 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTABED: Test-Time Adaptive Ensemble Drafting for Robust Speculative Decoding in LVLMs
Jan 28, 2026Speculative decoding (SD) has proven effective for accelerating LLM inference by quickly generating draft tokens and verifying them in parallel. However, SD remains largely unexplored for Large Vision-Language Models (LVLMs), which extend LLMs to process both image and text prompts. To address this gap, we benchmark existing inference methods with small draft models on 11 datasets across diverse input scenarios and observe scenario-specific performance fluctuations. Motivated by these findings, we propose Test-time Adaptive Batched Ensemble Drafting (TABED), which dynamically ensembles multiple drafts obtained via batch inference by leveraging deviations from past ground truths available in the SD setting. The dynamic ensemble method achieves an average robust walltime speedup of 1.74x over autoregressive decoding and a 5% improvement over single drafting methods, while remaining training-free and keeping ensembling costs negligible through parameter sharing. With its plug-and-play compatibility, we further enhance TABED by integrating advanced verification and alternative drafting methods. Code and custom-trained models are available at https://github.com/furiosa-ai/TABED.
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Jan 17, 2026AI agents may soon become capable of autonomously completing valuable, long-horizon tasks in diverse domains. Current benchmarks either do not measure real-world tasks, or are not sufficiently difficult to meaningfully measure frontier models. To this end, we present Terminal-Bench 2.0: a carefully curated hard benchmark composed of 89 tasks in computer terminal environments inspired by problems from real workflows. Each task features a unique environment, human-written solution, and comprehensive tests for verification. We show that frontier models and agents score less than 65\% on the benchmark and conduct an error analysis to identify areas for model and agent improvement. We publish the dataset and evaluation harness to assist developers and researchers in future work at https://www.tbench.ai/ .
PACEvolve: Enabling Long-Horizon Progress-Aware Consistent Evolution
Jan 15, 2026Large Language Models (LLMs) have emerged as powerful operators for evolutionary search, yet the design of efficient search scaffolds remains ad hoc. While promising, current LLM-in-the-loop systems lack a systematic approach to managing the evolutionary process. We identify three distinct failure modes: Context Pollution, where experiment history biases future candidate generation; Mode Collapse, where agents stagnate in local minima due to poor exploration-exploitation balance; and Weak Collaboration, where rigid crossover strategies fail to leverage parallel search trajectories effectively. We introduce Progress-Aware Consistent Evolution (PACEvolve), a framework designed to robustly govern the agent's context and search dynamics, to address these challenges. PACEvolve combines hierarchical context management (HCM) with pruning to address context pollution; momentum-based backtracking (MBB) to escape local minima; and a self-adaptive sampling policy that unifies backtracking and crossover for dynamic search coordination (CE), allowing agents to balance internal refinement with cross-trajectory collaboration. We demonstrate that PACEvolve provides a systematic path to consistent, long-horizon self-improvement, achieving state-of-the-art results on LLM-SR and KernelBench, while discovering solutions surpassing the record on Modded NanoGPT.
Scaling Inference-Efficient Language Models
Jan 30, 2025



Scaling laws are powerful tools to predict the performance of large language models. However, current scaling laws fall short of accounting for inference costs. In this work, we first show that model architecture affects inference latency, where models of the same size can have up to 3.5x difference in latency. To tackle this challenge, we modify the Chinchilla scaling laws to co-optimize the model parameter count, the number of training tokens, and the model architecture. Due to the reason that models of similar training loss exhibit gaps in downstream evaluation, we also propose a novel method to train inference-efficient models based on the revised scaling laws. We perform extensive empirical studies to fit and evaluate our inference-aware scaling laws. We vary model parameters from 80M to 1B, training tokens from 1.6B to 30B, and model shapes, training a total of 63 models. Guided by our inference-efficient scaling law and model selection method, we release the Morph-1B model, which improves inference latency by 1.8x while maintaining accuracy on downstream tasks compared to open-source models, pushing the Pareto frontier of accuracy-latency tradeoff.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Decoding Speculative Decoding
Feb 02, 2024



Speculative Decoding is a widely used technique to speed up inference for Large Language Models (LLMs) without modifying its outcome. When performing inference on an LLM, speculative decoding uses a smaller draft model which generates speculative tokens and then uses the target LLM to verify those draft tokens. The speedup provided by speculative decoding heavily depends on the choice of the draft model. It has been widely suggested to select a draft model that provides a high probability of the generated token being accepted by the LLM to achieve the highest throughput. However, our experiments indicate the contrary with throughput diminishing as the probability of generated tokens to be accepted by the target model increases. To understand this phenomenon, we perform extensive experiments to characterize the different factors that affect speculative decoding and how those factors interact and affect the speedups. Based on our experiments we describe an analytical model which can be used to decide the right draft model for a given workload. Further, using our insights we design a new draft model for LLaMA-65B which can provide 30% higher throughput than existing draft models.
