 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Frequency Bands on Acoustic Anomaly Detection of Machines using Deep Learning Based Model
Mar 01, 2024



In this paper, we propose a deep learning based model for Acoustic Anomaly Detection of Machines, the task for detecting abnormal machines by analysing the machine sound. By conducting extensive experiments, we indicate that multiple techniques of pseudo audios, audio segment, data augmentation, Mahalanobis distance, and narrow frequency bands, which mainly focus on feature engineering, are effective to enhance the system performance. Among the evaluating techniques, the narrow frequency bands presents a significant impact. Indeed, our proposed model, which focuses on the narrow frequency bands, outperforms the DCASE baseline on the benchmark dataset of DCASE 2022 Task 2 Development set. The important role of the narrow frequency bands indicated in this paper inspires the research community on the task of Acoustic Anomaly Detection of Machines to further investigate and propose novel network architectures focusing on the frequency bands.
LSTM-based Deep Neural Network With A Focus on Sentence Representation for Sequential Sentence Classification in Medical Scientific Abstracts
Jan 29, 2024



The Sequential Sentence Classification task within the domain of medical abstracts, termed as SSC, involves the categorization of sentences into pre-defined headings based on their roles in conveying critical information in the abstract. In the SSC task, sentences are often sequentially related to each other. For this reason, the role of sentence embedding is crucial for capturing both the semantic information between words in the sentence and the contextual relationship of sentences within the abstract to provide a comprehensive representation for better classification. In this paper, we present a hierarchical deep learning model for the SSC task. First, we propose a LSTM-based network with multiple feature branches to create well-presented sentence embeddings at the sentence level. To perform the sequence of sentences, a convolutional-recurrent neural network (C-RNN) at the abstract level and a multi-layer perception network (MLP) at the segment level are developed that further enhance the model performance. Additionally, an ablation study is also conducted to evaluate the contribution of individual component in the entire network to the model performance at different levels. Our proposed system is very competitive to the state-of-the-art systems and further improve F1 scores of the baseline by 1.0%, 2.8%, and 2.6% on the benchmark datasets PudMed 200K RCT, PudMed 20K RCT and NICTA-PIBOSO, respectively.
Wider or Deeper Neural Network Architecture for Acoustic Scene Classification with Mismatched Recording Devices
Mar 23, 2022
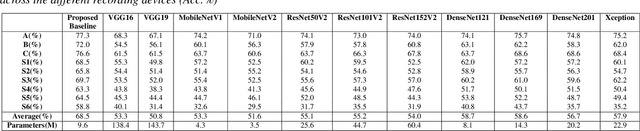
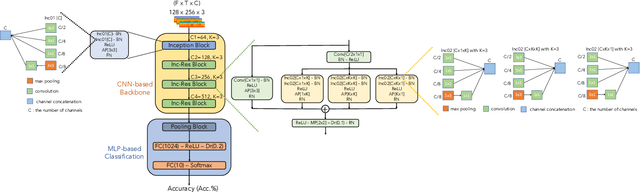
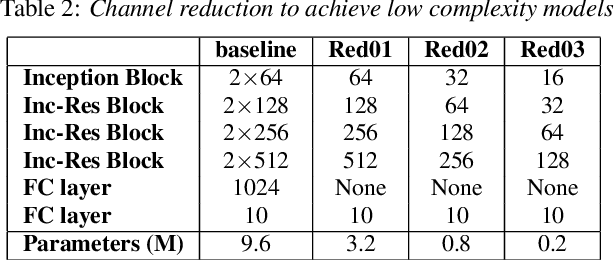
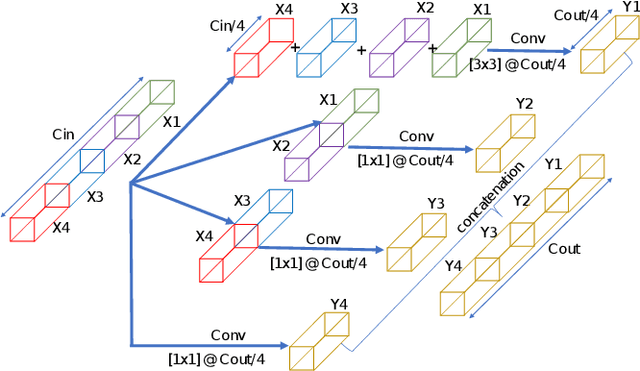
In this paper, we present a robust and low complexity system for Acoustic Scene Classification (ASC), the task of identifying the scene of an audio recording. We first construct an ASC baseline system in which a novel inception-residual-based network architecture is proposed to deal with the mismatched recording device issue. To further improve the performance but still satisfy the low complexity model, we apply two techniques: ensemble of multiple spectrograms and channel reduction on the ASC baseline system. By conducting extensive experiments on the benchmark DCASE 2020 Task 1A Development dataset, we achieve the best model performing an accuracy of 69.9% and a low complexity of 2.4M trainable parameters, which is competitive to the state-of-the-art ASC systems and potential for real-life applications on edge devices.
A Low-Compexity Deep Learning Framework For Acoustic Scene Classification
Jun 12, 2021
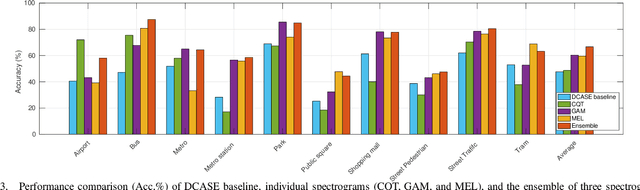
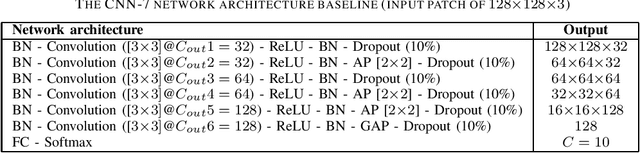
In this paper, we presents a low-complexity deep learning frameworks for acoustic scene classification (ASC). The proposed framework can be separated into three main steps: Front-end spectrogram extraction, back-end classification, and late fusion of predicted probabilities. First, we use Mel filter, Gammatone filter and Constant Q Transfrom (CQT) to transform raw audio signal into spectrograms, where both frequency and temporal features are presented. Three spectrograms are then fed into three individual back-end convolutional neural networks (CNNs), classifying into ten urban scenes. Finally, a late fusion of three predicted probabilities obtained from three CNNs is conducted to achieve the final classification result. To reduce the complexity of our proposed CNN network, we apply two model compression techniques: model restriction and decomposed convolution. Our extensive experiments, which are conducted on DCASE 2021 (IEEE AASP Challenge on Detection and Classification of Acoustic Scenes and Events) Task 1A development dataset, achieve a low-complexity CNN based framework with 128 KB trainable parameters and the best classification accuracy of 66.7%, improving DCASE baseline by 19.0%