 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Environmental Preference Based Speech Enhancement For Individualised Multi-Modal Hearing Aids
Feb 26, 2024



Since the advent of Deep Learning (DL), Speech Enhancement (SE) models have performed well under a variety of noise conditions. However, such systems may still introduce sonic artefacts, sound unnatural, and restrict the ability for a user to hear ambient sound which may be of importance. Hearing Aid (HA) users may wish to customise their SE systems to suit their personal preferences and day-to-day lifestyle. In this paper, we introduce a preference learning based SE (PLSE) model for future multi-modal HAs that can contextually exploit audio information to improve listening comfort, based upon the preferences of the user. The proposed system estimates the Signal-to-noise ratio (SNR) as a basic objective speech quality measure which quantifies the relative amount of background noise present in speech, and directly correlates to the intelligibility of the signal. Additionally, to provide contextual information we predict the acoustic scene in which the user is situated. These tasks are achieved via a multi-task DL model, which surpasses the performance of inferring the acoustic scene or SNR separately, by jointly leveraging a shared encoded feature space. These environmental inferences are exploited in a preference elicitation framework, which linearly learns a set of predictive functions to determine the target SNR of an AV (Audio-Visual) SE system. By greatly reducing noise in challenging listening conditions, and by novelly scaling the output of the SE model, we are able to provide HA users with contextually individualised SE. Preliminary results suggest an improvement over the non-individualised baseline model in some participants.
Audio-Visual Speech Enhancement in Noisy Environments via Emotion-Based Contextual Cues
Feb 26, 2024


In real-world environments, background noise significantly degrades the intelligibility and clarity of human speech. Audio-visual speech enhancement (AVSE) attempts to restore speech quality, but existing methods often fall short, particularly in dynamic noise conditions. This study investigates the inclusion of emotion as a novel contextual cue within AVSE, hypothesizing that incorporating emotional understanding can improve speech enhancement performance. We propose a novel emotion-aware AVSE system that leverages both auditory and visual information. It extracts emotional features from the facial landmarks of the speaker and fuses them with corresponding audio and visual modalities. This enriched data serves as input to a deep UNet-based encoder-decoder network, specifically designed to orchestrate the fusion of multimodal information enhanced with emotion. The network iteratively refines the enhanced speech representation through an encoder-decoder architecture, guided by perceptually-inspired loss functions for joint learning and optimization. We train and evaluate the model on the CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI) dataset, a rich repository of audio-visual recordings with annotated emotions. Our comprehensive evaluation demonstrates the effectiveness of emotion as a contextual cue for AVSE. By integrating emotional features, the proposed system achieves significant improvements in both objective and subjective assessments of speech quality and intelligibility, especially in challenging noise environments. Compared to baseline AVSE and audio-only speech enhancement systems, our approach exhibits a noticeable increase in PESQ and STOI, indicating higher perceptual quality and intelligibility. Large-scale listening tests corroborate these findings, suggesting improved human understanding of enhanced speech.
Audio-Visual Speech Enhancement and Separation by Leveraging Multi-Modal Self-Supervised Embeddings
Oct 31, 2022



AV-HuBERT, a multi-modal self-supervised learning model, has been shown to be effective for categorical problems such as automatic speech recognition and lip-reading. This suggests that useful audio-visual speech representations can be obtained via utilizing multi-modal self-supervised embeddings. Nevertheless, it is unclear if such representations can be generalized to solve real-world multi-modal AV regression tasks, such as audio-visual speech enhancement (AVSE) and audio-visual speech separation (AVSS). In this study, we leveraged the pre-trained AV-HuBERT model followed by an SE module for AVSE and AVSS. Comparative experimental results demonstrate that our proposed model performs better than the state-of-the-art AVSE and traditional audio-only SE models. In summary, our results confirm the effectiveness of our proposed model for the AVSS task with proper fine-tuning strategies, demonstrating that multi-modal self-supervised embeddings obtained from AV-HUBERT can be generalized to audio-visual regression tasks.
