 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefining activation downsampling with SoftPool
Jan 05, 2021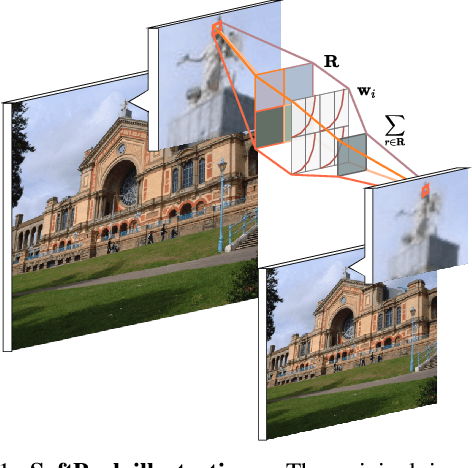
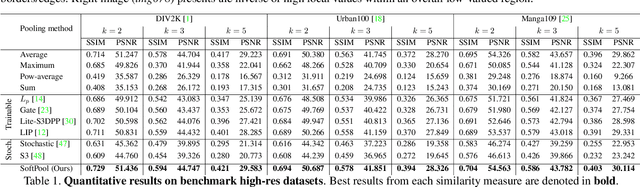
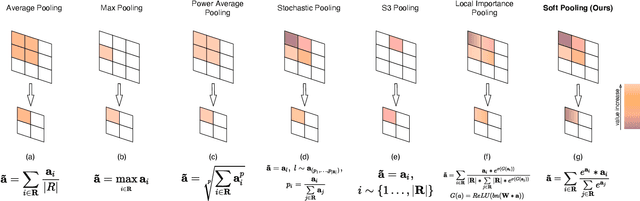
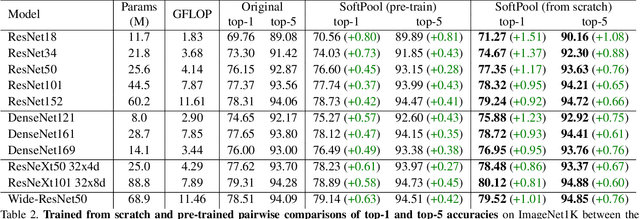
Convolutional Neural Networks (CNNs) use pooling to decrease the size of activation maps. This process is crucial to locally achieve spatial invariance and to increase the receptive field of subsequent convolutions. Pooling operations should minimize the loss of information in the activation maps. At the same time, the computation and memory overhead should be limited. To meet these requirements, we propose SoftPool: a fast and efficient method that sums exponentially weighted activations. Compared to a range of other pooling methods, SoftPool retains more information in the downsampled activation maps. More refined downsampling leads to better classification accuracy. On ImageNet1K, for a range of popular CNN architectures, replacing the original pooling operations with SoftPool leads to consistent accuracy improvements in the order of 1-2%. We also test SoftPool on video datasets for action recognition. Again, replacing only the pooling layers consistently increases accuracy while computational load and memory remain limited. These favorable properties make SoftPool an excellent replacement for current pooling operations, including max-pool and average-pool
Class Feature Pyramids for Video Explanation
Sep 18, 2019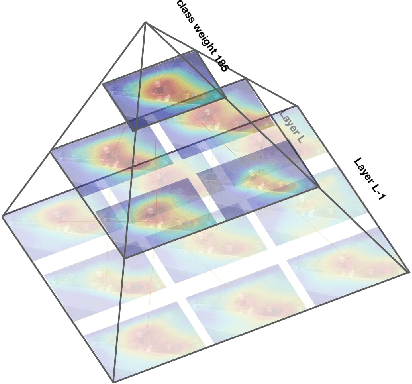
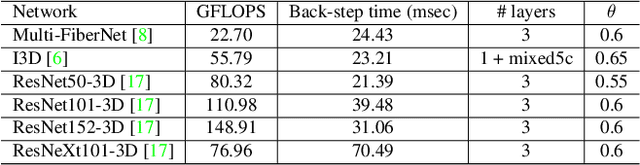
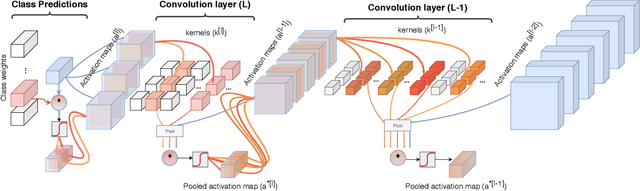
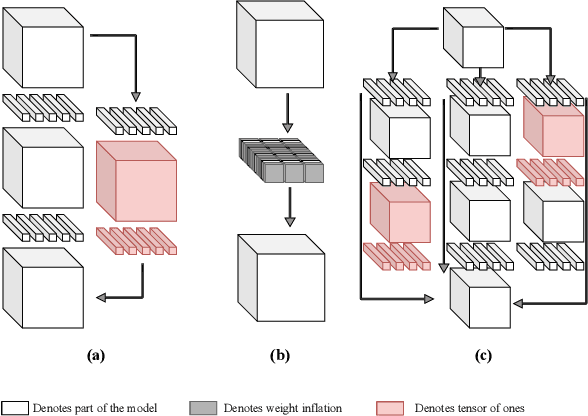
Deep convolutional networks are widely used in video action recognition. 