 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Evaluation of Large Language Models for Persian Sentiment Analysis and Emotion Detection in Social Media Texts
Sep 18, 2025This study presents a comprehensive comparative evaluation of four state-of-the-art Large Language Models (LLMs)--Claude 3.7 Sonnet, DeepSeek-V3, Gemini 2.0 Flash, and GPT-4o--for sentiment analysis and emotion detection in Persian social media texts. Comparative analysis among LLMs has witnessed a significant rise in recent years, however, most of these analyses have been conducted on English language tasks, creating gaps in understanding cross-linguistic performance patterns. This research addresses these gaps through rigorous experimental design using balanced Persian datasets containing 900 texts for sentiment analysis (positive, negative, neutral) and 1,800 texts for emotion detection (anger, fear, happiness, hate, sadness, surprise). The main focus was to allow for a direct and fair comparison among different models, by using consistent prompts, uniform processing parameters, and by analyzing the performance metrics such as precision, recall, F1-scores, along with misclassification patterns. The results show that all models reach an acceptable level of performance, and a statistical comparison of the best three models indicates no significant differences among them. However, GPT-4o demonstrated a marginally higher raw accuracy value for both tasks, while Gemini 2.0 Flash proved to be the most cost-efficient. The findings indicate that the emotion detection task is more challenging for all models compared to the sentiment analysis task, and the misclassification patterns can represent some challenges in Persian language texts. These findings establish performance benchmarks for Persian NLP applications and offer practical guidance for model selection based on accuracy, efficiency, and cost considerations, while revealing cultural and linguistic challenges that require consideration in multilingual AI system deployment.
Audio-Visual Feature Synchronization for Robust Speech Enhancement in Hearing Aids
Aug 26, 2025Audio-visual feature synchronization for real-time speech enhancement in hearing aids represents a progressive approach to improving speech intelligibility and user experience, particularly in strong noisy backgrounds. This approach integrates auditory signals with visual cues, utilizing the complementary description of these modalities to improve speech intelligibility. Audio-visual feature synchronization for real-time SE in hearing aids can be further optimized using an efficient feature alignment module. In this study, a lightweight cross-attentional model learns robust audio-visual representations by exploiting large-scale data and simple architecture. By incorporating the lightweight cross-attentional model in an AVSE framework, the neural system dynamically emphasizes critical features across audio and visual modalities, enabling defined synchronization and improved speech intelligibility. The proposed AVSE model not only ensures high performance in noise suppression and feature alignment but also achieves real-time processing with minimal latency (36ms) and energy consumption. Evaluations on the AVSEC3 dataset show the efficiency of the model, achieving significant gains over baselines in perceptual quality (PESQ:0.52), intelligibility (STOI:19\%), and fidelity (SI-SDR:10.10dB).
Audio-Visual Speech Enhancement in Noisy Environments via Emotion-Based Contextual Cues
Feb 26, 2024


In real-world environments, background noise significantly degrades the intelligibility and clarity of human speech. Audio-visual speech enhancement (AVSE) attempts to restore speech quality, but existing methods often fall short, particularly in dynamic noise conditions. This study investigates the inclusion of emotion as a novel contextual cue within AVSE, hypothesizing that incorporating emotional understanding can improve speech enhancement performance. We propose a novel emotion-aware AVSE system that leverages both auditory and visual information. It extracts emotional features from the facial landmarks of the speaker and fuses them with corresponding audio and visual modalities. This enriched data serves as input to a deep UNet-based encoder-decoder network, specifically designed to orchestrate the fusion of multimodal information enhanced with emotion. The network iteratively refines the enhanced speech representation through an encoder-decoder architecture, guided by perceptually-inspired loss functions for joint learning and optimization. We train and evaluate the model on the CMU Multimodal Opinion Sentiment and Emotion Intensity (CMU-MOSEI) dataset, a rich repository of audio-visual recordings with annotated emotions. Our comprehensive evaluation demonstrates the effectiveness of emotion as a contextual cue for AVSE. By integrating emotional features, the proposed system achieves significant improvements in both objective and subjective assessments of speech quality and intelligibility, especially in challenging noise environments. Compared to baseline AVSE and audio-only speech enhancement systems, our approach exhibits a noticeable increase in PESQ and STOI, indicating higher perceptual quality and intelligibility. Large-scale listening tests corroborate these findings, suggesting improved human understanding of enhanced speech.
