 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARAMEL: A Succinct Read-Only Lookup Table via Compressed Static Functions
May 26, 2023


Lookup tables are a fundamental structure in many data processing and systems applications. Examples include tokenized text in NLP, quantized embedding collections in recommendation systems, integer sketches for streaming data, and hash-based string representations in genomics. With the increasing size of web-scale data, such applications often require compression techniques that support fast random $O(1)$ lookup of individual parameters directly on the compressed data (i.e. without blockwise decompression in RAM). While the community has proposd a number of succinct data structures that support queries over compressed representations, these approaches do not fully leverage the low-entropy structure prevalent in real-world workloads to reduce space. Inspired by recent advances in static function construction techniques, we propose a space-efficient representation of immutable key-value data, called CARAMEL, specifically designed for the case where the values are multi-sets. By carefully combining multiple compressed static functions, CARAMEL occupies space proportional to the data entropy with low memory overheads and minimal lookup costs. We demonstrate 1.25-16x compression on practical lookup tasks drawn from real-world systems, improving upon established techniques, including a production-grade read-only database widely used for development within Amazon.com.
BOLT: An Automated Deep Learning Framework for Training and Deploying Large-Scale Neural Networks on Commodity CPU Hardware
Mar 30, 2023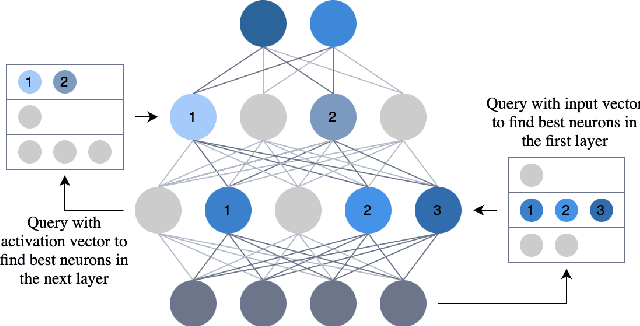
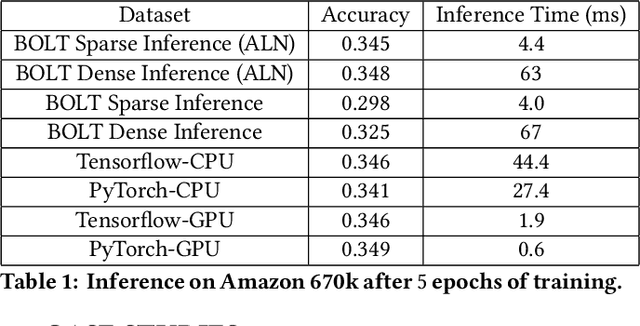
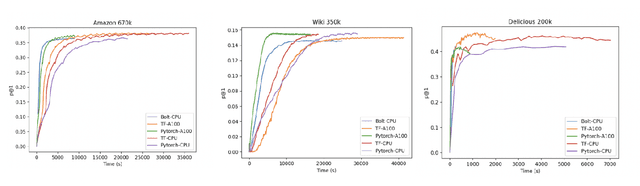
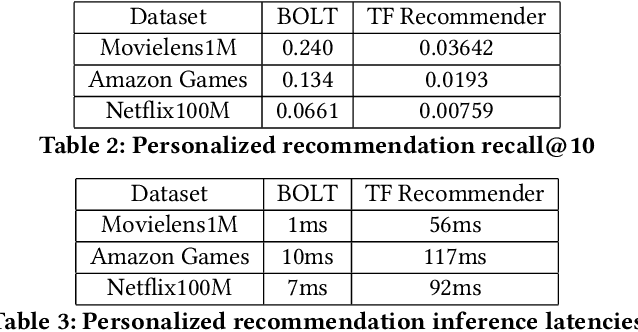
Efficient large-scale neural network training and inference on commodity CPU hardware is of immense practical significance in democratizing deep learning (DL) capabilities. Presently, the process of training massive models consisting of hundreds of millions to billions of parameters requires the extensive use of specialized hardware accelerators, such as GPUs, which are only accessible to a limited number of institutions with considerable financial resources. Moreover, there is often an alarming carbon footprint associated with training and deploying these models. In this paper, we address these challenges by introducing BOLT, a sparse deep learning library for training massive neural network models on standard CPU hardware. BOLT provides a flexible, high-level API for constructing models that will be familiar to users of existing popular DL frameworks. By automatically tuning specialized hyperparameters, BOLT also abstracts away the algorithmic details of sparse network training. We evaluate BOLT on a number of machine learning tasks drawn from recommendations, search, natural language processing, and personalization. We find that our proposed system achieves competitive performance with state-of-the-art techniques at a fraction of the cost and energy consumption and an order-of-magnitude faster inference time. BOLT has also been successfully deployed by multiple businesses to address critical problems, and we highlight one customer deployment case study in the field of e-commerce.