3D convolutions are one prominent approach to deal with the additional time dimension. While 3D convolutions typically lead to higher accuracies, the inner workings of the trained models are more difficult to interpret. We focus on creating human-understandable visual explanations that represent the hierarchical parts of spatio-temporal networks. We introduce Class Feature Pyramids, a method that traverses the entire network structure and incrementally discovers kernels at different network depths that are informative for a specific class. Our method does not depend on the network's architecture or the type of 3D convolutions, supporting grouped and depth-wise convolutions, convolutions in fibers, and convolutions in branches. We demonstrate the method on six state-of-the-art 3D convolution neural networks (CNNs) on three action recognition (Kinetics-400, UCF-101, and HMDB-51) and two egocentric action recognition datasets (EPIC-Kitchens and EGTEA Gaze+).
DisplaceNet: Recognising Displaced People from Images by Exploiting Dominance Level
May 03, 2019
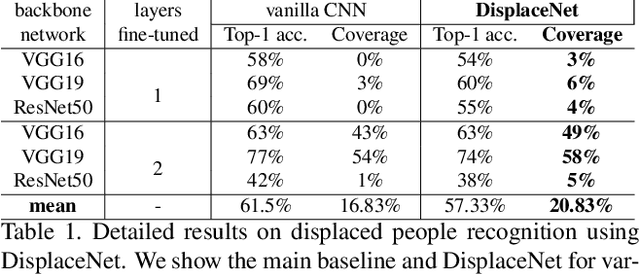


Every year millions of men, women and children are forced to leave their homes and seek refuge from wars, human rights violations, persecution, and natural disasters. The number of forcibly displaced people came at a record rate of 44,400 every day throughout 2017, raising the cumulative total to 68.5 million at the years end, overtaken the total population of the United Kingdom. Up to 85% of the forcibly displaced find refuge in low- and middle-income countries, calling for increased humanitarian assistance worldwide. To reduce the amount of manual labour required for human-rights-related image analysis, we introduce DisplaceNet, a novel model which infers potential displaced people from images by integrating the control level of the situation and conventional convolutional neural network (CNN) classifier into one framework for image classification. Experimental results show that DisplaceNet achieves up to 4% coverage-the proportion of a data set for which a classifier is able to produce a prediction-gain over the sole use of a CNN classifier. Our dataset, codes and trained models will be available online at https://github.com/GKalliatakis/DisplaceNet.