PolyThrottle: Energy-efficient Neural Network Inference on Edge Devices
Oct 30, 2023



As neural networks (NN) are deployed across diverse sectors, their energy demand correspondingly grows. While several prior works have focused on reducing energy consumption during training, the continuous operation of ML-powered systems leads to significant energy use during inference. This paper investigates how the configuration of on-device hardware-elements such as GPU, memory, and CPU frequency, often neglected in prior studies, affects energy consumption for NN inference with regular fine-tuning. We propose PolyThrottle, a solution that optimizes configurations across individual hardware components using Constrained Bayesian Optimization in an energy-conserving manner. Our empirical evaluation uncovers novel facets of the energy-performance equilibrium showing that we can save up to 36 percent of energy for popular models. We also validate that PolyThrottle can quickly converge towards near-optimal settings while satisfying application constraints.
Distributed SLIDE: Enabling Training Large Neural Networks on Low Bandwidth and Simple CPU-Clusters via Model Parallelism and Sparsity
Jan 29, 2022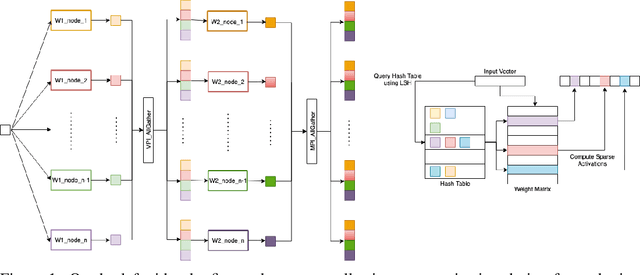
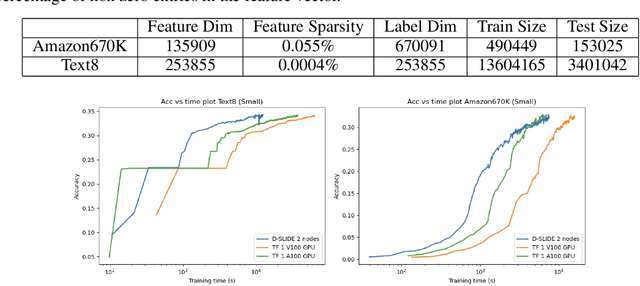
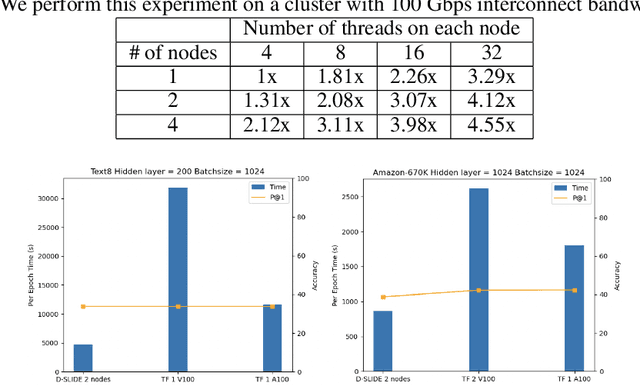

More than 70% of cloud computing is paid for but sits idle. A large fraction of these idle compute are cheap CPUs with few cores that are not utilized during the less busy hours. This paper aims to enable those CPU cycles to train heavyweight AI models. Our goal is against mainstream frameworks, which focus on leveraging expensive specialized ultra-high bandwidth interconnect to address the communication bottleneck in distributed neural network training. This paper presents a distributed model-parallel training framework that enables training large neural networks on small CPU clusters with low Internet bandwidth. We build upon the adaptive sparse training framework introduced by the SLIDE algorithm. By carefully deploying sparsity over distributed nodes, we demonstrate several orders of magnitude faster model parallel training than Horovod, the main engine behind most commercial software. We show that with reduced communication, due to sparsity, we can train close to a billion parameter model on simple 4-16 core CPU nodes connected by basic low bandwidth interconnect. Moreover, the training time is at par with some of the best hardware accelerators.
