 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagic Pyramid: Accelerating Inference with Early Exiting and Token Pruning
Oct 30, 2021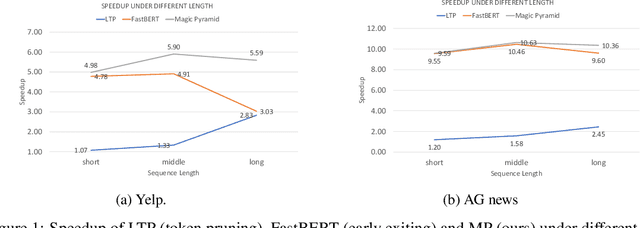
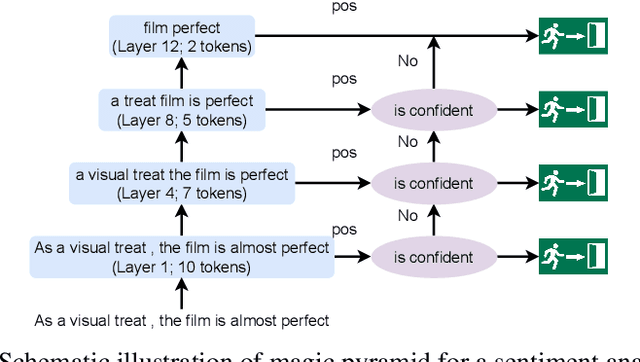
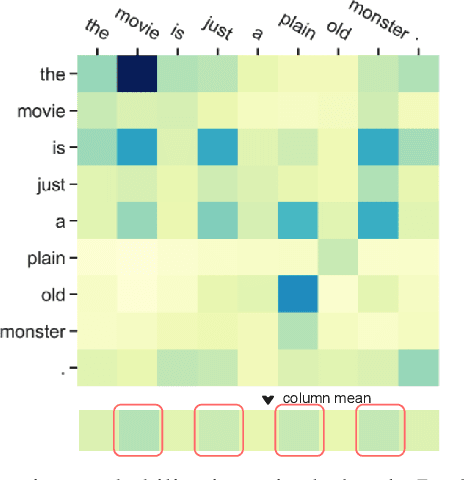
Pre-training and then fine-tuning large language models is commonly used to achieve state-of-the-art performance in natural language processing (NLP) tasks. However, most pre-trained models suffer from low inference speed. Deploying such large models to applications with latency constraints is challenging. In this work, we focus on accelerating the inference via conditional computations. To achieve this, we propose a novel idea, Magic Pyramid (MP), to reduce both width-wise and depth-wise computation via token pruning and early exiting for Transformer-based models, particularly BERT. The former manages to save the computation via removing non-salient tokens, while the latter can fulfill the computation reduction by terminating the inference early before reaching the final layer, if the exiting condition is met. Our empirical studies demonstrate that compared to previous state of arts, MP is not only able to achieve a speed-adjustable inference but also to surpass token pruning and early exiting by reducing up to 70% giga floating point operations (GFLOPs) with less than 0.5% accuracy drop. Token pruning and early exiting express distinctive preferences to sequences with different lengths. However, MP is capable of achieving an average of 8.06x speedup on two popular text classification tasks, regardless of the sizes of the inputs.
Low-Precision Quantization for Efficient Nearest Neighbor Search
Oct 17, 2021

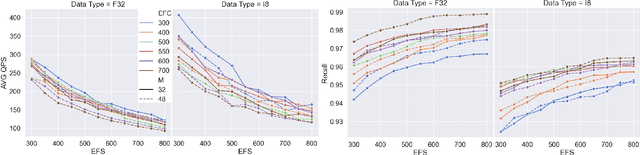

Fast k-Nearest Neighbor search over real-valued vector spaces (KNN) is an important algorithmic task for information retrieval and recommendation systems. We present a method for using reduced precision to represent vectors through quantized integer values, enabling both a reduction in the memory overhead of indexing these vectors and faster distance computations at query time. While most traditional quantization techniques focus on minimizing the reconstruction error between a point and its uncompressed counterpart, we focus instead on preserving the behavior of the underlying distance metric. Furthermore, our quantization approach is applied at the implementation level and can be combined with existing KNN algorithms. Our experiments on both open source and proprietary datasets across multiple popular KNN frameworks validate that quantized distance metrics can reduce memory by 60% and improve query throughput by 30%, while incurring only a 2% reduction in recall.