GET-AID: Visual Recognition of Human Rights Abuses via Global Emotional Traits
Feb 11, 2019


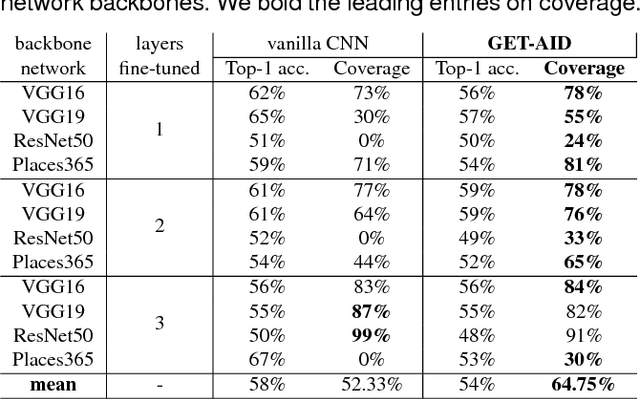
In the era of social media and big data, the use of visual evidence to document conflict and human rights abuse has become an important element for human rights organizations and advocates. In this paper, we address the task of detecting two types of human rights abuses in challenging, everyday photos: (1) child labour, and (2) displaced populations. We propose a novel model that is driven by a human-centric approach. Our hypothesis is that the emotional state of a person -- how positive or pleasant an emotion is, and the control level of the situation by the person -- are powerful cues for perceiving potential human rights violations. To exploit these cues, our model learns to predict global emotional traits over a given image based on the joint analysis of every detected person and the whole scene. By integrating these predictions with a data-driven convolutional neural network (CNN) classifier, our system efficiently infers potential human rights abuses in a clean, end-to-end system we call GET-AID (from Global Emotional Traits for Abuse IDentification). Extensive experiments are performed to verify our method on the recently introduced subset of Human Rights Archive (HRA) dataset (2 violation categories with the same number of positive and negative samples), where we show quantitatively compelling results. Compared with previous works and the sole use of a CNN classifier, this paper improves the coverage up to 23.73% for child labour and 57.21% for displaced populations. Our dataset, codes and trained models are available online at https://github.com/GKalliatakis/GET-AID.
Saliency Tubes: Visual Explanations for Spatio-Temporal Convolutions
Feb 04, 2019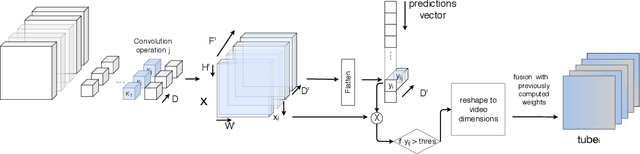

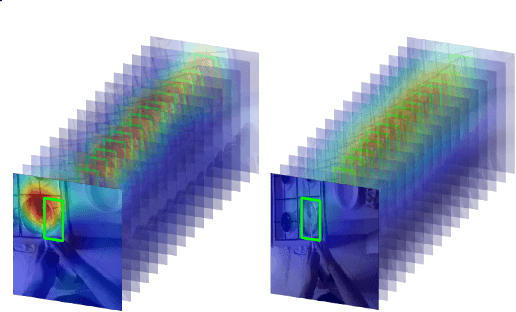
Deep learning approaches have been established as the main methodology for video classification and recognition. Recently, 3-dimensional convolutions have been used to achieve state-of-the-art performance in many challenging video datasets. Because of the high level of complexity of these methods, as the convolution operations are also extended to additional dimension in order to extract features from them as well, providing a visualization for the signals that the network interpret as informative, is a challenging task. An effective notion of understanding the network's inner-workings would be to isolate the spatio-temporal regions on the video that the network finds most informative. We propose a method called Saliency Tubes which demonstrate the foremost points and regions in both frame level and over time that are found to be the main focus points of the network. We demonstrate our findings on widely used datasets for third-person and egocentric action classification and enhance the set of methods and visualizations that improve 3D Convolutional Neural Networks (CNNs) intelligibility.
