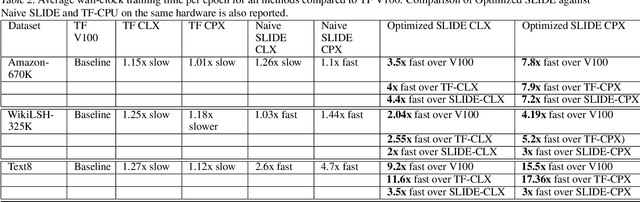
Deep learning implementations on CPUs (Central Processing Units) are gaining more traction. Enhanced AI capabilities on commodity x86 architectures are commercially appealing due to the reuse of existing hardware and virtualization ease. A notable work in this direction is the SLIDE system. SLIDE is a C++ implementation of a sparse hash table based back-propagation, which was shown to be significantly faster than GPUs in training hundreds of million parameter neural models. In this paper, we argue that SLIDE's current implementation is sub-optimal and does not exploit several opportunities available in modern CPUs. In particular, we show how SLIDE's computations allow for a unique possibility of vectorization via AVX (Advanced Vector Extensions)-512. Furthermore, we highlight opportunities for different kinds of memory optimization and quantizations. Combining all of them, we obtain up to 7x speedup in the computations on the same hardware. Our experiments are focused on large (hundreds of millions of parameters) recommendation and NLP models. Our work highlights several novel perspectives and opportunities for implementing randomized algorithms for deep learning on modern CPUs. We provide the code and benchmark scripts at https://github.com/RUSH-LAB/SLIDE
Distributed Tera-Scale Similarity Search with MPI: Provably Efficient Similarity Search over billions without a Single Distance Computation
Aug 17, 2020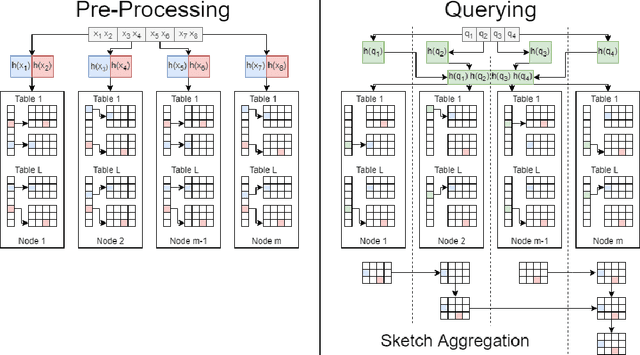



We present SLASH (Sketched LocAlity Sensitive Hashing), an MPI (Message Passing Interface) based distributed system for approximate similarity search over terabyte scale datasets. SLASH provides a multi-node implementation of the popular LSH (locality sensitive hashing) algorithm, which is generally implemented on a single machine. We show how we can append the LSH algorithm with heavy hitters sketches to provably solve the (high) similarity search problem without a single distance computation. Overall, we mathematically show that, under realistic data assumptions, we can identify the near-neighbor of a given query $q$ in sub-linear ($ \ll O(n)$) number of simple sketch aggregation operations only. To make such a system practical, we offer a novel design and sketching solution to reduce the inter-machine communication overheads exponentially. In a direct comparison on comparable hardware, SLASH is more than 10000x faster than the popular LSH package in PySpark. PySpark is a widely-adopted distributed implementation of the LSH algorithm for large datasets and is deployed in commercial platforms. In the end, we show how our system scale to Tera-scale Criteo dataset with more than 4 billion samples. SLASH can index this 2.3 terabyte data over 20 nodes in under an hour, with query times in a fraction of milliseconds. To the best of our knowledge, there is no open-source system that can index and perform a similarity search on Criteo with a commodity cluster.