 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrust-SSL: Additive-Residual Selective Invariance for Robust Aerial Self-Supervised Learning
Apr 23, 2026Self-supervised learning (SSL) is a standard approach for representation learning in aerial imagery. Existing methods enforce invariance between augmented views, which works well when augmentations preserve semantic content. However, aerial images are frequently degraded by haze, motion blur, rain, and occlusion that remove critical evidence. Enforcing alignment between a clean and a severely degraded view can introduce spurious structure into the latent space. This study proposes a training strategy and architectural modification to enhance SSL robustness to such corruptions. It introduces a per-sample, per-factor trust weight into the alignment objective, combined with the base contrastive loss as an additive residual. A stop-gradient is applied to the trust weight instead of a multiplicative gate. While a multiplicative gate is a natural choice, experiments show it impairs the backbone, whereas our additive-residual approach improves it. Using a 200-epoch protocol on a 210,000-image corpus, the method achieves the highest mean linear-probe accuracy among six backbones on EuroSAT, AID, and NWPU-RESISC45 (90.20% compared to 88.46% for SimCLR and 89.82% for VICReg). It yields the largest improvements under severe information-erasing corruptions on EuroSAT (+19.9 points on haze at s=5 over SimCLR). The method also demonstrates consistent gains of +1 to +3 points in Mahalanobis AUROC on a zero-shot cross-domain stress test using BDD100K weather splits. Two ablations (scalar uncertainty and cosine gate) indicate the additive-residual formulation is the primary source of these improvements. An evidential variant using Dempster-Shafer fusion introduces interpretable signals of conflict and ignorance. These findings offer a concrete design principle for uncertainty-aware SSL. Code is publicly available at https://github.com/WadiiBoulila/trust-ssl.
MURAD: A Large-Scale Multi-Domain Unified Reverse Arabic Dictionary Dataset
Jan 29, 2026Arabic is a linguistically and culturally rich language with a vast vocabulary that spans scientific, religious, and literary domains. Yet, large-scale lexical datasets linking Arabic words to precise definitions remain limited. We present MURAD (Multi-domain Unified Reverse Arabic Dictionary), an open lexical dataset with 96,243 word-definition pairs. The data come from trusted reference works and educational sources. Extraction used a hybrid pipeline integrating direct text parsing, optical character recognition, and automated reconstruction. This ensures accuracy and clarity. Each record aligns a target word with its standardized Arabic definition and metadata that identifies the source domain. The dataset covers terms from linguistics, Islamic studies, mathematics, physics, psychology, and engineering. It supports computational linguistics and lexicographic research. Applications include reverse dictionary modeling, semantic retrieval, and educational tools. By releasing this resource, we aim to advance Arabic natural language processing and promote reproducible research on Arabic lexical semantics.
The Path Ahead for Agentic AI: Challenges and Opportunities
Jan 06, 2026The evolution of Large Language Models (LLMs) from passive text generators to autonomous, goal-driven systems represents a fundamental shift in artificial intelligence. This chapter examines the emergence of agentic AI systems that integrate planning, memory, tool use, and iterative reasoning to operate autonomously in complex environments. We trace the architectural progression from statistical models to transformer-based systems, identifying capabilities that enable agentic behavior: long-range reasoning, contextual awareness, and adaptive decision-making. The chapter provides three contributions: (1) a synthesis of how LLM capabilities extend toward agency through reasoning-action-reflection loops; (2) an integrative framework describing core components perception, memory, planning, and tool execution that bridge LLMs with autonomous behavior; (3) a critical assessment of applications and persistent challenges in safety, alignment, reliability, and sustainability. Unlike existing surveys, we focus on the architectural transition from language understanding to autonomous action, emphasizing the technical gaps that must be resolved before deployment. We identify critical research priorities, including verifiable planning, scalable multi-agent coordination, persistent memory architectures, and governance frameworks. Responsible advancement requires simultaneous progress in technical robustness, interpretability, and ethical safeguards to realize potential while mitigating risks of misalignment and unintended consequences.
