 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNash Equilibrium Between Consumer Electronic Devices and DoS Attacker for Distributed IoT-enabled RSE Systems
Apr 13, 2025In electronic consumer Internet of Things (IoT), consumer electronic devices as edge devices require less computational overhead and the remote state estimation (RSE) of consumer electronic devices is always at risk of denial-of-service (DoS) attacks. Therefore, the adversarial strategy between consumer electronic devices and DoS attackers is critical. This paper focuses on the adversarial strategy between consumer electronic devices and DoS attackers in IoT-enabled RSE Systems. We first propose a remote joint estimation model for distributed measurements to effectively reduce consumer electronic device workload and minimize data leakage risks. The Kalman filter is deployed on the remote estimator, and the DoS attacks with open-loop as well as closed-loop are considered. We further introduce advanced reinforcement learning techniques, including centralized and distributed Minimax-DQN, to address high-dimensional decision-making challenges in both open-loop and closed-loop scenarios. Especially, the Q-network instead of the Q-table is used in the proposed approaches, which effectively solves the challenge of Q-learning. Moreover, the proposed distributed Minimax-DQN reduces the action space to expedite the search for Nash Equilibrium (NE). The experimental results validate that the proposed model can expeditiously restore the RSE error covariance to a stable state in the presence of DoS attacks, exhibiting notable attack robustness. The proposed centralized and distributed Minimax-DQN effectively resolves the NE in both open and closed-loop case, showcasing remarkable performance in terms of convergence. It reveals that substantial advantages in both efficiency and stability are achieved compared with the state-of-the-art methods.
Efficient IoT Intrusion Detection with an Improved Attention-Based CNN-BiLSTM Architecture
Mar 25, 2025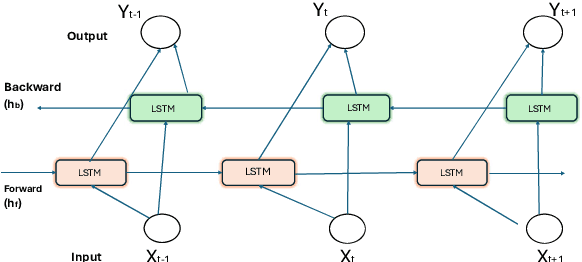
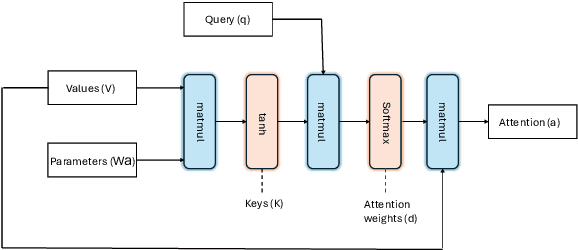


The ever-increasing security vulnerabilities in the Internet-of-Things (IoT) systems require improved threat detection approaches. This paper presents a compact and efficient approach to detect botnet attacks by employing an integrated approach that consists of traffic pattern analysis, temporal support learning, and focused feature extraction. The proposed attention-based model benefits from a hybrid CNN-BiLSTM architecture and achieves 99% classification accuracy in detecting botnet attacks utilizing the N-BaIoT dataset, while maintaining high precision and recall across various scenarios. The proposed model's performance is further validated by key parameters, such as Mathews Correlation Coefficient and Cohen's kappa Correlation Coefficient. The close-to-ideal results for these parameters demonstrate the proposed model's ability to detect botnet attacks accurately and efficiently in practical settings and on unseen data. The proposed model proved to be a powerful defense mechanism for IoT networks to face emerging security challenges.
A Single Channel-Based Neonatal Sleep-Wake Classification using Hjorth Parameters and Improved Gradient Boosting
Aug 15, 2024Sleep plays a crucial role in neonatal development. Monitoring the sleep patterns in neonates in a Neonatal Intensive Care Unit (NICU) is imperative for understanding the maturation process. While polysomnography (PSG) is considered the best practice for sleep classification, its expense and reliance on human annotation pose challenges. Existing research often relies on multichannel EEG signals; however, concerns arise regarding the vulnerability of neonates and the potential impact on their sleep quality. This paper introduces a novel approach to neonatal sleep stage classification using a single-channel gradient boosting algorithm with Hjorth features. The gradient boosting parameters are fine-tuned using random search cross-validation (randomsearchCV), achieving an accuracy of 82.35% for neonatal sleep-wake classification. Validation is conducted through 5-fold cross-validation. The proposed algorithm not only enhances existing neonatal sleep algorithms but also opens avenues for broader applications.
Contactless Human Activity Recognition using Deep Learning with Flexible and Scalable Software Define Radio
Apr 18, 2023Ambient computing is gaining popularity as a major technological advancement for the future. The modern era has witnessed a surge in the advancement in healthcare systems, with viable radio frequency solutions proposed for remote and unobtrusive human activity recognition (HAR). Specifically, this study investigates the use of Wi-Fi channel state information (CSI) as a novel method of ambient sensing that can be employed as a contactless means of recognizing human activity in indoor environments. These methods avoid additional costly hardware required for vision-based systems, which are privacy-intrusive, by (re)using Wi-Fi CSI for various safety and security applications. During an experiment utilizing universal software-defined radio (USRP) to collect CSI samples, it was observed that a subject engaged in six distinct activities, which included no activity, standing, sitting, and leaning forward, across different areas of the room. Additionally, more CSI samples were collected when the subject walked in two different directions. This study presents a Wi-Fi CSI-based HAR system that assesses and contrasts deep learning approaches, namely convolutional neural network (CNN), long short-term memory (LSTM), and hybrid (LSTM+CNN), employed for accurate activity recognition. The experimental results indicate that LSTM surpasses current models and achieves an average accuracy of 95.3% in multi-activity classification when compared to CNN and hybrid techniques. In the future, research needs to study the significance of resilience in diverse and dynamic environments to identify the activity of multiple users.
A Novel Chaos-based Light-weight Image Encryption Scheme for Multi-modal Hearing Aids
Feb 11, 2022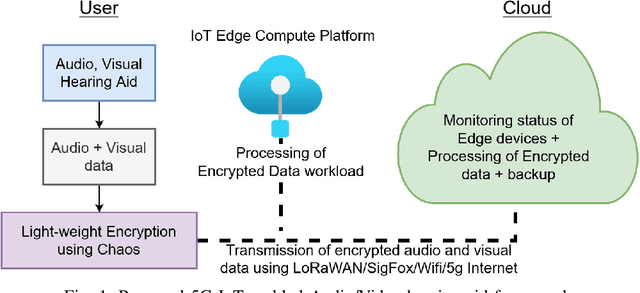

