 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Robustness of Vision in Open Foundation Models
Dec 19, 2025



With the increase in deep learning, it becomes increasingly difficult to understand the model in which AI systems can identify objects. Thus, an adversary could aim to modify an image by adding unseen elements, which will confuse the AI in its recognition of an entity. This paper thus investigates the adversarial robustness of LLaVA-1.5-13B and Meta's Llama 3.2 Vision-8B-2. These are tested for untargeted PGD (Projected Gradient Descent) against the visual input modality, and empirically evaluated on the Visual Question Answering (VQA) v2 dataset subset. The results of these adversarial attacks are then quantified using the standard VQA accuracy metric. This evaluation is then compared with the accuracy degradation (accuracy drop) of LLaVA and Llama 3.2 Vision. A key finding is that Llama 3.2 Vision, despite a lower baseline accuracy in this setup, exhibited a smaller drop in performance under attack compared to LLaVA, particularly at higher perturbation levels. Overall, the findings confirm that the vision modality represents a viable attack vector for degrading the performance of contemporary open-weight VLMs, including Meta's Llama 3.2 Vision. Furthermore, they highlight that adversarial robustness does not necessarily correlate directly with standard benchmark performance and may be influenced by underlying architectural and training factors.
Comparative Analysis of Hash-based Malware Clustering via K-Means
Dec 10, 2025With the adoption of multiple digital devices in everyday life, the cyber-attack surface has increased. Adversaries are continuously exploring new avenues to exploit them and deploy malware. On the other hand, detection approaches typically employ hashing-based algorithms such as SSDeep, TLSH, and IMPHash to capture structural and behavioural similarities among binaries. This work focuses on the analysis and evaluation of these techniques for clustering malware samples using the K-means algorithm. More specifically, we experimented with established malware families and traits and found that TLSH and IMPHash produce more distinct, semantically meaningful clusters, whereas SSDeep is more efficient for broader classification tasks. The findings of this work can guide the development of more robust threat-detection mechanisms and adaptive security mechanisms.