MAT-CNN-SOPC: Motionless Analysis of Traffic Using Convolutional Neural Networks on System-On-a-Programmable-Chip
Aug 14, 2018
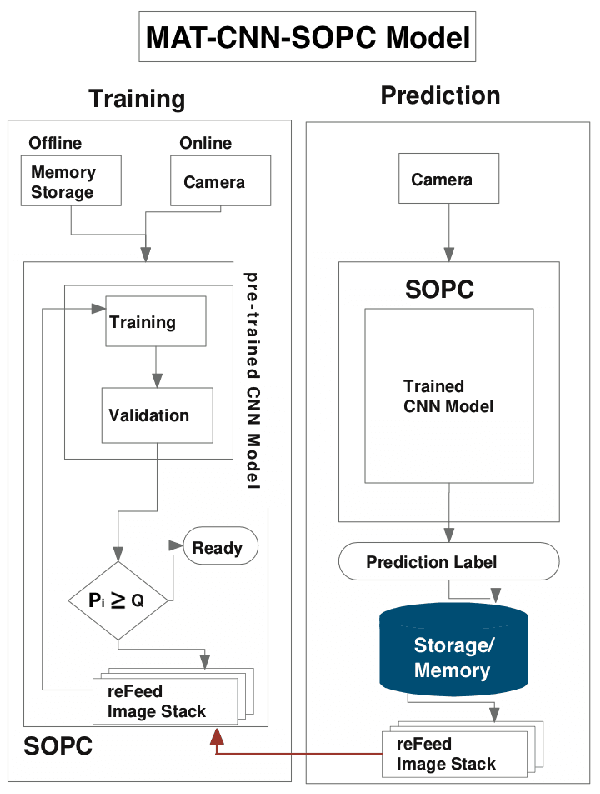
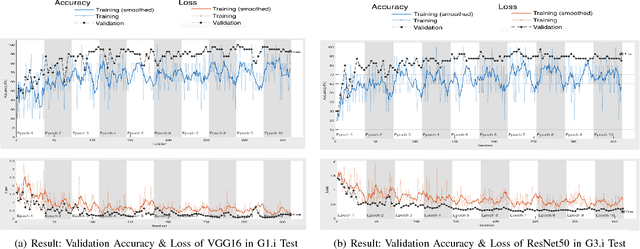
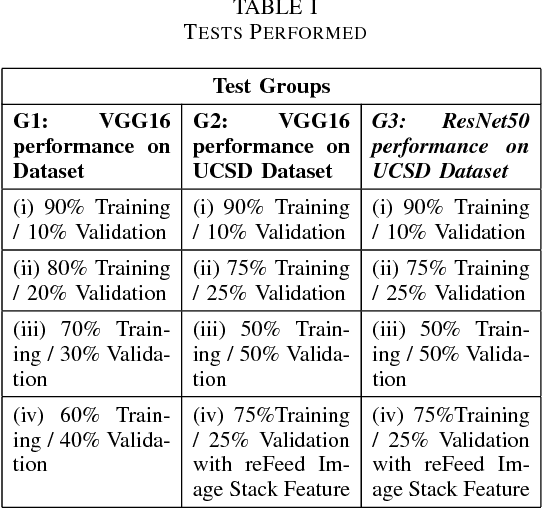
Intelligent Transportation Systems (ITS) have become an important pillar in modern "smart city" framework which demands intelligent involvement of machines. Traffic load recognition can be categorized as an important and challenging issue for such systems. Recently, Convolutional Neural Network (CNN) models have drawn considerable amount of interest in many areas such as weather classification, human rights violation detection through images, due to its accurate prediction capabilities. This work tackles real-life traffic load recognition problem on System-On-a-Programmable-Chip (SOPC) platform and coin it as MAT-CNN- SOPC, which uses an intelligent re-training mechanism of the CNN with known environments. The proposed methodology is capable of enhancing the efficacy of the approach by 2.44x in comparison to the state-of-art and proven through experimental analysis. We have also introduced a mathematical equation, which is capable of quantifying the suitability of using different CNN models over the other for a particular application based implementation.
