 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Early Alzheimer Disease Detection through Big Data and Ensemble Few-Shot Learning
Oct 22, 2025Alzheimer disease is a severe brain disorder that causes harm in various brain areas and leads to memory damage. The limited availability of labeled medical data poses a significant challenge for accurate Alzheimer disease detection. There is a critical need for effective methods to improve the accuracy of Alzheimer disease detection, considering the scarcity of labeled data, the complexity of the disease, and the constraints related to data privacy. To address this challenge, our study leverages the power of big data in the form of pre-trained Convolutional Neural Networks (CNNs) within the framework of Few-Shot Learning (FSL) and ensemble learning. We propose an ensemble approach based on a Prototypical Network (ProtoNet), a powerful method in FSL, integrating various pre-trained CNNs as encoders. This integration enhances the richness of features extracted from medical images. Our approach also includes a combination of class-aware loss and entropy loss to ensure a more precise classification of Alzheimer disease progression levels. The effectiveness of our method was evaluated using two datasets, the Kaggle Alzheimer dataset and the ADNI dataset, achieving an accuracy of 99.72% and 99.86%, respectively. The comparison of our results with relevant state-of-the-art studies demonstrated that our approach achieved superior accuracy and highlighted its validity and potential for real-world applications in early Alzheimer disease detection.
GATE: General Arabic Text Embedding for Enhanced Semantic Textual Similarity with Matryoshka Representation Learning and Hybrid Loss Training
May 30, 2025Semantic textual similarity (STS) is a critical task in natural language processing (NLP), enabling applications in retrieval, clustering, and understanding semantic relationships between texts. However, research in this area for the Arabic language remains limited due to the lack of high-quality datasets and pre-trained models. This scarcity of resources has restricted the accurate evaluation and advance of semantic similarity in Arabic text. This paper introduces General Arabic Text Embedding (GATE) models that achieve state-of-the-art performance on the Semantic Textual Similarity task within the MTEB benchmark. GATE leverages Matryoshka Representation Learning and a hybrid loss training approach with Arabic triplet datasets for Natural Language Inference, which are essential for enhancing model performance in tasks that demand fine-grained semantic understanding. GATE outperforms larger models, including OpenAI, with a 20-25% performance improvement on STS benchmarks, effectively capturing the unique semantic nuances of Arabic.
Exploring Graph Mamba: A Comprehensive Survey on State-Space Models for Graph Learning
Dec 24, 2024



Graph Mamba, a powerful graph embedding technique, has emerged as a cornerstone in various domains, including bioinformatics, social networks, and recommendation systems. This survey represents the first comprehensive study devoted to Graph Mamba, to address the critical gaps in understanding its applications, challenges, and future potential. We start by offering a detailed explanation of the original Graph Mamba architecture, highlighting its key components and underlying mechanisms. Subsequently, we explore the most recent modifications and enhancements proposed to improve its performance and applicability. To demonstrate the versatility of Graph Mamba, we examine its applications across diverse domains. A comparative analysis of Graph Mamba and its variants is conducted to shed light on their unique characteristics and potential use cases. Furthermore, we identify potential areas where Graph Mamba can be applied in the future, highlighting its potential to revolutionize data analysis in these fields. Finally, we address the current limitations and open research questions associated with Graph Mamba. By acknowledging these challenges, we aim to stimulate further research and development in this promising area. This survey serves as a valuable resource for both newcomers and experienced researchers seeking to understand and leverage the power of Graph Mamba.
Enhancing Internet of Things Security throughSelf-Supervised Graph Neural Networks
Dec 17, 2024



With the rapid rise of the Internet of Things (IoT), ensuring the security of IoT devices has become essential. One of the primary challenges in this field is that new types of attacks often have significantly fewer samples than more common attacks, leading to unbalanced datasets. Existing research on detecting intrusions in these unbalanced labeled datasets primarily employs Convolutional Neural Networks (CNNs) or conventional Machine Learning (ML) models, which result in incomplete detection, especially for new attacks. To handle these challenges, we suggest a new approach to IoT intrusion detection using Self-Supervised Learning (SSL) with a Markov Graph Convolutional Network (MarkovGCN). Graph learning excels at modeling complex relationships within data, while SSL mitigates the issue of limited labeled data for emerging attacks. Our approach leverages the inherent structure of IoT networks to pre-train a GCN, which is then fine-tuned for the intrusion detection task. The integration of Markov chains in GCN uncovers network structures and enriches node and edge features with contextual information. Experimental results demonstrate that our approach significantly improves detection accuracy and robustness compared to conventional supervised learning methods. Using the EdgeIIoT-set dataset, we attained an accuracy of 98.68\%, a precision of 98.18%, a recall of 98.35%, and an F1-Score of 98.40%.
Self-Supervised Learning for Graph-Structured Data in Healthcare Applications: A Comprehensive Review
Nov 28, 2024