Launching Adversarial Attacks against Network Intrusion Detection Systems for IoT
Apr 26, 2021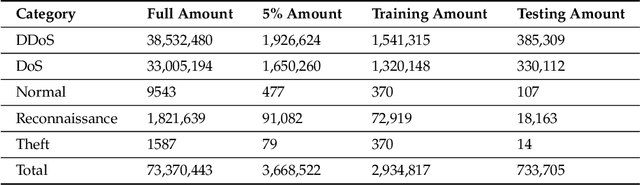
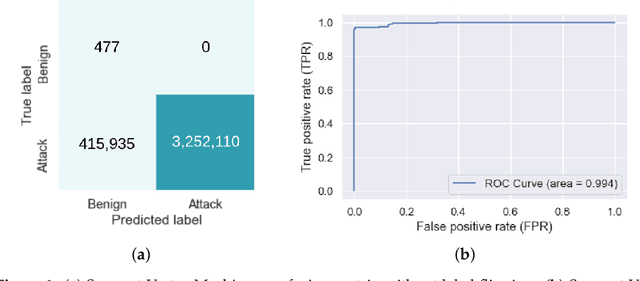
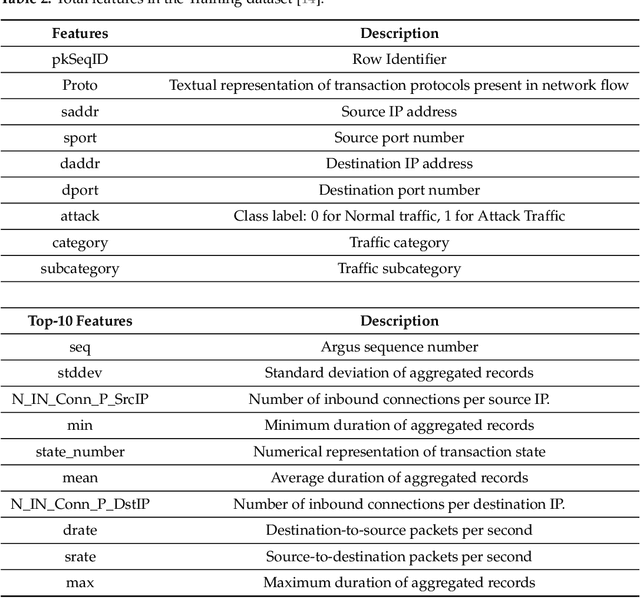
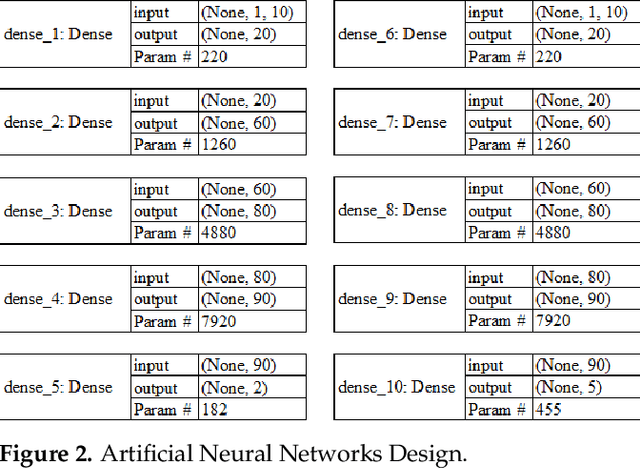
As the internet continues to be populated with new devices and emerging technologies, the attack surface grows exponentially. Technology is shifting towards a profit-driven Internet of Things market where security is an afterthought. Traditional defending approaches are no longer sufficient to detect both known and unknown attacks to high accuracy. Machine learning intrusion detection systems have proven their success in identifying unknown attacks with high precision. Nevertheless, machine learning models are also vulnerable to attacks. Adversarial examples can be used to evaluate the robustness of a designed model before it is deployed. Further, using adversarial examples is critical to creating a robust model designed for an adversarial environment. Our work evaluates both traditional machine learning and deep learning models' robustness using the Bot-IoT dataset. Our methodology included two main approaches. First, label poisoning, used to cause incorrect classification by the model. Second, the fast gradient sign method, used to evade detection measures. The experiments demonstrated that an attacker could manipulate or circumvent detection with significant probability.
* MDPI Mach. Learn. Knowl. Extr. 2021, 3(2), 333-356; https://www.mdpi.com/2624-800X/1/2/14
Practical Defences Against Model Inversion Attacks for Split Neural Networks
Apr 21, 2021
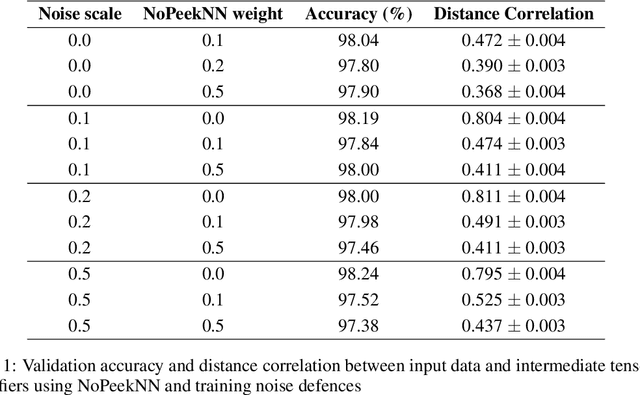


We describe a threat model under which a split network-based federated learning system is susceptible to a model inversion attack by a malicious computational server. We demonstrate that the attack can be successfully performed with limited knowledge of the data distribution by the attacker. We propose a simple additive noise method to defend against model inversion, finding that the method can significantly reduce attack efficacy at an acceptable accuracy trade-off on MNIST. Furthermore, we show that NoPeekNN, an existing defensive method, protects different information from exposure, suggesting that a combined defence is necessary to fully protect private user data.