A Speech Intelligibility Enhancement Model based on Canonical Correlation and Deep Learning for Hearing-Assistive Technologies
Feb 15, 2022
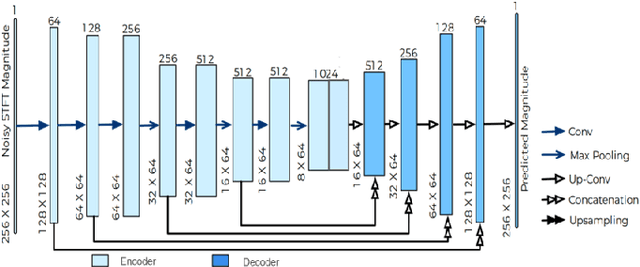
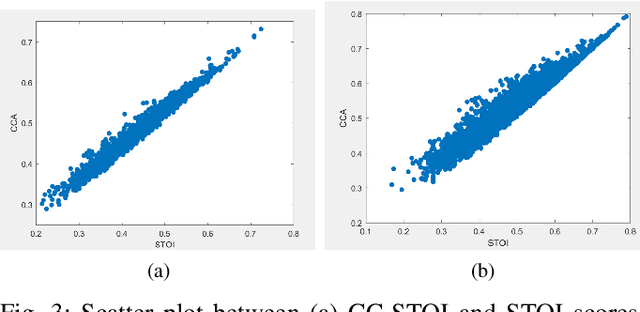
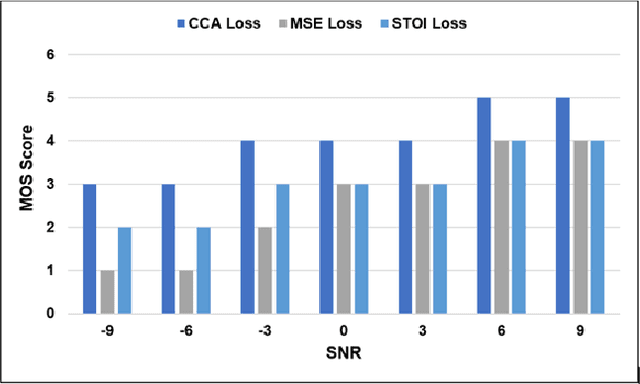
Current deep learning (DL) based approaches to speech intelligibility enhancement in noisy environments are generally trained to minimise the distance between clean and enhanced speech features. These often result in improved speech quality however they suffer from a lack of generalisation and may not deliver the required speech intelligibility in everyday noisy situations. In an attempt to address these challenges, researchers have explored intelligibility-oriented (I-O) loss functions to train DL approaches for robust speech enhancement (SE). In this paper, we formulate a novel canonical correlation-based I-O loss function to more effectively train DL algorithms. Specifically, we present a fully convolutional SE model that uses a modified canonical-correlation based short-time objective intelligibility (CC-STOI) metric as a training cost function. To the best of our knowledge, this is the first work that exploits the integration of canonical correlation in an I-O based loss function for SE. Comparative experimental results demonstrate that our proposed CC-STOI based SE framework outperforms DL models trained with conventional STOI and distance-based loss functions, in terms of both standard objective and subjective evaluation measures when dealing with unseen speakers and noises.
A Novel Speech Intelligibility Enhancement Model based on CanonicalCorrelation and Deep Learning
Feb 11, 2022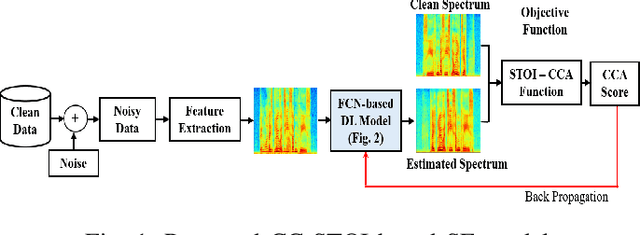

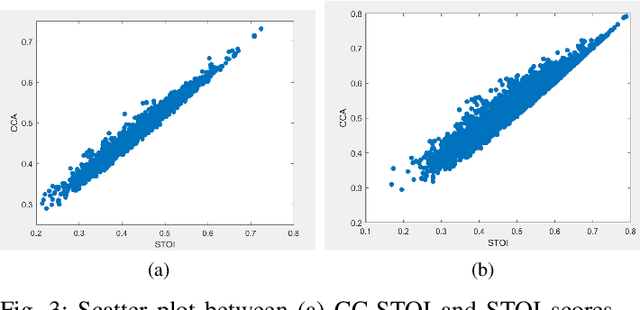
Current deep learning (DL) based approaches to speech intelligibility enhancement in noisy environments are often trained to minimise the feature distance between noise-free speech and enhanced speech signals. Despite improving the speech quality, such approaches do not deliver required levels of speech intelligibility in everyday noisy environments . Intelligibility-oriented (I-O) loss functions have recently been developed to train DL approaches for robust speech enhancement. Here, we formulate, for the first time, a novel canonical correlation based I-O loss function to more effectively train DL algorithms. Specifically, we present a canonical-correlation based short-time objective intelligibility (CC-STOI) cost function to train a fully convolutional neural network (FCN) model. We carry out comparative simulation experiments to show that our CC-STOI based speech enhancement framework outperforms state-of-the-art DL models trained with conventional distance-based and STOI-based loss functions, using objective and subjective evaluation measures for case of both unseen speakers and noises. Ongoing future work is evaluating the proposed approach for design of robust hearing-assistive technology.