Towards Environmental Preference Based Speech Enhancement For Individualised Multi-Modal Hearing Aids
Feb 26, 2024



Since the advent of Deep Learning (DL), Speech Enhancement (SE) models have performed well under a variety of noise conditions. However, such systems may still introduce sonic artefacts, sound unnatural, and restrict the ability for a user to hear ambient sound which may be of importance. Hearing Aid (HA) users may wish to customise their SE systems to suit their personal preferences and day-to-day lifestyle. In this paper, we introduce a preference learning based SE (PLSE) model for future multi-modal HAs that can contextually exploit audio information to improve listening comfort, based upon the preferences of the user. The proposed system estimates the Signal-to-noise ratio (SNR) as a basic objective speech quality measure which quantifies the relative amount of background noise present in speech, and directly correlates to the intelligibility of the signal. Additionally, to provide contextual information we predict the acoustic scene in which the user is situated. These tasks are achieved via a multi-task DL model, which surpasses the performance of inferring the acoustic scene or SNR separately, by jointly leveraging a shared encoded feature space. These environmental inferences are exploited in a preference elicitation framework, which linearly learns a set of predictive functions to determine the target SNR of an AV (Audio-Visual) SE system. By greatly reducing noise in challenging listening conditions, and by novelly scaling the output of the SE model, we are able to provide HA users with contextually individualised SE. Preliminary results suggest an improvement over the non-individualised baseline model in some participants.
Audio-Visual Speech Enhancement Using Self-supervised Learning to Improve Speech Intelligibility in Cochlear Implant Simulations
Jul 15, 2023



Individuals with hearing impairments face challenges in their ability to comprehend speech, particularly in noisy environments. The aim of this study is to explore the effectiveness of audio-visual speech enhancement (AVSE) in enhancing the intelligibility of vocoded speech in cochlear implant (CI) simulations. Notably, the study focuses on a challenged scenario where there is limited availability of training data for the AVSE task. To address this problem, we propose a novel deep neural network framework termed Self-Supervised Learning-based AVSE (SSL-AVSE). The proposed SSL-AVSE combines visual cues, such as lip and mouth movements, from the target speakers with corresponding audio signals. The contextually combined audio and visual data are then fed into a Transformer-based SSL AV-HuBERT model to extract features, which are further processed using a BLSTM-based SE model. The results demonstrate several key findings. Firstly, SSL-AVSE successfully overcomes the issue of limited data by leveraging the AV-HuBERT model. Secondly, by fine-tuning the AV-HuBERT model parameters for the target SE task, significant performance improvements are achieved. Specifically, there is a notable enhancement in PESQ (Perceptual Evaluation of Speech Quality) from 1.43 to 1.67 and in STOI (Short-Time Objective Intelligibility) from 0.70 to 0.74. Furthermore, the performance of the SSL-AVSE was evaluated using CI vocoded speech to assess the intelligibility for CI users. Comparative experimental outcomes reveal that in the presence of dynamic noises encountered during human conversations, SSL-AVSE exhibits a substantial improvement. The NCM (Normal Correlation Matrix) values indicate an increase of 26.5% to 87.2% compared to the noisy baseline.