PyVertical: A Vertical Federated Learning Framework for Multi-headed SplitNN
Apr 14, 2021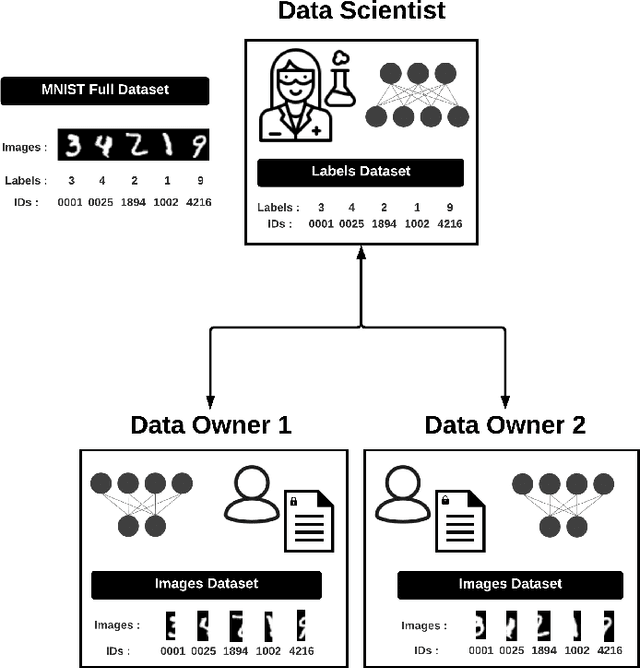
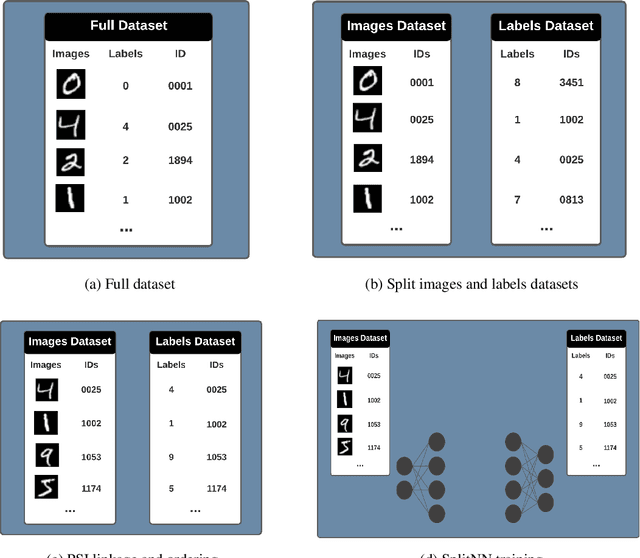
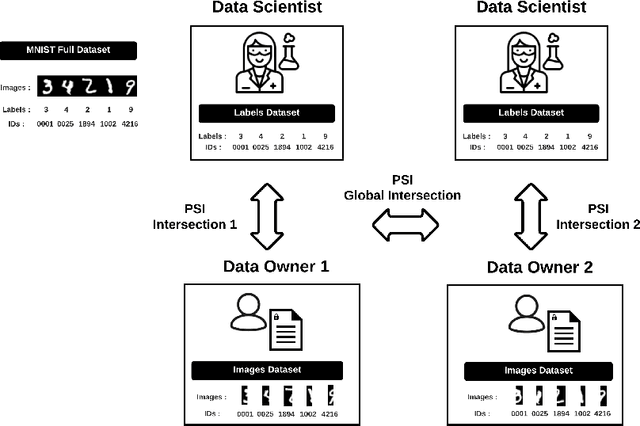
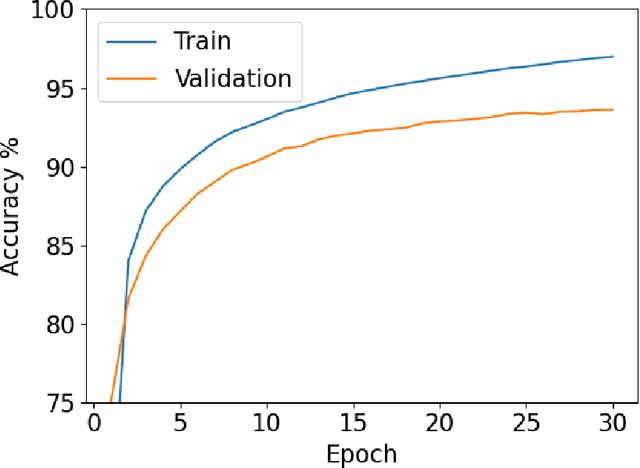
We introduce PyVertical, a framework supporting vertical federated learning using split neural networks. The proposed framework allows a data scientist to train neural networks on data features vertically partitioned across multiple owners while keeping raw data on an owner's device. To link entities shared across different datasets' partitions, we use Private Set Intersection on IDs associated with data points. To demonstrate the validity of the proposed framework, we present the training of a simple dual-headed split neural network for a MNIST classification task, with data samples vertically distributed across two data owners and a data scientist.