A Novel Chaos-based Light-weight Image Encryption Scheme for Multi-modal Hearing Aids
Feb 11, 2022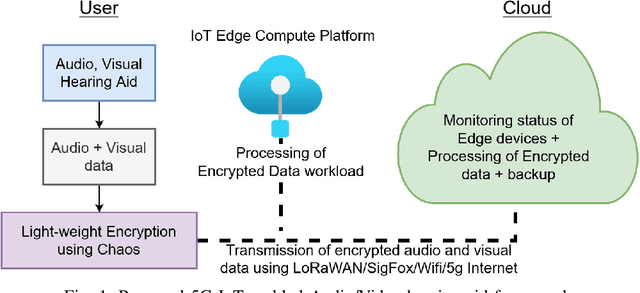

Multimodal hearing aids (HAs) aim to deliver more intelligible audio in noisy environments by contextually sensing and processing data in the form of not only audio but also visual information (e.g. lip reading). Machine learning techniques can play a pivotal role for the contextually processing of multimodal data. However, since the computational power of HA devices is low, therefore this data must be processed either on the edge or cloud which, in turn, poses privacy concerns for sensitive user data. Existing literature proposes several techniques for data encryption but their computational complexity is a major bottleneck to meet strict latency requirements for development of future multi-modal hearing aids. To overcome this problem, this paper proposes a novel real-time audio/visual data encryption scheme based on chaos-based encryption using the Tangent-Delay Ellipse Reflecting Cavity-Map System (TD-ERCS) map and Non-linear Chaotic (NCA) Algorithm. The results achieved against different security parameters, including Correlation Coefficient, Unified Averaged Changed Intensity (UACI), Key Sensitivity Analysis, Number of Changing Pixel Rate (NPCR), Mean-Square Error (MSE), Peak Signal to Noise Ratio (PSNR), Entropy test, and Chi-test, indicate that the newly proposed scheme is more lightweight due to its lower execution time as compared to existing schemes and more secure due to increased key-space against modern brute-force attacks.