A Novel Frame Structure for Cloud-Based Audio-Visual Speech Enhancement in Multimodal Hearing-aids
Oct 24, 2022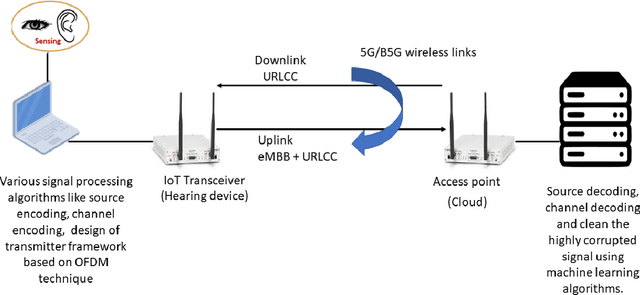
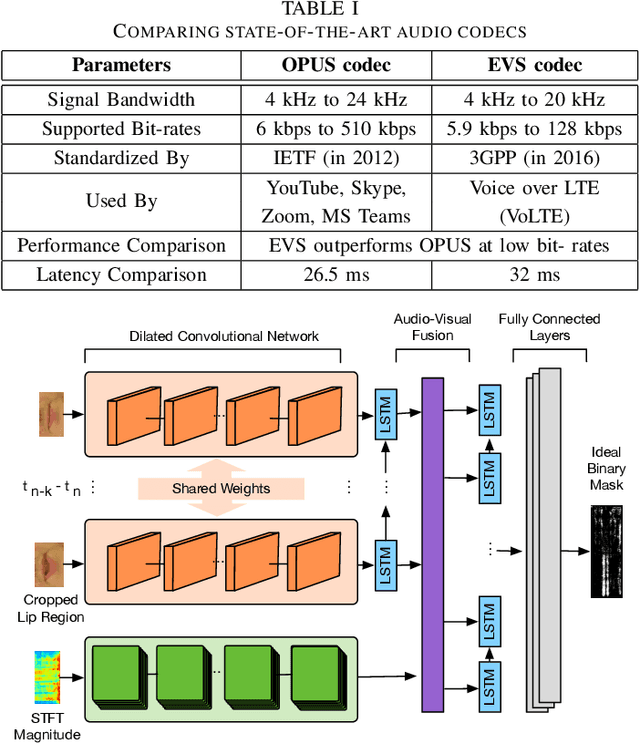
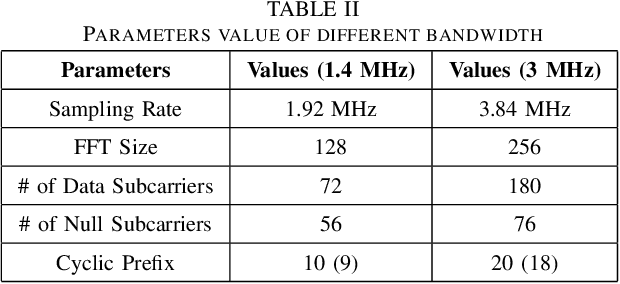
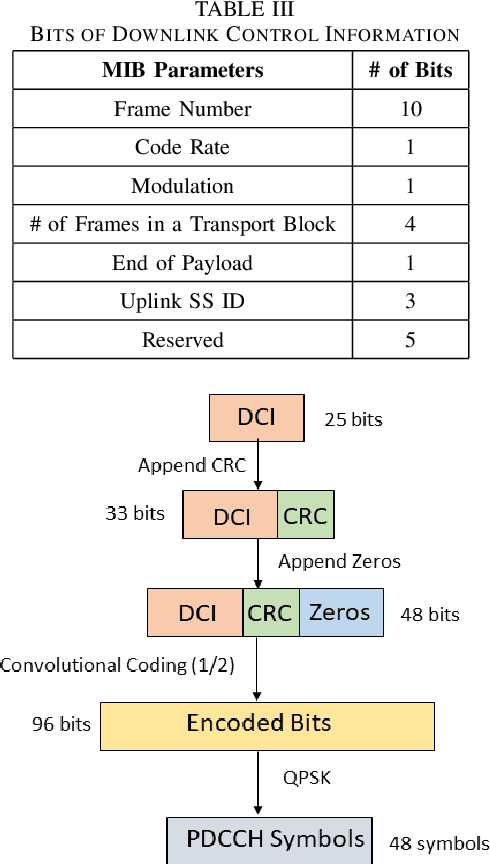
In this paper, we design a first of its kind transceiver (PHY layer) prototype for cloud-based audio-visual (AV) speech enhancement (SE) complying with high data rate and low latency requirements of future multimodal hearing assistive technology. The innovative design needs to meet multiple challenging constraints including up/down link communications, delay of transmission and signal processing, and real-time AV SE models processing. The transceiver includes device detection, frame detection, frequency offset estimation, and channel estimation capabilities. We develop both uplink (hearing aid to the cloud) and downlink (cloud to hearing aid) frame structures based on the data rate and latency requirements. Due to the varying nature of uplink information (audio and lip-reading), the uplink channel supports multiple data rate frame structure, while the downlink channel has a fixed data rate frame structure. In addition, we evaluate the latency of different PHY layer blocks of the transceiver for developed frame structures using LabVIEW NXG. This can be used with software defined radio (such as Universal Software Radio Peripheral) for real-time demonstration scenarios.