PairConnect: A Compute-Efficient MLP Alternative to Attention
Jun 15, 2021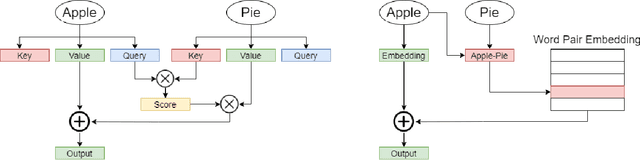
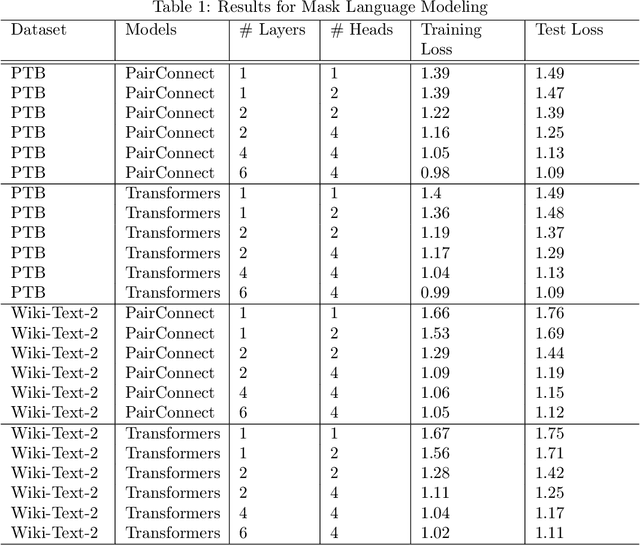
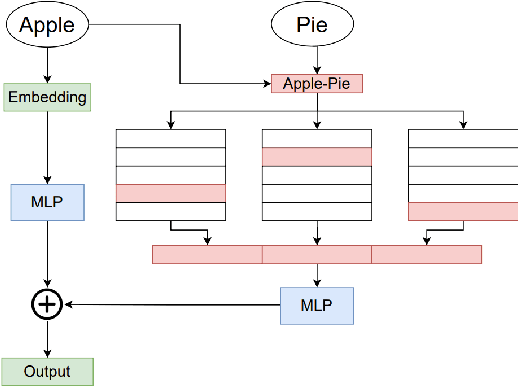
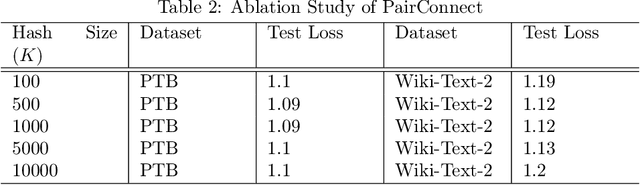
Transformer models have demonstrated superior performance in natural language processing. The dot product self-attention in Transformer allows us to model interactions between words. However, this modeling comes with significant computational overhead. In this work, we revisit the memory-compute trade-off associated with Transformer, particularly multi-head attention, and show a memory-heavy but significantly more compute-efficient alternative to Transformer. Our proposal, denoted as PairConnect, a multilayer perceptron (MLP), models the pairwise interaction between words by explicit pairwise word embeddings. As a result, PairConnect substitutes self dot product with a simple embedding lookup. We show mathematically that despite being an MLP, our compute-efficient PairConnect is strictly more expressive than Transformer. Our experiment on language modeling tasks suggests that PairConnect could achieve comparable results with Transformer while reducing the computational cost associated with inference significantly.