 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaunching Adversarial Attacks against Network Intrusion Detection Systems for IoT
Apr 26, 2021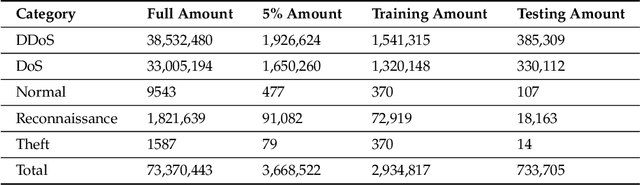
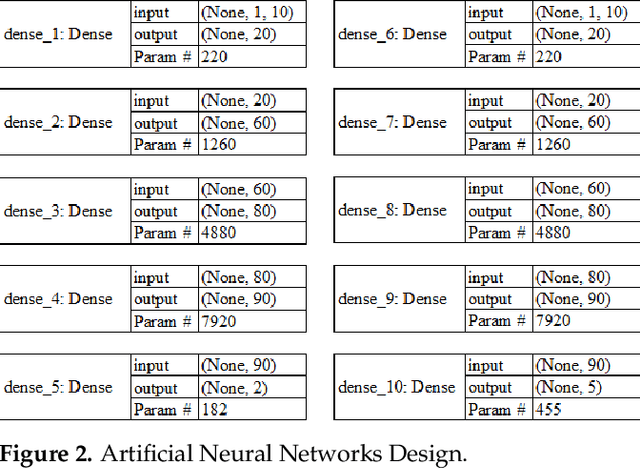
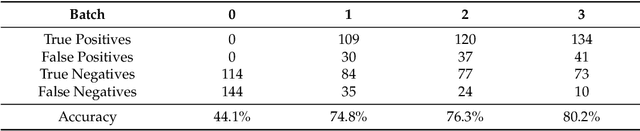
As the internet continues to be populated with new devices and emerging technologies, the attack surface grows exponentially. Technology is shifting towards a profit-driven Internet of Things market where security is an afterthought. Traditional defending approaches are no longer sufficient to detect both known and unknown attacks to high accuracy. Machine learning intrusion detection systems have proven their success in identifying unknown attacks with high precision. Nevertheless, machine learning models are also vulnerable to attacks. Adversarial examples can be used to evaluate the robustness of a designed model before it is deployed. Further, using adversarial examples is critical to creating a robust model designed for an adversarial environment. Our work evaluates both traditional machine learning and deep learning models' robustness using the Bot-IoT dataset. Our methodology included two main approaches. First, label poisoning, used to cause incorrect classification by the model. Second, the fast gradient sign method, used to evade detection measures. The experiments demonstrated that an attacker could manipulate or circumvent detection with significant probability.
* MDPI Mach. Learn. Knowl. Extr. 2021, 3(2), 333-356; https://www.mdpi.com/2624-800X/1/2/14
Privacy and Trust Redefined in Federated Machine Learning
Mar 30, 2021
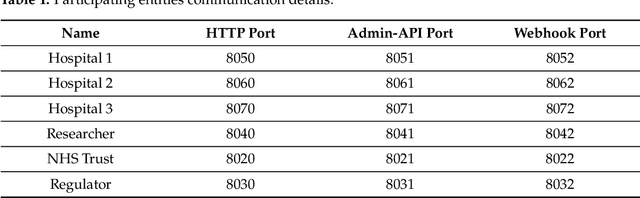
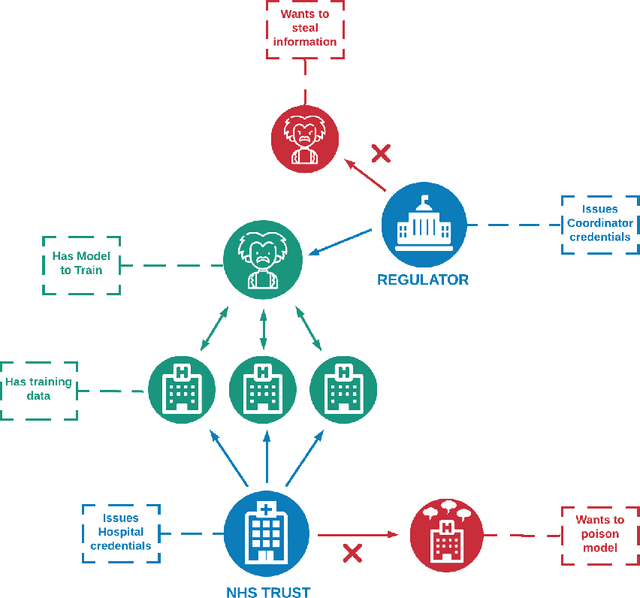
A common privacy issue in traditional machine learning is that data needs to be disclosed for the training procedures. In situations with highly sensitive data such as healthcare records, accessing this information is challenging and often prohibited. Luckily, privacy-preserving technologies have been developed to overcome this hurdle by distributing the computation of the training and ensuring the data privacy to their owners. The distribution of the computation to multiple participating entities introduces new privacy complications and risks. In this paper, we present a privacy-preserving decentralised workflow that facilitates trusted federated learning among participants. Our proof-of-concept defines a trust framework instantiated using decentralised identity technologies being developed under Hyperledger projects Aries/Indy/Ursa. Only entities in possession of Verifiable Credentials issued from the appropriate authorities are able to establish secure, authenticated communication channels authorised to participate in a federated learning workflow related to mental health data.