* 6 pages, 3 figures, 2 tables
Exploring object-centric and scene-centric CNN features and their complementarity for human rights violations recognition in images
May 12, 2018


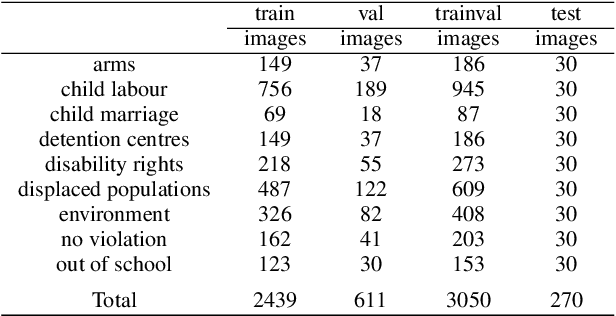
Identifying potential abuses of human rights through imagery is a novel and challenging task in the field of computer vision, that will enable to expose human rights violations over large-scale data that may otherwise be impossible. While standard databases for object and scene categorisation contain hundreds of different classes, the largest available dataset of human rights violations contains only 4 classes. Here, we introduce the `Human Rights Archive Database' (HRA), a verified-by-experts repository of 3050 human rights violations photographs, labelled with human rights semantic categories, comprising a list of the types of human rights abuses encountered at present. With the HRA dataset and a two-phase transfer learning scheme, we fine-tuned the state-of-the-art deep convolutional neural networks (CNNs) to provide human rights violations classification CNNs (HRA-CNNs). We also present extensive experiments refined to evaluate how well object-centric and scene-centric CNN features can be combined for the task of recognising human rights abuses. With this, we show that HRA database poses a challenge at a higher level for the well studied representation learning methods, and provide a benchmark in the task of human rights violations recognition in visual context. We expect this dataset can help to open up new horizons on creating systems able of recognising rich information about human rights violations. Our dataset, codes and trained models are available online at https://github.com/GKalliatakis/Human-Rights-Archive-CNNs.
Material Classification in the Wild: Do Synthesized Training Data Generalise Better than Real-World Training Data?
Nov 09, 2017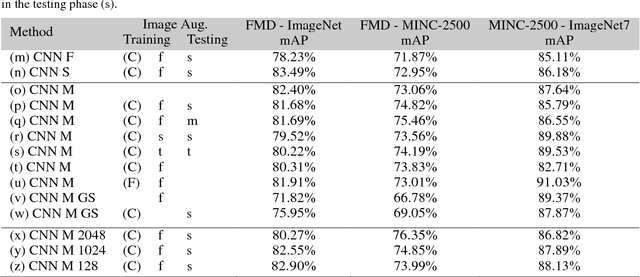
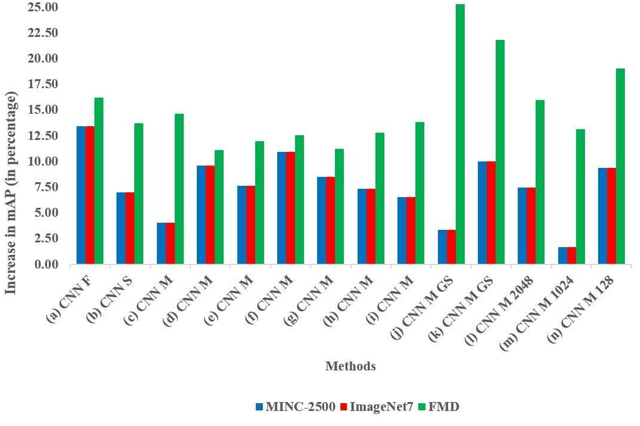
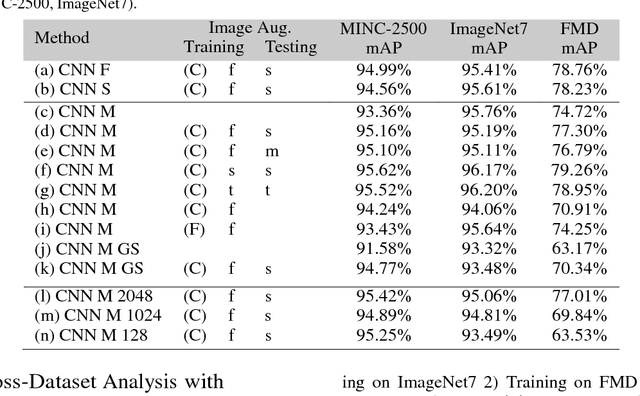
We question the dominant role of real-world training images in the field of material classification by investigating whether synthesized data can generalise more effectively than real-world data. Experimental results on three challenging real-world material databases show that the best performing pre-trained convolutional neural network (CNN) architectures can achieve up to 91.03% mean average precision when classifying materials in cross-dataset scenarios. We demonstrate that synthesized data achieve an improvement on mean average precision when used as training data and in conjunction with pre-trained CNN architectures, which spans from ~ 5% to ~ 19% across three widely used material databases of real-world images.
