 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVECTOR: Velocity-Enhanced GRU Neural Network for Real-Time 3D UAV Trajectory Prediction
Oct 24, 2024


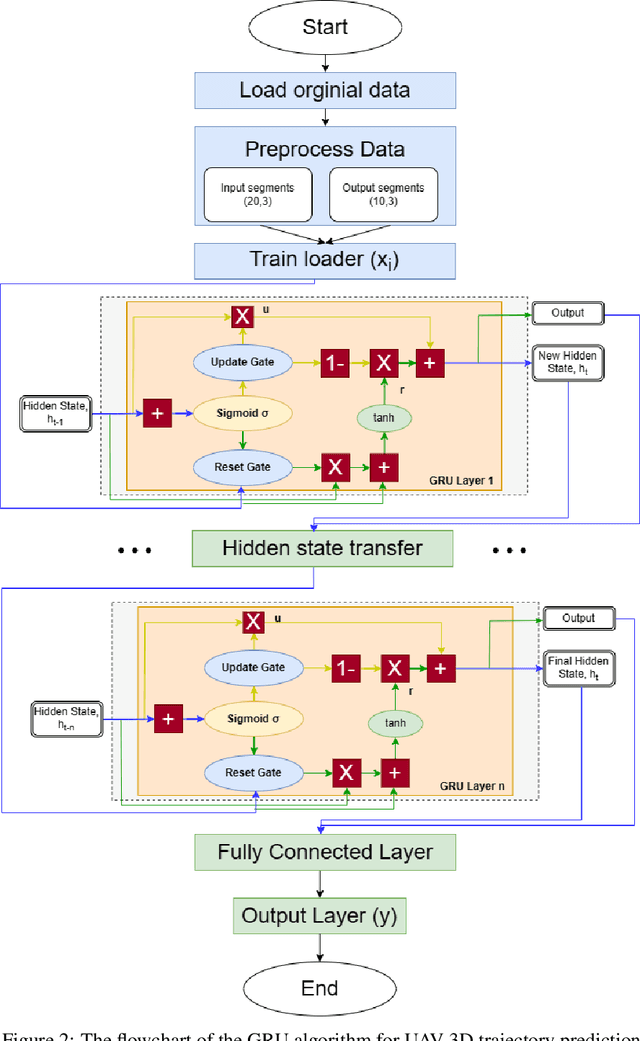
This paper tackles the challenge of real-time 3D trajectory prediction for UAVs, which is critical for applications such as aerial surveillance and defense. Existing prediction models that rely primarily on position data struggle with accuracy, especially when UAV movements fall outside the position domain used in training. Our research identifies a gap in utilizing velocity estimates, first-order dynamics, to better capture the dynamics and enhance prediction accuracy and generalizability in any position domain. To bridge this gap, we propose a new trajectory prediction method using Gated Recurrent Units (GRUs) within sequence-based neural networks. Unlike traditional methods that rely on RNNs or transformers, this approach forecasts future velocities and positions based on historical velocity data instead of positions. This is designed to enhance prediction accuracy and scalability, overcoming challenges faced by conventional models in handling complex UAV dynamics. The methodology employs both synthetic and real-world 3D UAV trajectory data, capturing a wide range of flight patterns, speeds, and agility. Synthetic data is generated using the Gazebo simulator and PX4 Autopilot, while real-world data comes from the UZH-FPV and Mid-Air drone racing datasets. The GRU-based models significantly outperform state-of-the-art RNN approaches, with a mean square error (MSE) as low as 2 x 10^-8. Overall, our findings confirm the effectiveness of incorporating velocity data in improving the accuracy of UAV trajectory predictions across both synthetic and real-world scenarios, in and out of position data distributions. Finally, we open-source our 5000 trajectories dataset and a ROS 2 package to facilitate the integration with existing ROS-based UAV systems.
ArabianGPT: Native Arabic GPT-based Large Language Model
Feb 26, 2024The predominance of English and Latin-based large language models (LLMs) has led to a notable deficit in native Arabic LLMs. This discrepancy is accentuated by the prevalent inclusion of English tokens in existing Arabic models, detracting from their efficacy in processing native Arabic's intricate morphology and syntax. Consequently, there is a theoretical and practical imperative for developing LLMs predominantly focused on Arabic linguistic elements. To address this gap, this paper proposes ArabianGPT, a series of transformer-based models within the ArabianLLM suite designed explicitly for Arabic. These models, including ArabianGPT-0.1B and ArabianGPT-0.3B, vary in size and complexity, aligning with the nuanced linguistic characteristics of Arabic. The AraNizer tokenizer, integral to these models, addresses the unique morphological aspects of Arabic script, ensuring more accurate text processing. Empirical results from fine-tuning the models on tasks like sentiment analysis and summarization demonstrate significant improvements. For sentiment analysis, the fine-tuned ArabianGPT-0.1B model achieved a remarkable accuracy of 95%, a substantial increase from the base model's 56%. Similarly, in summarization tasks, fine-tuned models showed enhanced F1 scores, indicating improved precision and recall in generating concise summaries. Comparative analysis of fine-tuned ArabianGPT models against their base versions across various benchmarks reveals nuanced differences in performance, with fine-tuning positively impacting specific tasks like question answering and summarization. These findings underscore the efficacy of fine-tuning in aligning ArabianGPT models more closely with specific NLP tasks, highlighting the potential of tailored transformer architectures in advancing Arabic NLP.
Humans are Still Better than ChatGPT: Case of the IEEEXtreme Competition
May 10, 2023



Since the release of ChatGPT, numerous studies have highlighted the remarkable performance of ChatGPT, which often rivals or even surpasses human capabilities in various tasks and domains. However, this paper presents a contrasting perspective by demonstrating an instance where human performance excels in typical tasks suited for ChatGPT, specifically in the domain of computer programming. We utilize the IEEExtreme Challenge competition as a benchmark, a prestigious, annual international programming contest encompassing a wide range of problems with different complexities. To conduct a thorough evaluation, we selected and executed a diverse set of 102 challenges, drawn from five distinct IEEExtreme editions, using three major programming languages: Python, Java, and C++. Our empirical analysis provides evidence that contrary to popular belief, human programmers maintain a competitive edge over ChatGPT in certain aspects of problem-solving within the programming context. In fact, we found that the average score obtained by ChatGPT on the set of IEEExtreme programming problems is 3.9 to 5.8 times lower than the average human score, depending on the programming language. This paper elaborates on these findings, offering critical insights into the limitations and potential areas of improvement for AI-based language models like ChatGPT.