A Speech Intelligibility Enhancement Model based on Canonical Correlation and Deep Learning for Hearing-Assistive Technologies
Feb 15, 2022
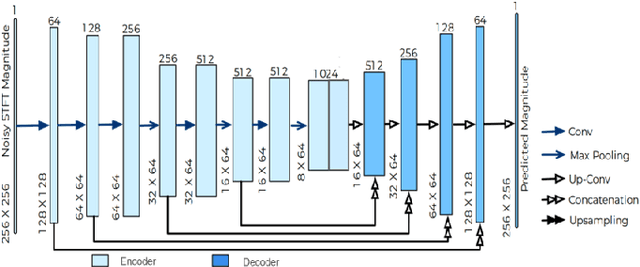
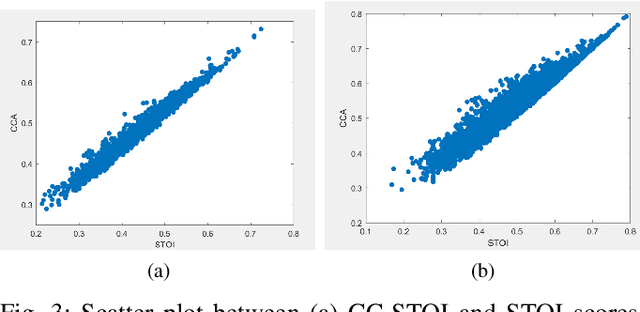
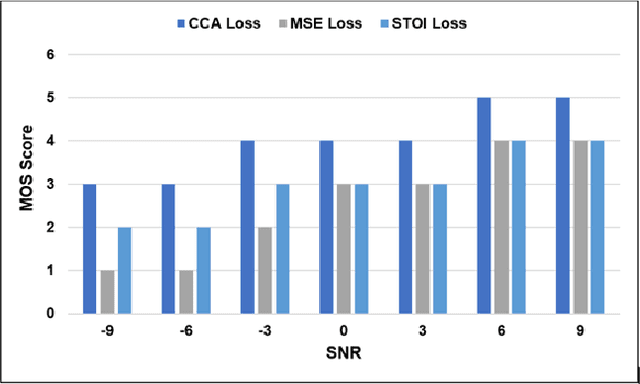
Current deep learning (DL) based approaches to speech intelligibility enhancement in noisy environments are generally trained to minimise the distance between clean and enhanced speech features. These often result in improved speech quality however they suffer from a lack of generalisation and may not deliver the required speech intelligibility in everyday noisy situations. In an attempt to address these challenges, researchers have explored intelligibility-oriented (I-O) loss functions to train DL approaches for robust speech enhancement (SE). In this paper, we formulate a novel canonical correlation-based I-O loss function to more effectively train DL algorithms. Specifically, we present a fully convolutional SE model that uses a modified canonical-correlation based short-time objective intelligibility (CC-STOI) metric as a training cost function. To the best of our knowledge, this is the first work that exploits the integration of canonical correlation in an I-O based loss function for SE. Comparative experimental results demonstrate that our proposed CC-STOI based SE framework outperforms DL models trained with conventional STOI and distance-based loss functions, in terms of both standard objective and subjective evaluation measures when dealing with unseen speakers and noises.