ARCADE: A City-Scale Corpus for Fine-Grained Arabic Dialect Tagging
Jan 05, 2026The Arabic language is characterized by a rich tapestry of regional dialects that differ substantially in phonetics and lexicon, reflecting the geographic and cultural diversity of its speakers. Despite the availability of many multi-dialect datasets, mapping speech to fine-grained dialect sources, such as cities, remains underexplored. We present ARCADE (Arabic Radio Corpus for Audio Dialect Evaluation), the first Arabic speech dataset designed explicitly with city-level dialect granularity. The corpus comprises Arabic radio speech collected from streaming services across the Arab world. Our data pipeline captures 30-second segments from verified radio streams, encompassing both Modern Standard Arabic (MSA) and diverse dialectal speech. To ensure reliability, each clip was annotated by one to three native Arabic reviewers who assigned rich metadata, including emotion, speech type, dialect category, and a validity flag for dialect identification tasks. The resulting corpus comprises 6,907 annotations and 3,790 unique audio segments spanning 58 cities across 19 countries. These fine-grained annotations enable robust multi-task learning, serving as a benchmark for city-level dialect tagging. We detail the data collection methodology, assess audio quality, and provide a comprehensive analysis of label distributions. The dataset is available on: https://huggingface.co/datasets/riotu-lab/ARCADE-full
GATE: General Arabic Text Embedding for Enhanced Semantic Textual Similarity with Matryoshka Representation Learning and Hybrid Loss Training
May 30, 2025Semantic textual similarity (STS) is a critical task in natural language processing (NLP), enabling applications in retrieval, clustering, and understanding semantic relationships between texts. However, research in this area for the Arabic language remains limited due to the lack of high-quality datasets and pre-trained models. This scarcity of resources has restricted the accurate evaluation and advance of semantic similarity in Arabic text. This paper introduces General Arabic Text Embedding (GATE) models that achieve state-of-the-art performance on the Semantic Textual Similarity task within the MTEB benchmark. GATE leverages Matryoshka Representation Learning and a hybrid loss training approach with Arabic triplet datasets for Natural Language Inference, which are essential for enhancing model performance in tasks that demand fine-grained semantic understanding. GATE outperforms larger models, including OpenAI, with a 20-25% performance improvement on STS benchmarks, effectively capturing the unique semantic nuances of Arabic.
SARD: A Large-Scale Synthetic Arabic OCR Dataset for Book-Style Text Recognition
May 30, 2025Arabic Optical Character Recognition (OCR) is essential for converting vast amounts of Arabic print media into digital formats. However, training modern OCR models, especially powerful vision-language models, is hampered by the lack of large, diverse, and well-structured datasets that mimic real-world book layouts. Existing Arabic OCR datasets often focus on isolated words or lines or are limited in scale, typographic variety, or structural complexity found in books. To address this significant gap, we introduce SARD (Large-Scale Synthetic Arabic OCR Dataset). SARD is a massive, synthetically generated dataset specifically designed to simulate book-style documents. It comprises 843,622 document images containing 690 million words, rendered across ten distinct Arabic fonts to ensure broad typographic coverage. Unlike datasets derived from scanned documents, SARD is free from real-world noise and distortions, offering a clean and controlled environment for model training. Its synthetic nature provides unparalleled scalability and allows for precise control over layout and content variation. We detail the dataset's composition and generation process and provide benchmark results for several OCR models, including traditional and deep learning approaches, highlighting the challenges and opportunities presented by this dataset. SARD serves as a valuable resource for developing and evaluating robust OCR and vision-language models capable of processing diverse Arabic book-style texts.
Pearl: A Multimodal Culturally-Aware Arabic Instruction Dataset
May 28, 2025Mainstream large vision-language models (LVLMs) inherently encode cultural biases, highlighting the need for diverse multimodal datasets. To address this gap, we introduce Pearl, a large-scale Arabic multimodal dataset and benchmark explicitly designed for cultural understanding. Constructed through advanced agentic workflows and extensive human-in-the-loop annotations by 45 annotators from across the Arab world, Pearl comprises over K multimodal examples spanning ten culturally significant domains covering all Arab countries. We further provide two robust evaluation benchmarks Pearl and Pearl-Lite along with a specialized subset Pearl-X explicitly developed to assess nuanced cultural variations. Comprehensive evaluations on state-of-the-art open and proprietary LVLMs demonstrate that reasoning-centric instruction alignment substantially improves models' cultural grounding compared to conventional scaling methods. Pearl establishes a foundational resource for advancing culturally-informed multimodal modeling research. All datasets and benchmarks are publicly available.
