 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel CNN-LSTM-based Approach to Predict Urban Expansion
Mar 02, 2021Time-series remote sensing data offer a rich source of information that can be used in a wide range of applications, from monitoring changes in land cover to surveilling crops, coastal changes, flood risk assessment, and urban sprawl. This paper addresses the challenge of using time-series satellite images to predict urban expansion. Building upon previous work, we propose a novel two-step approach based on semantic image segmentation in order to predict urban expansion. The first step aims to extract information about urban regions at different time scales and prepare them for use in the training step. The second step combines Convolutional Neural Networks (CNN) with Long Short Term Memory (LSTM) methods in order to learn temporal features and thus predict urban expansion. In this paper, experimental results are conducted using several multi-date satellite images representing the three largest cities in Saudi Arabia, namely: Riyadh, Jeddah, and Dammam. We empirically evaluated our proposed technique, and examined its results by comparing them with state-of-the-art approaches. Following this evaluation, we determined that our results reveal improved performance for the new-coupled CNN-LSTM approach, particularly in terms of assessments based on Mean Square Error, Root Mean Square Error, Peak Signal to Noise Ratio, Structural Similarity Index, and overall classification accuracy.
Saliency Revisited: Analysis of Mouse Movements versus Fixations
May 30, 2017
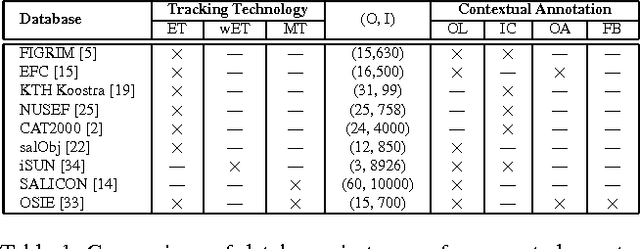


This paper revisits visual saliency prediction by evaluating the recent advancements in this field such as crowd-sourced mouse tracking-based databases and contextual annotations. We pursue a critical and quantitative approach towards some of the new challenges including the quality of mouse tracking versus eye tracking for model training and evaluation. We extend quantitative evaluation of models in order to incorporate contextual information by proposing an evaluation methodology that allows accounting for contextual factors such as text, faces, and object attributes. The proposed contextual evaluation scheme facilitates detailed analysis of models and helps identify their pros and cons. Through several experiments, we find that (1) mouse tracking data has lower inter-participant visual congruency and higher dispersion, compared to the eye tracking data, (2) mouse tracking data does not totally agree with eye tracking in general and in terms of different contextual regions in specific, and (3) mouse tracking data leads to acceptable results in training current existing models, and (4) mouse tracking data is less reliable for model selection and evaluation. The contextual evaluation also reveals that, among the studied models, there is no single model that performs best on all the tested annotations.