A Novel Speech Intelligibility Enhancement Model based on CanonicalCorrelation and Deep Learning
Feb 11, 2022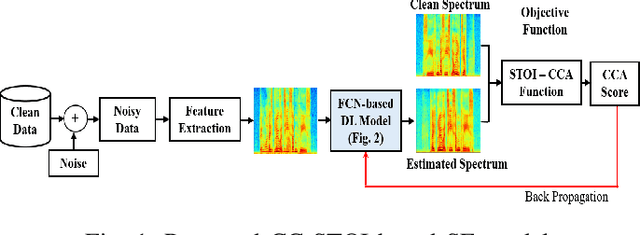

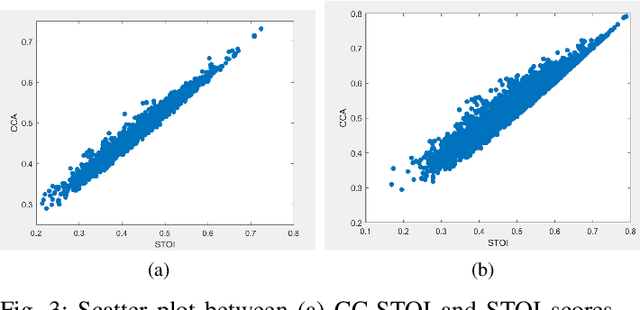
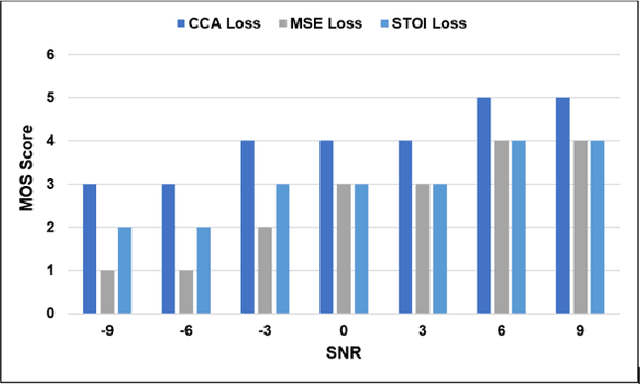
Current deep learning (DL) based approaches to speech intelligibility enhancement in noisy environments are often trained to minimise the feature distance between noise-free speech and enhanced speech signals. Despite improving the speech quality, such approaches do not deliver required levels of speech intelligibility in everyday noisy environments . Intelligibility-oriented (I-O) loss functions have recently been developed to train DL approaches for robust speech enhancement. Here, we formulate, for the first time, a novel canonical correlation based I-O loss function to more effectively train DL algorithms. Specifically, we present a canonical-correlation based short-time objective intelligibility (CC-STOI) cost function to train a fully convolutional neural network (FCN) model. We carry out comparative simulation experiments to show that our CC-STOI based speech enhancement framework outperforms state-of-the-art DL models trained with conventional distance-based and STOI-based loss functions, using objective and subjective evaluation measures for case of both unseen speakers and noises. Ongoing future work is evaluating the proposed approach for design of robust hearing-assistive technology.
A Novel Chaos-based Light-weight Image Encryption Scheme for Multi-modal Hearing Aids
Feb 11, 2022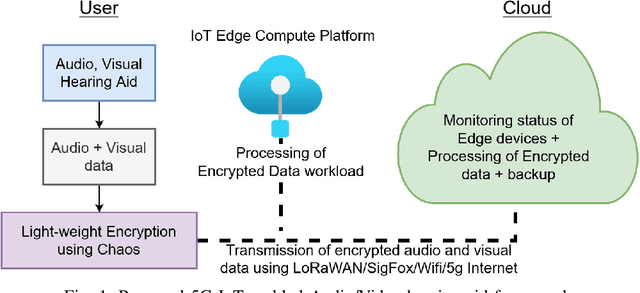

Multimodal hearing aids (HAs) aim to deliver more intelligible audio in noisy environments by contextually sensing and processing data in the form of not only audio but also visual information (e.g. lip reading). Machine learning techniques can play a pivotal role for the contextually processing of multimodal data. However, since the computational power of HA devices is low, therefore this data must be processed either on the edge or cloud which, in turn, poses privacy concerns for sensitive user data. Existing literature proposes several techniques for data encryption but their computational complexity is a major bottleneck to meet strict latency requirements for development of future multi-modal hearing aids. To overcome this problem, this paper proposes a novel real-time audio/visual data encryption scheme based on chaos-based encryption using the Tangent-Delay Ellipse Reflecting Cavity-Map System (TD-ERCS) map and Non-linear Chaotic (NCA) Algorithm. The results achieved against different security parameters, including Correlation Coefficient, Unified Averaged Changed Intensity (UACI), Key Sensitivity Analysis, Number of Changing Pixel Rate (NPCR), Mean-Square Error (MSE), Peak Signal to Noise Ratio (PSNR), Entropy test, and Chi-test, indicate that the newly proposed scheme is more lightweight due to its lower execution time as compared to existing schemes and more secure due to increased key-space against modern brute-force attacks.
