 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Speech Intelligibility Enhancement Model based on Canonical Correlation and Deep Learning for Hearing-Assistive Technologies
Feb 15, 2022
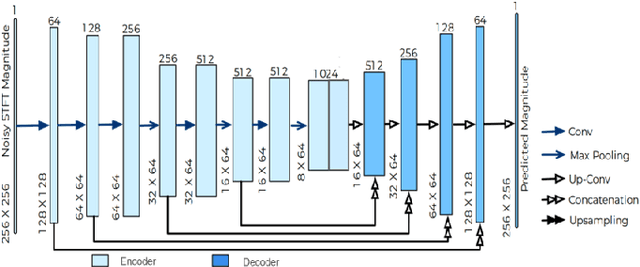
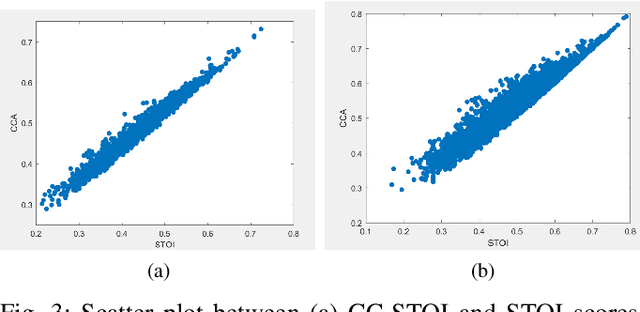
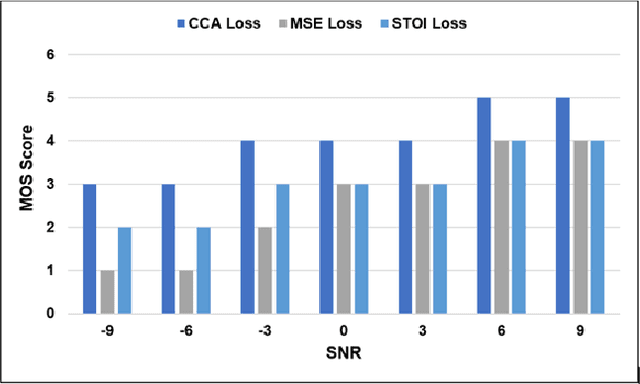
Current deep learning (DL) based approaches to speech intelligibility enhancement in noisy environments are generally trained to minimise the distance between clean and enhanced speech features. These often result in improved speech quality however they suffer from a lack of generalisation and may not deliver the required speech intelligibility in everyday noisy situations. In an attempt to address these challenges, researchers have explored intelligibility-oriented (I-O) loss functions to train DL approaches for robust speech enhancement (SE). In this paper, we formulate a novel canonical correlation-based I-O loss function to more effectively train DL algorithms. Specifically, we present a fully convolutional SE model that uses a modified canonical-correlation based short-time objective intelligibility (CC-STOI) metric as a training cost function. To the best of our knowledge, this is the first work that exploits the integration of canonical correlation in an I-O based loss function for SE. Comparative experimental results demonstrate that our proposed CC-STOI based SE framework outperforms DL models trained with conventional STOI and distance-based loss functions, in terms of both standard objective and subjective evaluation measures when dealing with unseen speakers and noises.