Privacy and Trust Redefined in Federated Machine Learning
Mar 30, 2021
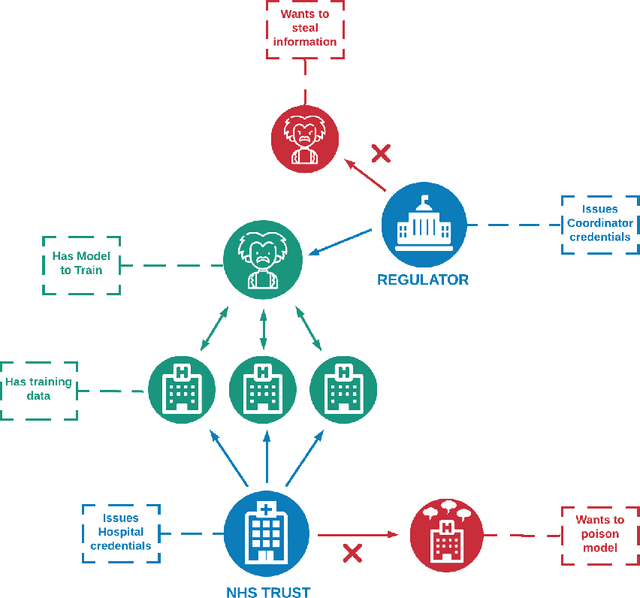
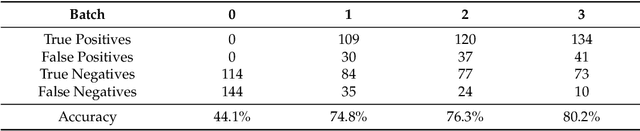
A common privacy issue in traditional machine learning is that data needs to be disclosed for the training procedures. In situations with highly sensitive data such as healthcare records, accessing this information is challenging and often prohibited. Luckily, privacy-preserving technologies have been developed to overcome this hurdle by distributing the computation of the training and ensuring the data privacy to their owners. The distribution of the computation to multiple participating entities introduces new privacy complications and risks. In this paper, we present a privacy-preserving decentralised workflow that facilitates trusted federated learning among participants. Our proof-of-concept defines a trust framework instantiated using decentralised identity technologies being developed under Hyperledger projects Aries/Indy/Ursa. Only entities in possession of Verifiable Credentials issued from the appropriate authorities are able to establish secure, authenticated communication channels authorised to participate in a federated learning workflow related to mental health data.