A Novel Temporal Attentive-Pooling based Convolutional Recurrent Architecture for Acoustic Signal Enhancement
Jan 24, 2022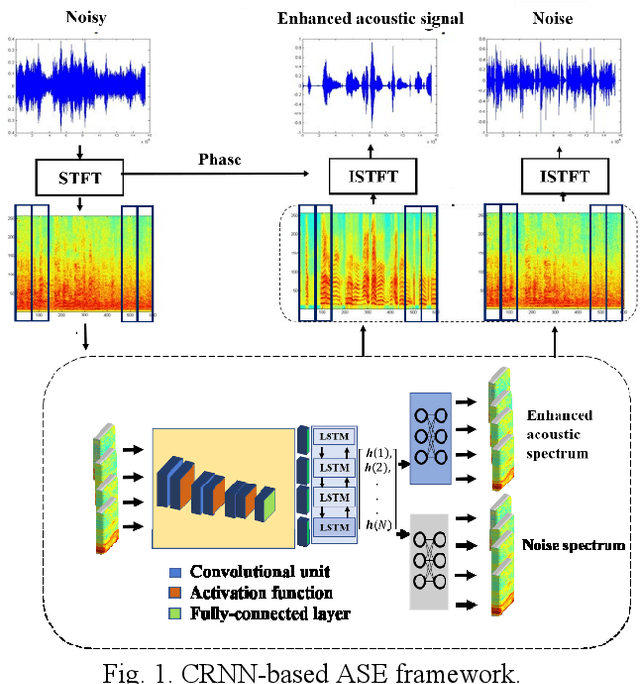
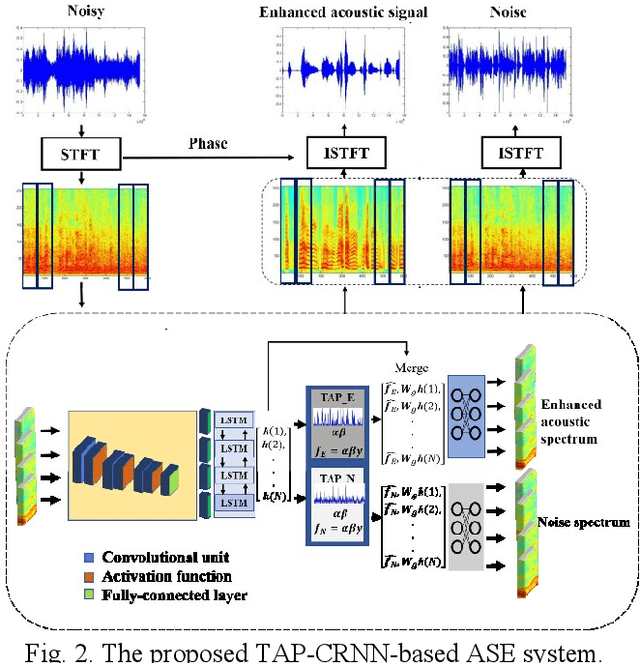
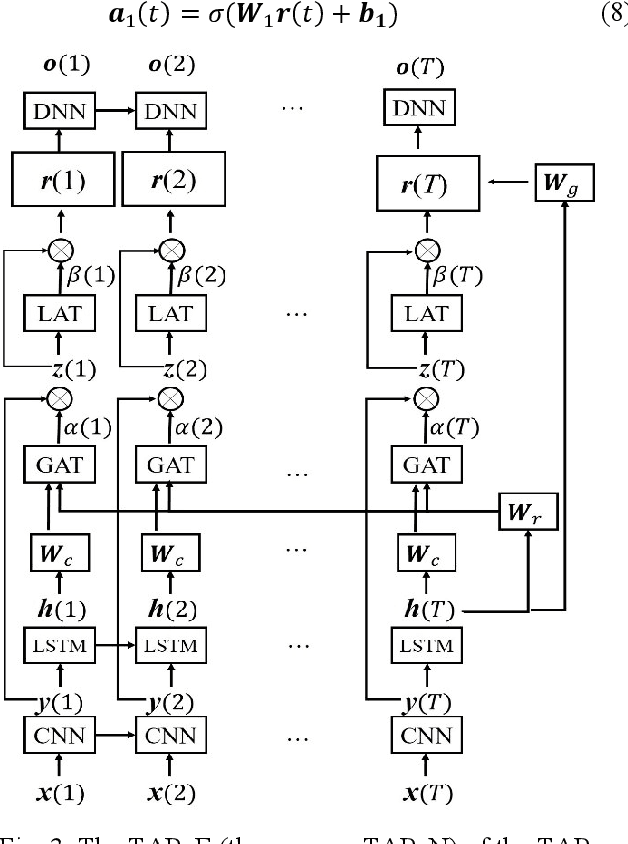
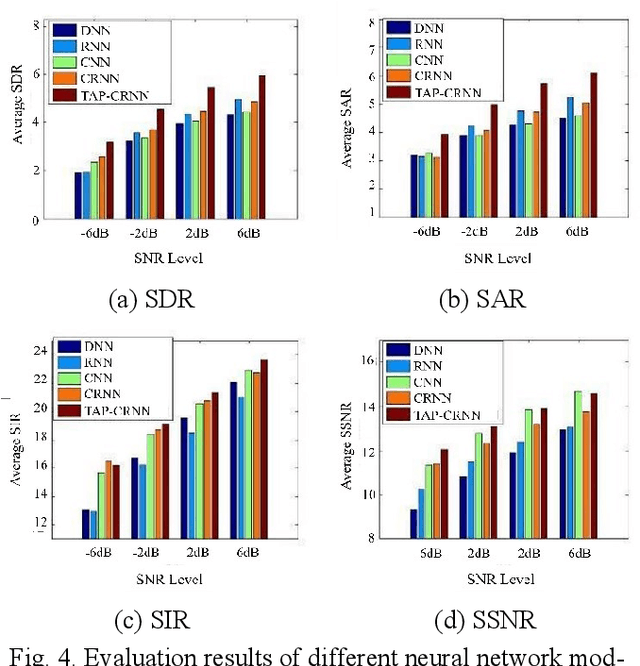
In acoustic signal processing, the target signals usually carry semantic information, which is encoded in a hierarchal structure of short and long-term contexts. However, the background noise distorts these structures in a nonuniform way. The existing deep acoustic signal enhancement (ASE) architectures ignore this kind of local and global effect. To address this problem, we propose to integrate a novel temporal attentive-pooling (TAP) mechanism into a conventional convolutional recurrent neural network, termed as TAP-CRNN. The proposed approach considers both global and local attention for ASE tasks. Specifically, we first utilize a convolutional layer to extract local information of the acoustic signals and then a recurrent neural network (RNN) architecture is used to characterize temporal contextual information. Second, we exploit a novelattention mechanism to contextually process salient regions of the noisy signals. The proposed ASE system is evaluated using a benchmark infant cry dataset and compared with several well-known methods. It is shown that the TAPCRNN can more effectively reduce noise components from infant cry signals in unseen background noises at challenging signal-to-noise levels.