* MDPI Mach. Learn. Knowl. Extr. 2021, 3(2), 333-356; https://doi.org/10.3390/make3020017
An Experimental Analysis of Attack Classification Using Machine Learning in IoT Networks
Jan 10, 2021

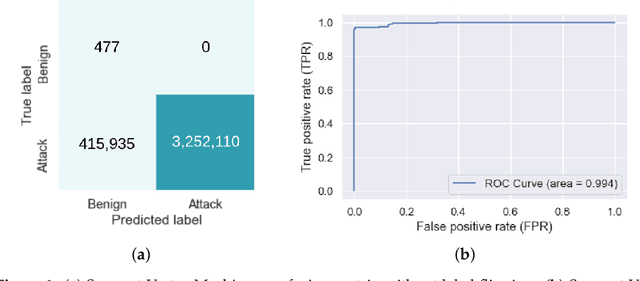
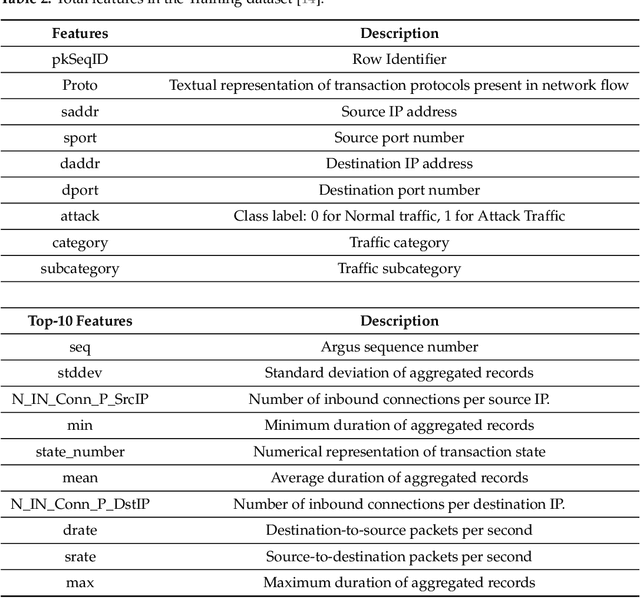
In recent years, there has been a massive increase in the amount of Internet of Things (IoT) devices as well as the data generated by such devices. The participating devices in IoT networks can be problematic due to their resource-constrained nature, and integrating security on these devices is often overlooked. This has resulted in attackers having an increased incentive to target IoT devices. As the number of attacks possible on a network increases, it becomes more difficult for traditional intrusion detection systems (IDS) to cope with these attacks efficiently. In this paper, we highlight several machine learning (ML) methods such as k-nearest neighbour (KNN), support vector machine (SVM), decision tree (DT), naive Bayes (NB), random forest (RF), artificial neural network (ANN), and logistic regression (LR) that can be used in IDS. In this work, ML algorithms are compared for both binary and multi-class classification on Bot-IoT dataset. Based on several parameters such as accuracy, precision, recall, F1 score, and log loss, we experimentally compared the aforementioned ML algorithms. In the case of HTTP distributed denial-of-service (DDoS) attack, the accuracy of RF is 99%. Furthermore, other simulation results-based precision, recall, F1 score, and log loss metric reveal that RF outperforms on all types of attacks in binary classification. However, in multi-class classification, KNN outperforms other ML algorithms with an accuracy of 99%, which is 4% higher than RF.
Phishing URL Detection Through Top-level Domain Analysis: A Descriptive Approach
May 13, 2020
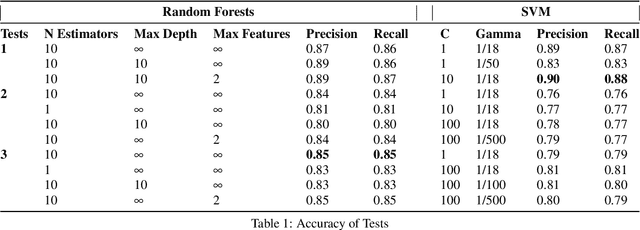
Phishing is considered to be one of the most prevalent cyber-attacks because of its immense flexibility and alarmingly high success rate. Even with adequate training and high situational awareness, it can still be hard for users to continually be aware of the URL of the website they are visiting. Traditional detection methods rely on blocklists and content analysis, both of which require time-consuming human verification. Thus, there have been attempts focusing on the predictive filtering of such URLs. This study aims to develop a machine-learning model to detect fraudulent URLs which can be used within the Splunk platform. Inspired from similar approaches in the literature, we trained the SVM and Random Forests algorithms using malicious and benign datasets found in the literature and one dataset that we created. We evaluated the algorithms' performance with precision and recall, reaching up to 85% precision and 87% recall in the case of Random Forests while SVM achieved up to 90% precision and 88% recall using only descriptive features.
* In Proceedings of the 6th ICISSP