 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoving Healthcare AI-Support Systems for Visually Detectable Diseases onto Constrained Devices
Aug 15, 2024Image classification usually requires connectivity and access to the cloud which is often limited in many parts of the world, including hard to reach rural areas. TinyML aims to solve this problem by hosting AI assistants on constrained devices, eliminating connectivity issues by processing data within the device itself, without internet or cloud access. This pilot study explores the use of tinyML to provide healthcare support with low spec devices in low connectivity environments, focusing on diagnosis of skin diseases and the ethical use of AI assistants in a healthcare setting. To investigate this, 10,000 images of skin lesions were used to train a model for classifying visually detectable diseases (VDDs). The model weights were then offloaded to a Raspberry Pi with a webcam attached, to be used for the classification of skin lesions without internet access. It was found that the developed prototype achieved a test accuracy of 78% and a test loss of 1.08.
Digital Twin-Empowered Smart Attack Detection System for 6G Edge of Things Networks
Oct 05, 2023As global Internet of Things (IoT) devices connectivity surges, a significant portion gravitates towards the Edge of Things (EoT) network. This shift prompts businesses to deploy infrastructure closer to end-users, enhancing accessibility. However, the growing EoT network expands the attack surface, necessitating robust and proactive security measures. Traditional solutions fall short against dynamic EoT threats, highlighting the need for proactive and intelligent systems. We introduce a digital twin-empowered smart attack detection system for 6G EoT networks. Leveraging digital twin and edge computing, it monitors and simulates physical assets in real time, enhancing security. An online learning module in the proposed system optimizes the network performance. Our system excels in proactive threat detection, ensuring 6G EoT network security. The performance evaluations demonstrate its effectiveness, robustness, and adaptability using real datasets.
Launching Adversarial Attacks against Network Intrusion Detection Systems for IoT
Apr 26, 2021
As the internet continues to be populated with new devices and emerging technologies, the attack surface grows exponentially. Technology is shifting towards a profit-driven Internet of Things market where security is an afterthought. Traditional defending approaches are no longer sufficient to detect both known and unknown attacks to high accuracy. Machine learning intrusion detection systems have proven their success in identifying unknown attacks with high precision. Nevertheless, machine learning models are also vulnerable to attacks. Adversarial examples can be used to evaluate the robustness of a designed model before it is deployed. Further, using adversarial examples is critical to creating a robust model designed for an adversarial environment. Our work evaluates both traditional machine learning and deep learning models' robustness using the Bot-IoT dataset. Our methodology included two main approaches. First, label poisoning, used to cause incorrect classification by the model. Second, the fast gradient sign method, used to evade detection measures. The experiments demonstrated that an attacker could manipulate or circumvent detection with significant probability.
* MDPI Mach. Learn. Knowl. Extr. 2021, 3(2), 333-356; https://www.mdpi.com/2624-800X/1/2/14
Class Feature Pyramids for Video Explanation
Sep 18, 2019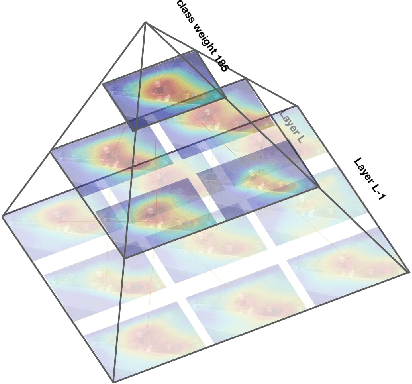
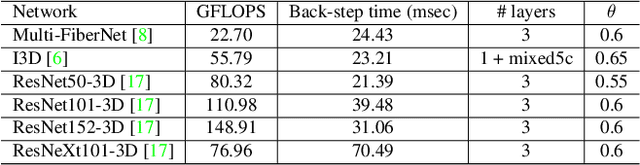
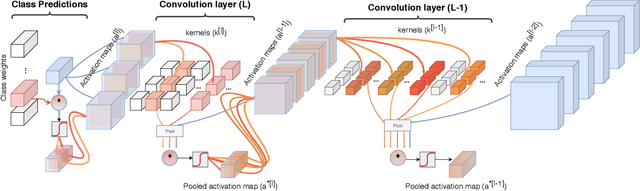
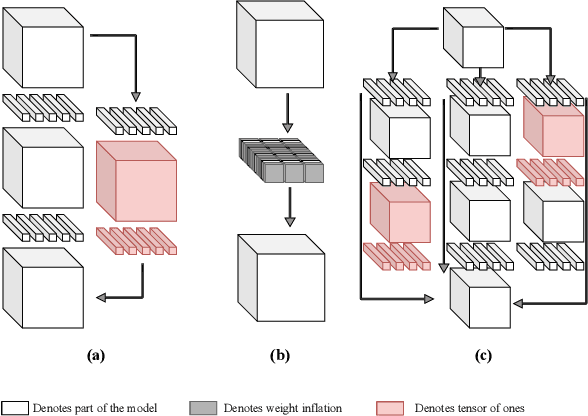
Deep convolutional networks are widely used in video action recognition. 3D convolutions are one prominent approach to deal with the additional time dimension. While 3D convolutions typically lead to higher accuracies, the inner workings of the trained models are more difficult to interpret. We focus on creating human-understandable visual explanations that represent the hierarchical parts of spatio-temporal networks. We introduce Class Feature Pyramids, a method that traverses the entire network structure and incrementally discovers kernels at different network depths that are informative for a specific class. Our method does not depend on the network's architecture or the type of 3D convolutions, supporting grouped and depth-wise convolutions, convolutions in fibers, and convolutions in branches. We demonstrate the method on six state-of-the-art 3D convolution neural networks (CNNs) on three action recognition (Kinetics-400, UCF-101, and HMDB-51) and two egocentric action recognition datasets (EPIC-Kitchens and EGTEA Gaze+).
Saliency Tubes: Visual Explanations for Spatio-Temporal Convolutions
Feb 04, 2019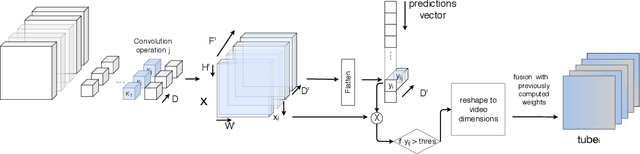

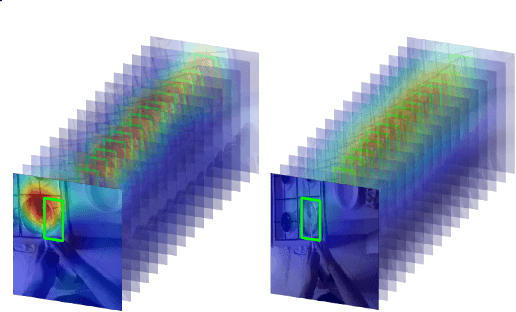
Deep learning approaches have been established as the main methodology for video classification and recognition. Recently, 3-dimensional convolutions have been used to achieve state-of-the-art performance in many challenging video datasets. Because of the high level of complexity of these methods, as the convolution operations are also extended to additional dimension in order to extract features from them as well, providing a visualization for the signals that the network interpret as informative, is a challenging task. An effective notion of understanding the network's inner-workings would be to isolate the spatio-temporal regions on the video that the network finds most informative. We propose a method called Saliency Tubes which demonstrate the foremost points and regions in both frame level and over time that are found to be the main focus points of the network. We demonstrate our findings on widely used datasets for third-person and egocentric action classification and enhance the set of methods and visualizations that improve 3D Convolutional Neural Networks (CNNs) intelligibility.