A Novel Speech Intelligibility Enhancement Model based on CanonicalCorrelation and Deep Learning
Feb 11, 2022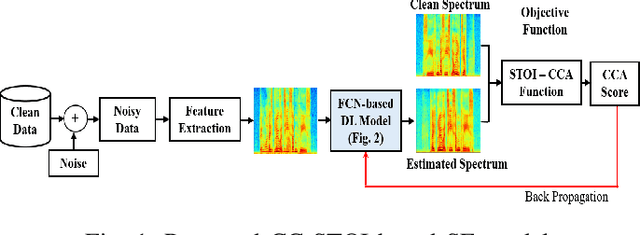

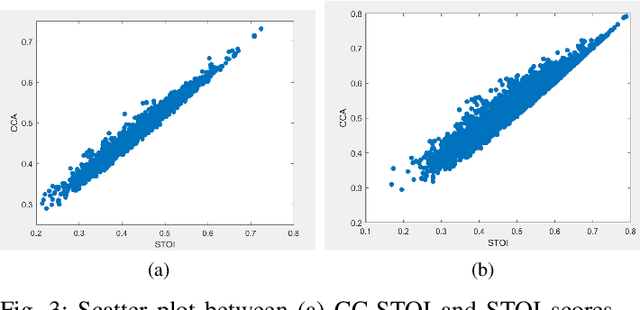
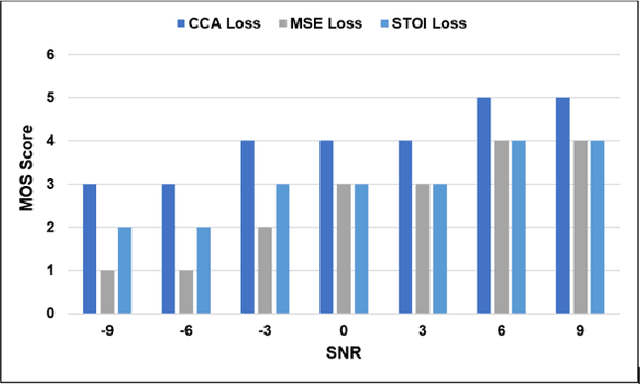
Current deep learning (DL) based approaches to speech intelligibility enhancement in noisy environments are often trained to minimise the feature distance between noise-free speech and enhanced speech signals. Despite improving the speech quality, such approaches do not deliver required levels of speech intelligibility in everyday noisy environments . Intelligibility-oriented (I-O) loss functions have recently been developed to train DL approaches for robust speech enhancement. Here, we formulate, for the first time, a novel canonical correlation based I-O loss function to more effectively train DL algorithms. Specifically, we present a canonical-correlation based short-time objective intelligibility (CC-STOI) cost function to train a fully convolutional neural network (FCN) model. We carry out comparative simulation experiments to show that our CC-STOI based speech enhancement framework outperforms state-of-the-art DL models trained with conventional distance-based and STOI-based loss functions, using objective and subjective evaluation measures for case of both unseen speakers and noises. Ongoing future work is evaluating the proposed approach for design of robust hearing-assistive technology.
A Novel Chaos-based Light-weight Image Encryption Scheme for Multi-modal Hearing Aids
Feb 11, 2022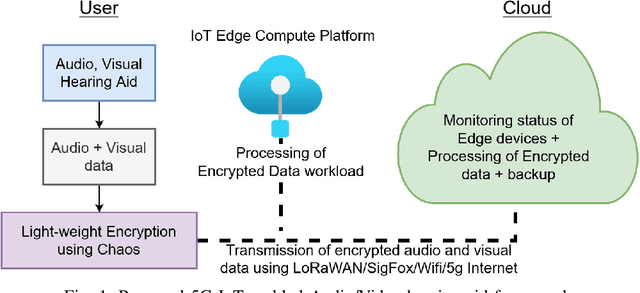

Multimodal hearing aids (HAs) aim to deliver more intelligible audio in noisy environments by contextually sensing and processing data in the form of not only audio but also visual information (e.g. lip reading). Machine learning techniques can play a pivotal role for the contextually processing of multimodal data. However, since the computational power of HA devices is low, therefore this data must be processed either on the edge or cloud which, in turn, poses privacy concerns for sensitive user data. Existing literature proposes several techniques for data encryption but their computational complexity is a major bottleneck to meet strict latency requirements for development of future multi-modal hearing aids. To overcome this problem, this paper proposes a novel real-time audio/visual data encryption scheme based on chaos-based encryption using the Tangent-Delay Ellipse Reflecting Cavity-Map System (TD-ERCS) map and Non-linear Chaotic (NCA) Algorithm. The results achieved against different security parameters, including Correlation Coefficient, Unified Averaged Changed Intensity (UACI), Key Sensitivity Analysis, Number of Changing Pixel Rate (NPCR), Mean-Square Error (MSE), Peak Signal to Noise Ratio (PSNR), Entropy test, and Chi-test, indicate that the newly proposed scheme is more lightweight due to its lower execution time as compared to existing schemes and more secure due to increased key-space against modern brute-force attacks.