A Paradigm Shift: Detecting Human Rights Violations Through Web Images
Mar 30, 2017
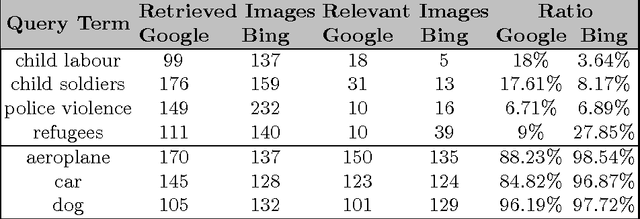


The growing presence of devices carrying digital cameras, such as mobile phones and tablets, combined with ever improving internet networks have enabled ordinary citizens, victims of human rights abuse, and participants in armed conflicts, protests, and disaster situations to capture and share via social media networks images and videos of specific events. This paper discusses the potential of images in human rights context including the opportunities and challenges they present. This study demonstrates that real-world images have the capacity to contribute complementary data to operational human rights monitoring efforts when combined with novel computer vision approaches. The analysis is concluded by arguing that if images are to be used effectively to detect and identify human rights violations by rights advocates, greater attention to gathering task-specific visual concepts from large-scale web images is required.
Detection of Human Rights Violations in Images: Can Convolutional Neural Networks help?
Mar 16, 2017
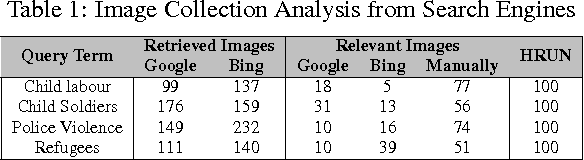
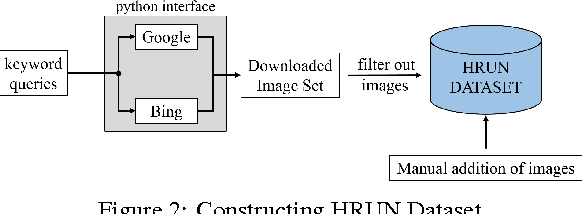
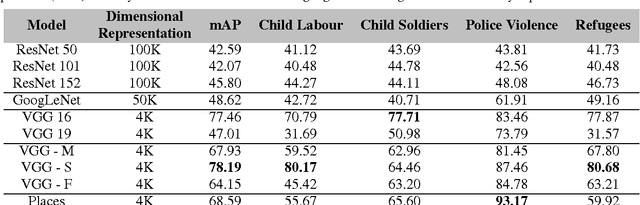
After setting the performance benchmarks for image, video, speech and audio processing, deep convolutional networks have been core to the greatest advances in image recognition tasks in recent times. This raises the question of whether there are any benefit in targeting these remarkable deep architectures with the unattempted task of recognising human rights violations through digital images. Under this perspective, we introduce a new, well-sampled human rights-centric dataset called Human Rights Understanding (HRUN). We conduct a rigorous evaluation on a common ground by combining this dataset with different state-of-the-art deep convolutional architectures in order to achieve recognition of human rights violations. Experimental results on the HRUN dataset have shown that the best performing CNN architectures can achieve up to 88.10\% mean average precision. Additionally, our experiments demonstrate that increasing the size of the training samples is crucial for achieving an improvement on mean average precision principally when utilising very deep networks.