A Novel Temporal Attentive-Pooling based Convolutional Recurrent Architecture for Acoustic Signal Enhancement
Jan 24, 2022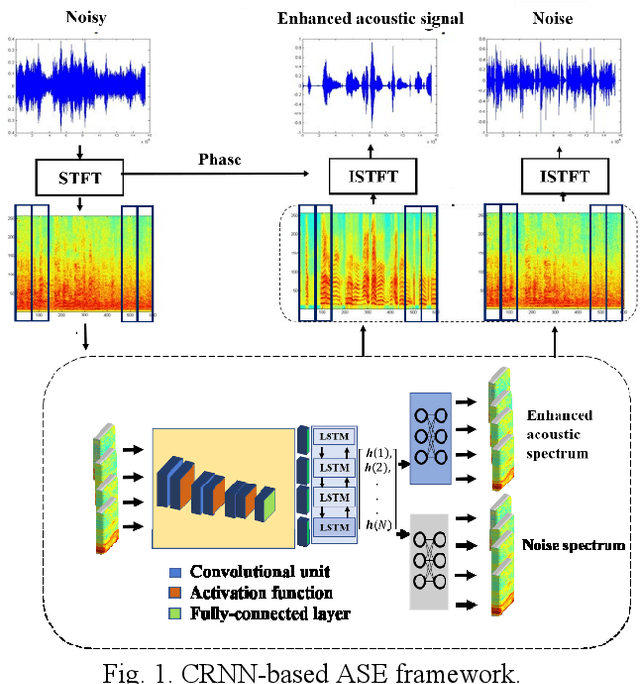
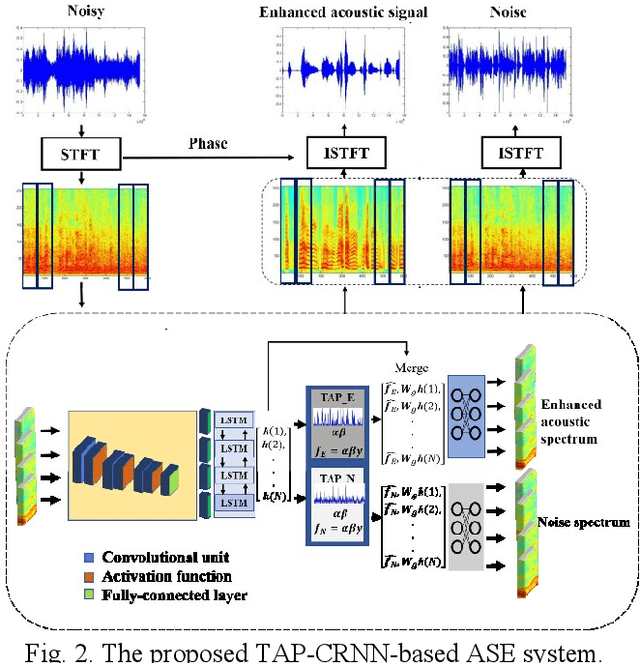
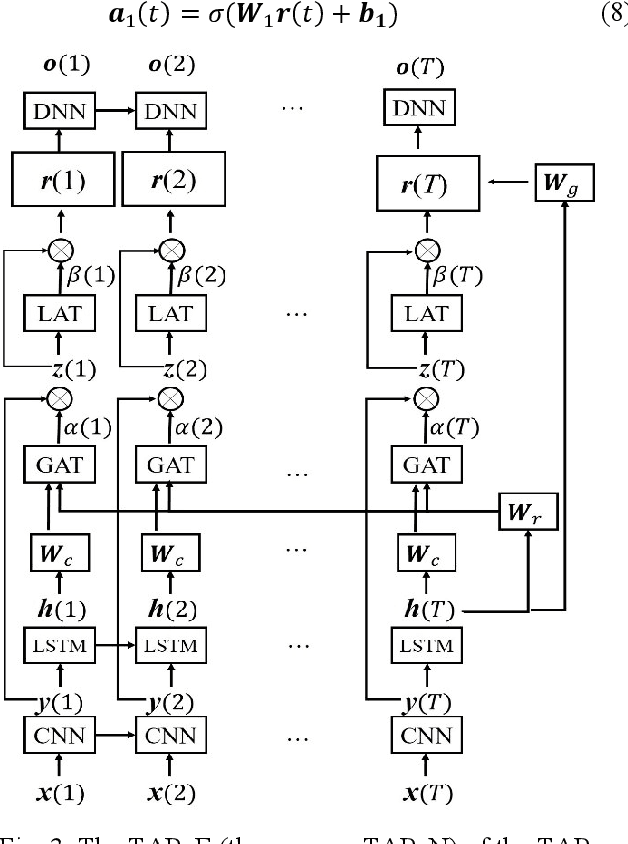
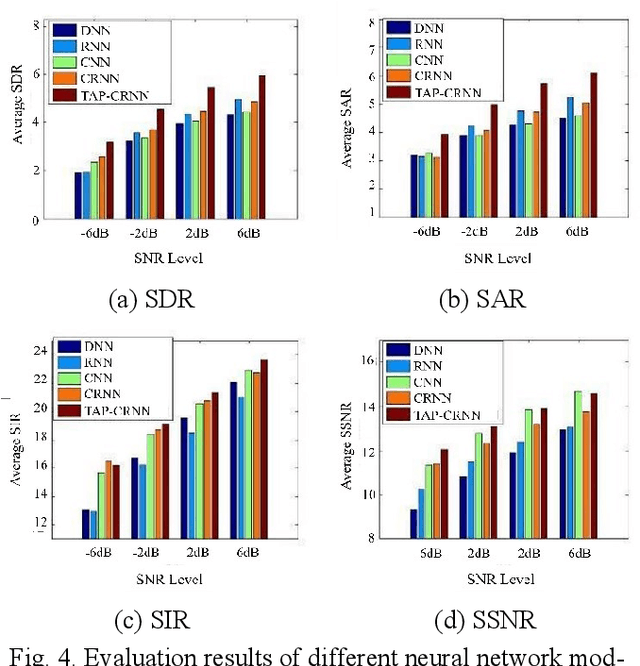
In acoustic signal processing, the target signals usually carry semantic information, which is encoded in a hierarchal structure of short and long-term contexts. However, the background noise distorts these structures in a nonuniform way. The existing deep acoustic signal enhancement (ASE) architectures ignore this kind of local and global effect. To address this problem, we propose to integrate a novel temporal attentive-pooling (TAP) mechanism into a conventional convolutional recurrent neural network, termed as TAP-CRNN. The proposed approach considers both global and local attention for ASE tasks. Specifically, we first utilize a convolutional layer to extract local information of the acoustic signals and then a recurrent neural network (RNN) architecture is used to characterize temporal contextual information. Second, we exploit a novelattention mechanism to contextually process salient regions of the noisy signals. The proposed ASE system is evaluated using a benchmark infant cry dataset and compared with several well-known methods. It is shown that the TAPCRNN can more effectively reduce noise components from infant cry signals in unseen background noises at challenging signal-to-noise levels.