Advancing Arabic Reverse Dictionary Systems: A Transformer-Based Approach with Dataset Construction Guidelines
Apr 30, 2025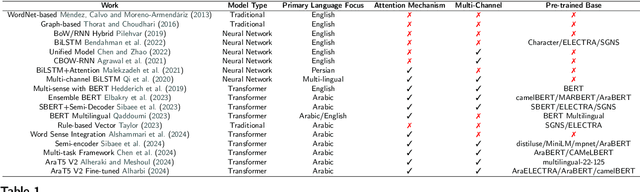
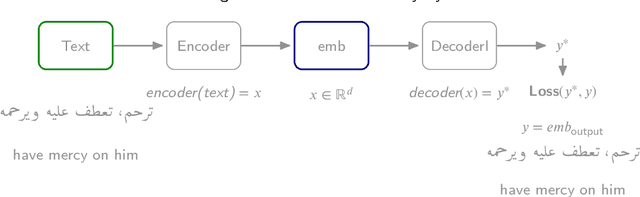

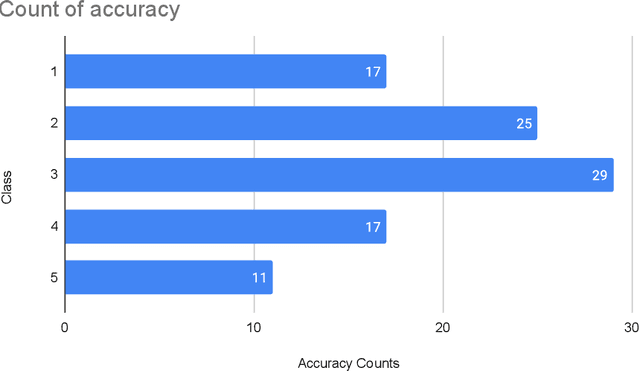
This study addresses the critical gap in Arabic natural language processing by developing an effective Arabic Reverse Dictionary (RD) system that enables users to find words based on their descriptions or meanings. We present a novel transformer-based approach with a semi-encoder neural network architecture featuring geometrically decreasing layers that achieves state-of-the-art results for Arabic RD tasks. Our methodology incorporates a comprehensive dataset construction process and establishes formal quality standards for Arabic lexicographic definitions. Experiments with various pre-trained models demonstrate that Arabic-specific models significantly outperform general multilingual embeddings, with ARBERTv2 achieving the best ranking score (0.0644). Additionally, we provide a formal abstraction of the reverse dictionary task that enhances theoretical understanding and develop a modular, extensible Python library (RDTL) with configurable training pipelines. Our analysis of dataset quality reveals important insights for improving Arabic definition construction, leading to eight specific standards for building high-quality reverse dictionary resources. This work contributes significantly to Arabic computational linguistics and provides valuable tools for language learning, academic writing, and professional communication in Arabic.
ArabianGPT: Native Arabic GPT-based Large Language Model
Feb 26, 2024The predominance of English and Latin-based large language models (LLMs) has led to a notable deficit in native Arabic LLMs. This discrepancy is accentuated by the prevalent inclusion of English tokens in existing Arabic models, detracting from their efficacy in processing native Arabic's intricate morphology and syntax. Consequently, there is a theoretical and practical imperative for developing LLMs predominantly focused on Arabic linguistic elements. To address this gap, this paper proposes ArabianGPT, a series of transformer-based models within the ArabianLLM suite designed explicitly for Arabic. These models, including ArabianGPT-0.1B and ArabianGPT-0.3B, vary in size and complexity, aligning with the nuanced linguistic characteristics of Arabic. The AraNizer tokenizer, integral to these models, addresses the unique morphological aspects of Arabic script, ensuring more accurate text processing. Empirical results from fine-tuning the models on tasks like sentiment analysis and summarization demonstrate significant improvements. For sentiment analysis, the fine-tuned ArabianGPT-0.1B model achieved a remarkable accuracy of 95%, a substantial increase from the base model's 56%. Similarly, in summarization tasks, fine-tuned models showed enhanced F1 scores, indicating improved precision and recall in generating concise summaries. Comparative analysis of fine-tuned ArabianGPT models against their base versions across various benchmarks reveals nuanced differences in performance, with fine-tuning positively impacting specific tasks like question answering and summarization. These findings underscore the efficacy of fine-tuning in aligning ArabianGPT models more closely with specific NLP tasks, highlighting the potential of tailored transformer architectures in advancing Arabic NLP.
Prediction of Arabic Legal Rulings using Large Language Models
Oct 16, 2023



In the intricate field of legal studies, the analysis of court decisions is a cornerstone for the effective functioning of the judicial system. The ability to predict court outcomes helps judges during the decision-making process and equips lawyers with invaluable insights, enhancing their strategic approaches to cases. Despite its significance, the domain of Arabic court analysis remains under-explored. This paper pioneers a comprehensive predictive analysis of Arabic court decisions on a dataset of 10,813 commercial court real cases, leveraging the advanced capabilities of the current state-of-the-art large language models. Through a systematic exploration, we evaluate three prevalent foundational models (LLaMA-7b, JAIS-13b, and GPT3.5-turbo) and three training paradigms: zero-shot, one-shot, and tailored fine-tuning. Besides, we assess the benefit of summarizing and/or translating the original Arabic input texts. This leads to a spectrum of 14 model variants, for which we offer a granular performance assessment with a series of different metrics (human assessment, GPT evaluation, ROUGE, and BLEU scores). We show that all variants of LLaMA models yield limited performance, whereas GPT-3.5-based models outperform all other models by a wide margin, surpassing the average score of the dedicated Arabic-centric JAIS model by 50%. Furthermore, we show that all scores except human evaluation are inconsistent and unreliable for assessing the performance of large language models on court decision predictions. This study paves the way for future research, bridging the gap between computational linguistics and Arabic legal analytics.