The abundance of complex and interconnected healthcare data offers numerous opportunities to improve prediction, diagnosis, and treatment. Graph-structured data, which includes entities and their relationships, is well-suited for capturing complex connections. Effectively utilizing this data often requires strong and efficient learning algorithms, especially when dealing with limited labeled data. It is increasingly important for downstream tasks in various domains to utilize self-supervised learning (SSL) as a paradigm for learning and optimizing effective representations from unlabeled data. In this paper, we thoroughly review SSL approaches specifically designed for graph-structured data in healthcare applications. We explore the challenges and opportunities associated with healthcare data and assess the effectiveness of SSL techniques in real-world healthcare applications. Our discussion encompasses various healthcare settings, such as disease prediction, medical image analysis, and drug discovery. We critically evaluate the performance of different SSL methods across these tasks, highlighting their strengths, limitations, and potential future research directions. Ultimately, this review aims to be a valuable resource for both researchers and practitioners looking to utilize SSL for graph-structured data in healthcare, paving the way for improved outcomes and insights in this critical field. To the best of our knowledge, this work represents the first comprehensive review of the literature on SSL applied to graph data in healthcare.
VECTOR: Velocity-Enhanced GRU Neural Network for Real-Time 3D UAV Trajectory Prediction
Oct 24, 2024


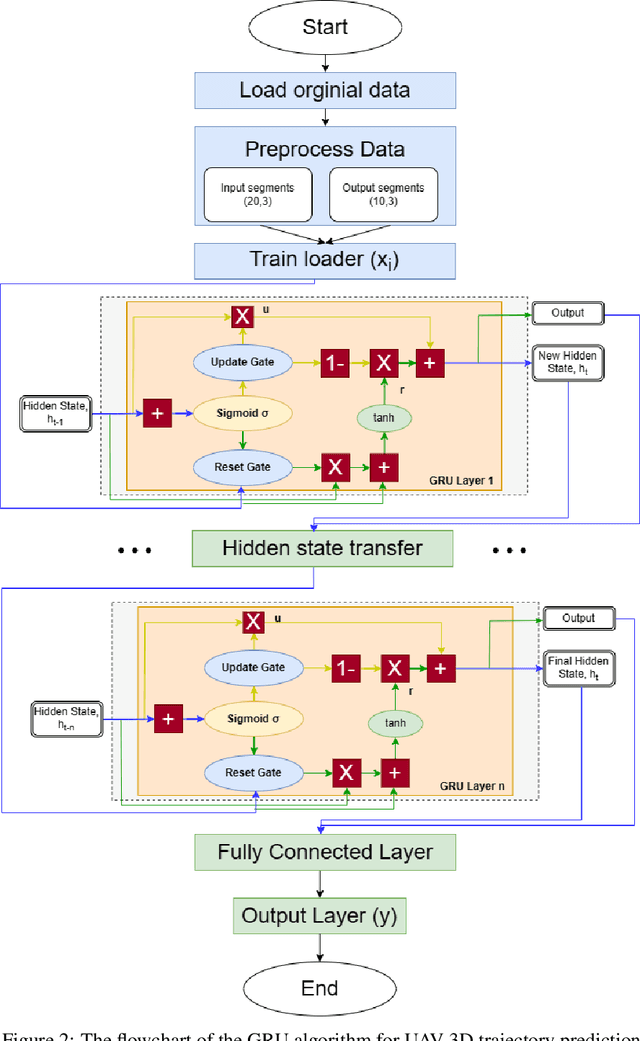
This paper tackles the challenge of real-time 3D trajectory prediction for UAVs, which is critical for applications such as aerial surveillance and defense. Existing prediction models that rely primarily on position data struggle with accuracy, especially when UAV movements fall outside the position domain used in training. Our research identifies a gap in utilizing velocity estimates, first-order dynamics, to better capture the dynamics and enhance prediction accuracy and generalizability in any position domain. To bridge this gap, we propose a new trajectory prediction method using Gated Recurrent Units (GRUs) within sequence-based neural networks. Unlike traditional methods that rely on RNNs or transformers, this approach forecasts future velocities and positions based on historical velocity data instead of positions. This is designed to enhance prediction accuracy and scalability, overcoming challenges faced by conventional models in handling complex UAV dynamics. The methodology employs both synthetic and real-world 3D UAV trajectory data, capturing a wide range of flight patterns, speeds, and agility. Synthetic data is generated using the Gazebo simulator and PX4 Autopilot, while real-world data comes from the UZH-FPV and Mid-Air drone racing datasets. The GRU-based models significantly outperform state-of-the-art RNN approaches, with a mean square error (MSE) as low as 2 x 10^-8. Overall, our findings confirm the effectiveness of incorporating velocity data in improving the accuracy of UAV trajectory predictions across both synthetic and real-world scenarios, in and out of position data distributions. Finally, we open-source our 5000 trajectories dataset and a ROS 2 package to facilitate the integration with existing ROS-based UAV systems.
SMART-TRACK: A Novel Kalman Filter-Guided Sensor Fusion For Robust UAV Object Tracking in Dynamic Environments
Oct 14, 2024