* MDPI Mach. Learn. Knowl. Extr. 2021, 3(2), 333-356; https://doi.org/10.3390/make3020017
Asymmetric Private Set Intersection with Applications to Contact Tracing and Private Vertical Federated Machine Learning
Nov 18, 2020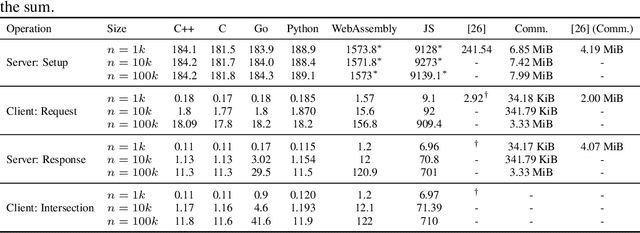
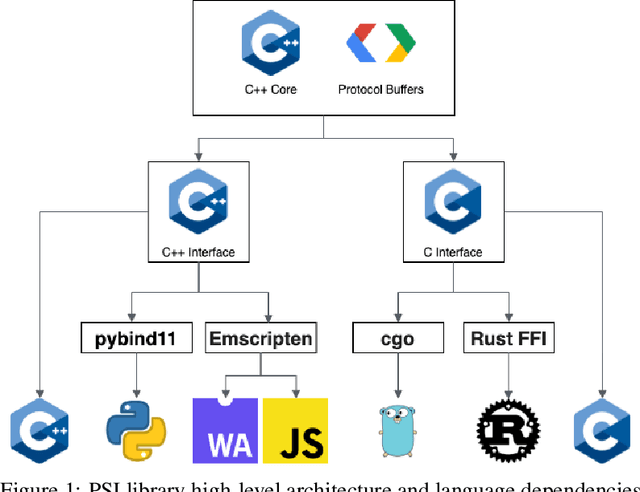
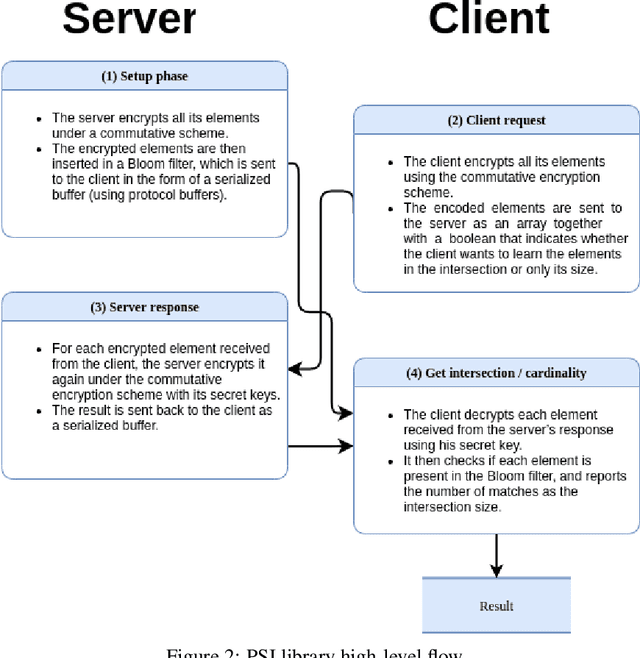

We present a multi-language, cross-platform, open-source library for asymmetric private set intersection (PSI) and PSI-Cardinality (PSI-C). Our protocol combines traditional DDH-based PSI and PSI-C protocols with compression based on Bloom filters that helps reduce communication in the asymmetric setting. Currently, our library supports C++, C, Go, WebAssembly, JavaScript, Python, and Rust, and runs on both traditional hardware (x86) and browser targets. We further apply our library to two use cases: (i) a privacy-preserving contact tracing protocol that is compatible with existing approaches, but improves their privacy guarantees, and (ii) privacy-preserving machine learning on vertically partitioned data.