Towards Intelligibility-Oriented Audio-Visual Speech Enhancement
Nov 18, 2021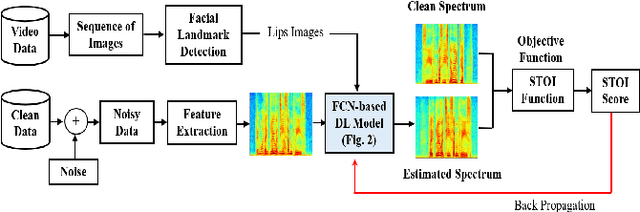
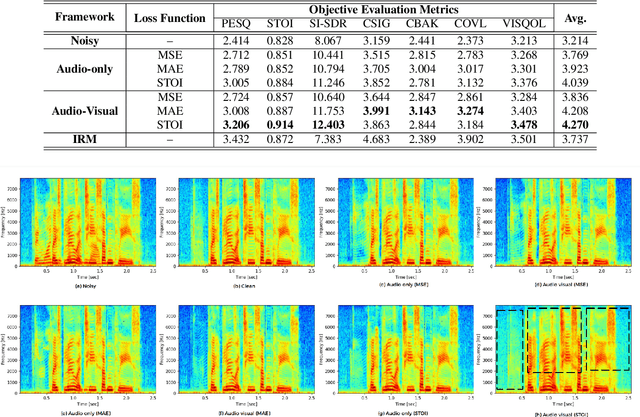
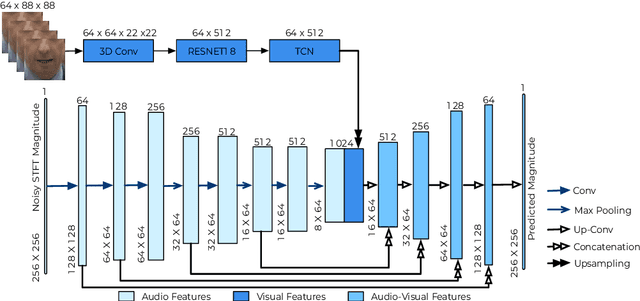
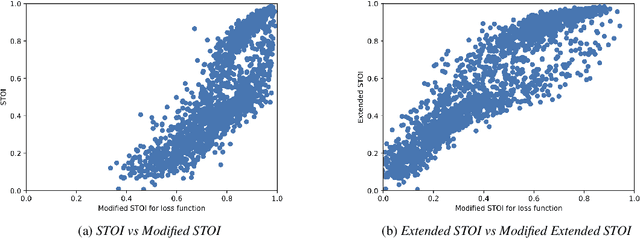
Existing deep learning (DL) based speech enhancement approaches are generally optimised to minimise the distance between clean and enhanced speech features. These often result in improved speech quality however they suffer from a lack of generalisation and may not deliver the required speech intelligibility in real noisy situations. In an attempt to address these challenges, researchers have explored intelligibility-oriented (I-O) loss functions and integration of audio-visual (AV) information for more robust speech enhancement (SE). In this paper, we introduce DL based I-O SE algorithms exploiting AV information, which is a novel and previously unexplored research direction. Specifically, we present a fully convolutional AV SE model that uses a modified short-time objective intelligibility (STOI) metric as a training cost function. To the best of our knowledge, this is the first work that exploits the integration of AV modalities with an I-O based loss function for SE. Comparative experimental results demonstrate that our proposed I-O AV SE framework outperforms audio-only (AO) and AV models trained with conventional distance-based loss functions, in terms of standard objective evaluation measures when dealing with unseen speakers and noises.