In the field of sensor fusion and state estimation for object detection and localization, ensuring accurate tracking in dynamic environments poses significant challenges. Traditional methods like the Kalman Filter (KF) often fail when measurements are intermittent, leading to rapid divergence in state estimations. To address this, we introduce SMART (Sensor Measurement Augmentation and Reacquisition Tracker), a novel approach that leverages high-frequency state estimates from the KF to guide the search for new measurements, maintaining tracking continuity even when direct measurements falter. This is crucial for dynamic environments where traditional methods struggle. Our contributions include: 1) Versatile Measurement Augmentation Using KF Feedback: We implement a versatile measurement augmentation system that serves as a backup when primary object detectors fail intermittently. This system is adaptable to various sensors, demonstrated using depth cameras where KF's 3D predictions are projected into 2D depth image coordinates, integrating nonlinear covariance propagation techniques simplified to first-order approximations. 2) Open-source ROS2 Implementation: We provide an open-source ROS2 implementation of the SMART-TRACK framework, validated in a realistic simulation environment using Gazebo and ROS2, fostering broader adaptation and further research. Our results showcase significant enhancements in tracking stability, with estimation RMSE as low as 0.04 m during measurement disruptions, advancing the robustness of UAV tracking and expanding the potential for reliable autonomous UAV operations in complex scenarios. The implementation is available at https://github.com/mzahana/SMART-TRACK.
Enhancing Semantic Similarity Understanding in Arabic NLP with Nested Embedding Learning
Aug 01, 2024



This work presents a novel framework for training Arabic nested embedding models through Matryoshka Embedding Learning, leveraging multilingual, Arabic-specific, and English-based models, to highlight the power of nested embeddings models in various Arabic NLP downstream tasks. Our innovative contribution includes the translation of various sentence similarity datasets into Arabic, enabling a comprehensive evaluation framework to compare these models across different dimensions. We trained several nested embedding models on the Arabic Natural Language Inference triplet dataset and assessed their performance using multiple evaluation metrics, including Pearson and Spearman correlations for cosine similarity, Manhattan distance, Euclidean distance, and dot product similarity. The results demonstrate the superior performance of the Matryoshka embedding models, particularly in capturing semantic nuances unique to the Arabic language. Results demonstrated that Arabic Matryoshka embedding models have superior performance in capturing semantic nuances unique to the Arabic language, significantly outperforming traditional models by up to 20-25\% across various similarity metrics. These results underscore the effectiveness of language-specific training and highlight the potential of Matryoshka models in enhancing semantic textual similarity tasks for Arabic NLP.
Strengthening Network Intrusion Detection in IoT Environments with Self-Supervised Learning and Few Shot Learning
Jun 04, 2024The Internet of Things (IoT) has been introduced as a breakthrough technology that integrates intelligence into everyday objects, enabling high levels of connectivity between them. As the IoT networks grow and expand, they become more susceptible to cybersecurity attacks. A significant challenge in current intrusion detection systems for IoT includes handling imbalanced datasets where labeled data are scarce, particularly for new and rare types of cyber attacks. Existing literature often fails to detect such underrepresented attack classes. This paper introduces a novel intrusion detection approach designed to address these challenges. By integrating Self Supervised Learning (SSL), Few Shot Learning (FSL), and Random Forest (RF), our approach excels in learning from limited and imbalanced data and enhancing detection capabilities. The approach starts with a Deep Infomax model trained to extract key features from the dataset. These features are then fed into a prototypical network to generate discriminate embedding. Subsequently, an RF classifier is employed to detect and classify potential malware, including a range of attacks that are frequently observed in IoT networks. The proposed approach was evaluated through two different datasets, MaleVis and WSN-DS, which demonstrate its superior performance with accuracies of 98.60% and 99.56%, precisions of 98.79% and 99.56%, recalls of 98.60% and 99.56%, and F1-scores of 98.63% and 99.56%, respectively.
An Effective Weight Initialization Method for Deep Learning: Application to Satellite Image Classification
Jun 01, 2024



The growing interest in satellite imagery has triggered the need for efficient mechanisms to extract valuable information from these vast data sources, providing deeper insights. Even though deep learning has shown significant progress in satellite image classification. Nevertheless, in the literature, only a few results can be found on weight initialization techniques. These techniques traditionally involve initializing the networks' weights before training on extensive datasets, distinct from fine-tuning the weights of pre-trained networks. In this study, a novel weight initialization method is proposed in the context of satellite image classification. The proposed weight initialization method is mathematically detailed during the forward and backward passes of the convolutional neural network (CNN) model. Extensive experiments are carried out using six real-world datasets. Comparative analyses with existing weight initialization techniques made on various well-known CNN models reveal that the proposed weight initialization technique outperforms the previous competitive techniques in classification accuracy. The complete code of the proposed technique, along with the obtained results, is available at https://github.com/WadiiBoulila/Weight-Initialization