A Distributed Trust Framework for Privacy-Preserving Machine Learning
Jun 03, 2020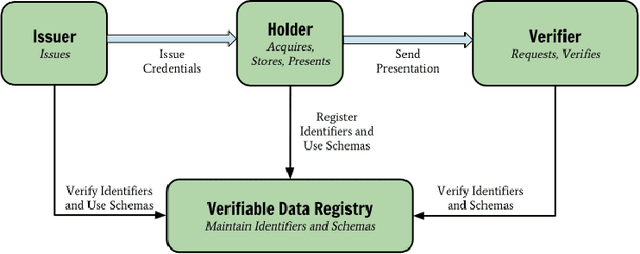
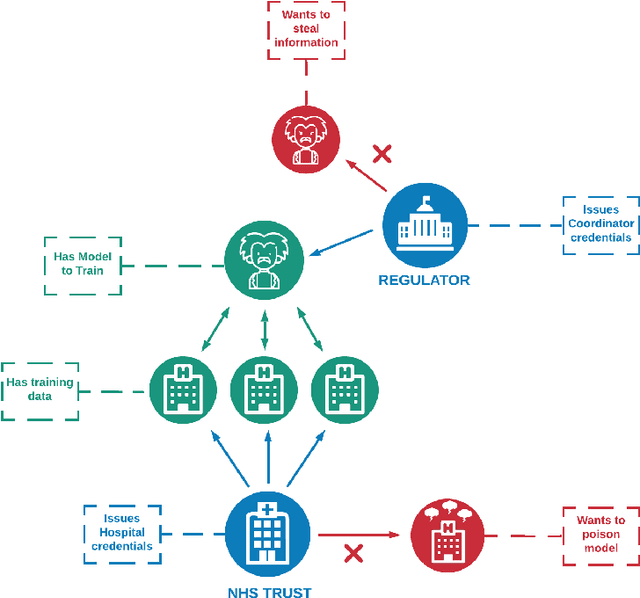

When training a machine learning model, it is standard procedure for the researcher to have full knowledge of both the data and model. However, this engenders a lack of trust between data owners and data scientists. Data owners are justifiably reluctant to relinquish control of private information to third parties. Privacy-preserving techniques distribute computation in order to ensure that data remains in the control of the owner while learning takes place. However, architectures distributed amongst multiple agents introduce an entirely new set of security and trust complications. These include data poisoning and model theft. This paper outlines a distributed infrastructure which is used to facilitate peer-to-peer trust between distributed agents; collaboratively performing a privacy-preserving workflow. Our outlined prototype sets industry gatekeepers and governance bodies as credential issuers. Before participating in the distributed learning workflow, malicious actors must first negotiate valid credentials. We detail a proof of concept using Hyperledger Aries, Decentralised Identifiers (DIDs) and Verifiable Credentials (VCs) to establish a distributed trust architecture during a privacy-preserving machine learning experiment. Specifically, we utilise secure and authenticated DID communication channels in order to facilitate a federated learning workflow related to mental health care data.
Phishing URL Detection Through Top-level Domain Analysis: A Descriptive Approach
May 13, 2020
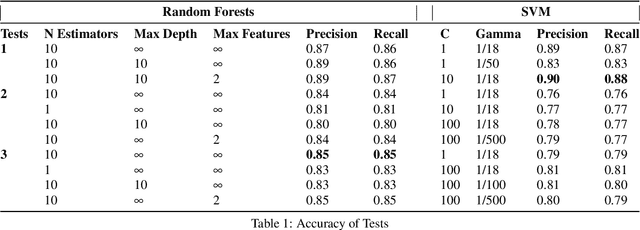
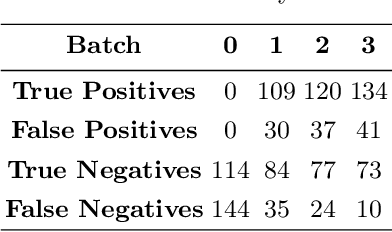
Phishing is considered to be one of the most prevalent cyber-attacks because of its immense flexibility and alarmingly high success rate. Even with adequate training and high situational awareness, it can still be hard for users to continually be aware of the URL of the website they are visiting. Traditional detection methods rely on blocklists and content analysis, both of which require time-consuming human verification. Thus, there have been attempts focusing on the predictive filtering of such URLs. This study aims to develop a machine-learning model to detect fraudulent URLs which can be used within the Splunk platform. Inspired from similar approaches in the literature, we trained the SVM and Random Forests algorithms using malicious and benign datasets found in the literature and one dataset that we created. We evaluated the algorithms' performance with precision and recall, reaching up to 85% precision and 87% recall in the case of Random Forests while SVM achieved up to 90% precision and 88% recall using only descriptive features.
* In Proceedings of the 6th ICISSP