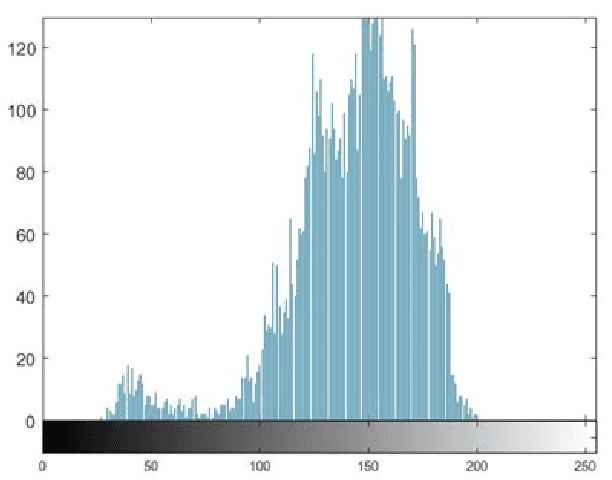
Multimodal hearing aids (HAs) aim to deliver more intelligible audio in noisy environments by contextually sensing and processing data in the form of not only audio but also visual information (e.g. lip reading). Machine learning techniques can play a pivotal role for the contextually processing of multimodal data. However, since the computational power of HA devices is low, therefore this data must be processed either on the edge or cloud which, in turn, poses privacy concerns for sensitive user data. Existing literature proposes several techniques for data encryption but their computational complexity is a major bottleneck to meet strict latency requirements for development of future multi-modal hearing aids. To overcome this problem, this paper proposes a novel real-time audio/visual data encryption scheme based on chaos-based encryption using the Tangent-Delay Ellipse Reflecting Cavity-Map System (TD-ERCS) map and Non-linear Chaotic (NCA) Algorithm. The results achieved against different security parameters, including Correlation Coefficient, Unified Averaged Changed Intensity (UACI), Key Sensitivity Analysis, Number of Changing Pixel Rate (NPCR), Mean-Square Error (MSE), Peak Signal to Noise Ratio (PSNR), Entropy test, and Chi-test, indicate that the newly proposed scheme is more lightweight due to its lower execution time as compared to existing schemes and more secure due to increased key-space against modern brute-force attacks.
GuideMe: A Mobile Application based on Global Positioning System and Object Recognition Towards a Smart Tourist Guide
May 27, 2021