An Audio-Based Deep Learning Framework ForBBC Television Programme Classification
Apr 02, 2021
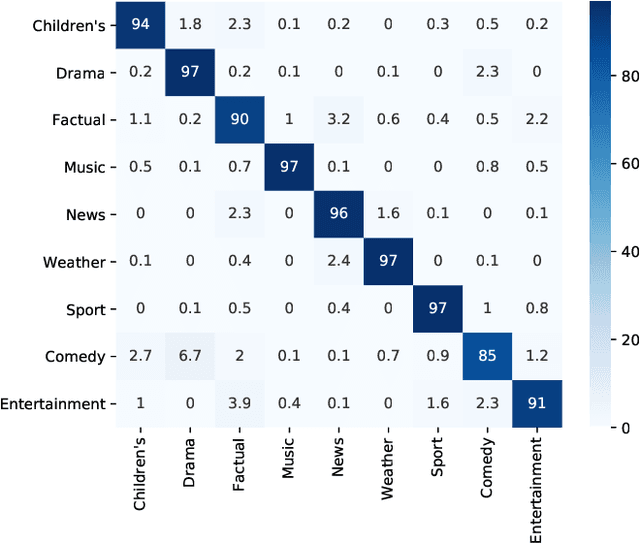
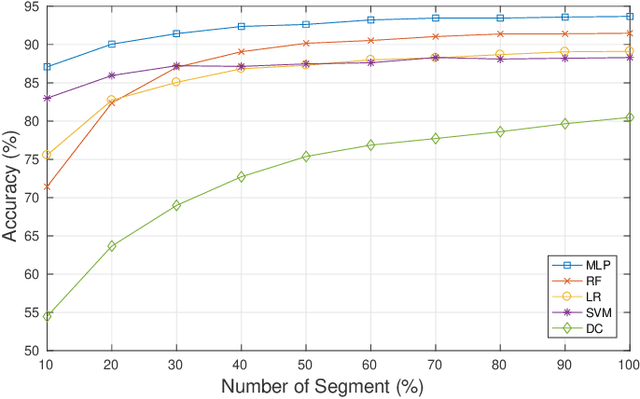
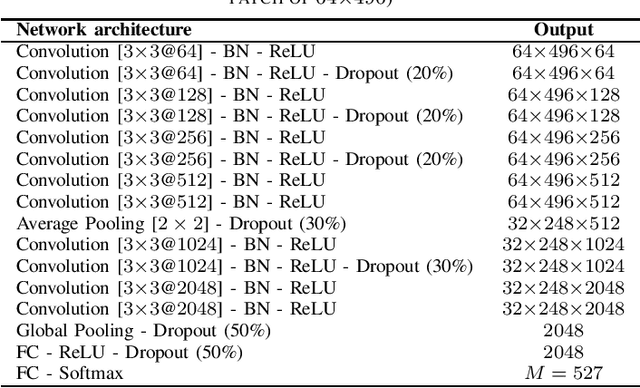
This paper proposes a deep learning framework for classification of BBC television programmes using audio. The audio is firstly transformed into spectrograms, which are fed into a pre-trained convolutional Neural Network (CNN), obtaining predicted probabilities of sound events occurring in the audio recording. Statistics for the predicted probabilities and detected sound events are then calculated to extract discriminative features representing the television programmes. Finally, the embedded features extracted are fed into a classifier for classifying the programmes into different genres. Our experiments are conducted over a dataset of 6,160 programmes belonging to nine genres labelled by the BBC. We achieve an average classification accuracy of 93.7% over 14-fold cross validation. This demonstrates the efficacy of the proposed framework for the task of audio-based classification of television programmes.