Finding information about tourist places to visit is a challenging problem that people face while visiting different countries. This problem is accentuated when people are coming from different countries, speak different languages, and are from all segments of society. In this context, visitors and pilgrims face important problems to find the appropriate doaas when visiting holy places. In this paper, we propose a mobile application that helps the user find the appropriate doaas for a given holy place in an easy and intuitive manner. Three different options are developed to achieve this goal: 1) manual search, 2) GPS location to identify the holy places and therefore their corresponding doaas, and 3) deep learning (DL) based method to determine the holy place by analyzing an image taken by the visitor. Experiments show good performance of the proposed mobile application in providing the appropriate doaas for visited holy places.
A Novel CNN-LSTM-based Approach to Predict Urban Expansion
Mar 02, 2021Time-series remote sensing data offer a rich source of information that can be used in a wide range of applications, from monitoring changes in land cover to surveilling crops, coastal changes, flood risk assessment, and urban sprawl. This paper addresses the challenge of using time-series satellite images to predict urban expansion. Building upon previous work, we propose a novel two-step approach based on semantic image segmentation in order to predict urban expansion. The first step aims to extract information about urban regions at different time scales and prepare them for use in the training step. The second step combines Convolutional Neural Networks (CNN) with Long Short Term Memory (LSTM) methods in order to learn temporal features and thus predict urban expansion. In this paper, experimental results are conducted using several multi-date satellite images representing the three largest cities in Saudi Arabia, namely: Riyadh, Jeddah, and Dammam. We empirically evaluated our proposed technique, and examined its results by comparing them with state-of-the-art approaches. Following this evaluation, we determined that our results reveal improved performance for the new-coupled CNN-LSTM approach, particularly in terms of assessments based on Mean Square Error, Root Mean Square Error, Peak Signal to Noise Ratio, Structural Similarity Index, and overall classification accuracy.
An Experimental Analysis of Attack Classification Using Machine Learning in IoT Networks
Jan 10, 2021

In recent years, there has been a massive increase in the amount of Internet of Things (IoT) devices as well as the data generated by such devices. The participating devices in IoT networks can be problematic due to their resource-constrained nature, and integrating security on these devices is often overlooked. This has resulted in attackers having an increased incentive to target IoT devices. As the number of attacks possible on a network increases, it becomes more difficult for traditional intrusion detection systems (IDS) to cope with these attacks efficiently. In this paper, we highlight several machine learning (ML) methods such as k-nearest neighbour (KNN), support vector machine (SVM), decision tree (DT), naive Bayes (NB), random forest (RF), artificial neural network (ANN), and logistic regression (LR) that can be used in IDS. In this work, ML algorithms are compared for both binary and multi-class classification on Bot-IoT dataset. Based on several parameters such as accuracy, precision, recall, F1 score, and log loss, we experimentally compared the aforementioned ML algorithms. In the case of HTTP distributed denial-of-service (DDoS) attack, the accuracy of RF is 99%. Furthermore, other simulation results-based precision, recall, F1 score, and log loss metric reveal that RF outperforms on all types of attacks in binary classification. However, in multi-class classification, KNN outperforms other ML algorithms with an accuracy of 99%, which is 4% higher than RF.
Deep Learning Techniques for Future Intelligent Cross-Media Retrieval
Jul 21, 2020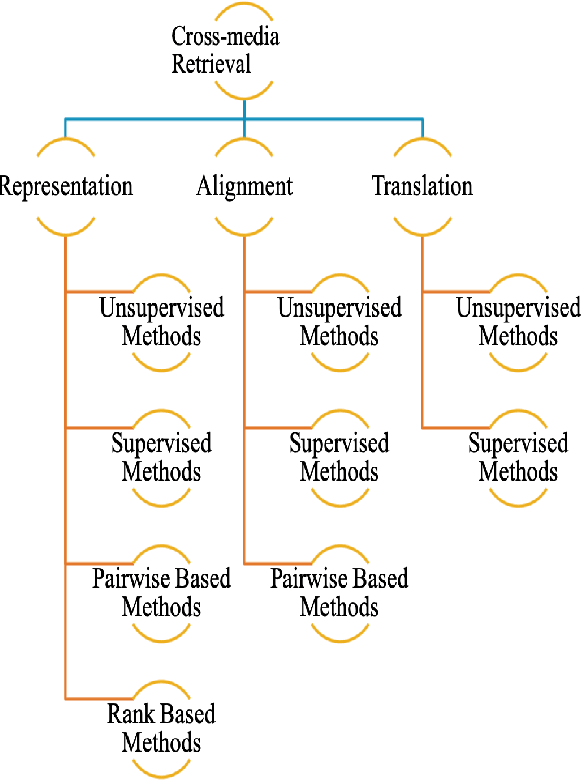



With the advancement in technology and the expansion of broadcasting, cross-media retrieval has gained much attention. It plays a significant role in big data applications and consists in searching and finding data from different types of media. In this paper, we provide a novel taxonomy according to the challenges faced by multi-modal deep learning approaches in solving cross-media retrieval, namely: representation, alignment, and translation. These challenges are evaluated on deep learning (DL) based methods, which are categorized into four main groups: 1) unsupervised methods, 2) supervised methods, 3) pairwise based methods, and 4) rank based methods. Then, we present some well-known cross-media datasets used for retrieval, considering the importance of these datasets in the context in of deep learning based cross-media retrieval approaches. Moreover, we also present an extensive review of the state-of-the-art problems and its corresponding solutions for encouraging deep learning in cross-media retrieval. The fundamental objective of this work is to exploit Deep Neural Networks (DNNs) for bridging the "media gap", and provide researchers and developers with a better understanding of the underlying problems and the potential solutions of deep learning assisted cross-media retrieval. To the best of our knowledge, this is the first comprehensive survey to address cross-media retrieval under deep learning methods.