 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMIMIC: Multimodal Inversion for Model Interpretation and Conceptualization
Aug 11, 2025Vision Language Models (VLMs) encode multimodal inputs over large, complex, and difficult-to-interpret architectures, which limit transparency and trust. We propose a Multimodal Inversion for Model Interpretation and Conceptualization (MIMIC) framework to visualize the internal representations of VLMs by synthesizing visual concepts corresponding to internal encodings. MIMIC uses a joint VLM-based inversion and a feature alignment objective to account for VLM's autoregressive processing. It additionally includes a triplet of regularizers for spatial alignment, natural image smoothness, and semantic realism. We quantitatively and qualitatively evaluate MIMIC by inverting visual concepts over a range of varying-length free-form VLM output texts. Reported results include both standard visual quality metrics as well as semantic text-based metrics. To the best of our knowledge, this is the first model inversion approach addressing visual interpretations of VLM concepts.
About Time: Advances, Challenges, and Outlooks of Action Understanding
Nov 22, 2024



We have witnessed impressive advances in video action understanding. Increased dataset sizes, variability, and computation availability have enabled leaps in performance and task diversification. Current systems can provide coarse- and fine-grained descriptions of video scenes, extract segments corresponding to queries, synthesize unobserved parts of videos, and predict context. This survey comprehensively reviews advances in uni- and multi-modal action understanding across a range of tasks. We focus on prevalent challenges, overview widely adopted datasets, and survey seminal works with an emphasis on recent advances. We broadly distinguish between three temporal scopes: (1) recognition tasks of actions observed in full, (2) prediction tasks for ongoing partially observed actions, and (3) forecasting tasks for subsequent unobserved action. This division allows us to identify specific action modeling and video representation challenges. Finally, we outline future directions to address current shortcomings.
LAVIB: A Large-scale Video Interpolation Benchmark
Jun 14, 2024This paper introduces a LArge-scale Video Interpolation Benchmark (LAVIB) for the low-level video task of video frame interpolation (VFI). LAVIB comprises a large collection of high-resolution videos sourced from the web through an automated pipeline with minimal requirements for human verification. Metrics are computed for each video's motion magnitudes, luminance conditions, frame sharpness, and contrast. The collection of videos and the creation of quantitative challenges based on these metrics are under-explored by current low-level video task datasets. In total, LAVIB includes 283K clips from 17K ultra-HD videos, covering 77.6 hours. Benchmark train, val, and test sets maintain similar video metric distributions. Further splits are also created for out-of-distribution (OOD) challenges, with train and test splits including videos of dissimilar attributes.
Every Shot Counts: Using Exemplars for Repetition Counting in Videos
Mar 26, 2024



Video repetition counting infers the number of repetitions of recurring actions or motion within a video. We propose an exemplar-based approach that discovers visual correspondence of video exemplars across repetitions within target videos. Our proposed Every Shot Counts (ESCounts) model is an attention-based encoder-decoder that encodes videos of varying lengths alongside exemplars from the same and different videos. In training, ESCounts regresses locations of high correspondence to the exemplars within the video. In tandem, our method learns a latent that encodes representations of general repetitive motions, which we use for exemplar-free, zero-shot inference. Extensive experiments over commonly used datasets (RepCount, Countix, and UCFRep) showcase ESCounts obtaining state-of-the-art performance across all three datasets. On RepCount, ESCounts increases the off-by-one from 0.39 to 0.56 and decreases the mean absolute error from 0.38 to 0.21. Detailed ablations further demonstrate the effectiveness of our method.
Holistic Representation Learning for Multitask Trajectory Anomaly Detection
Nov 03, 2023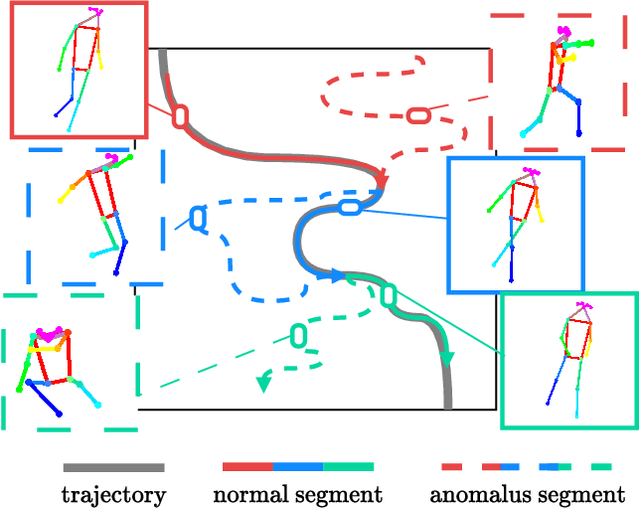

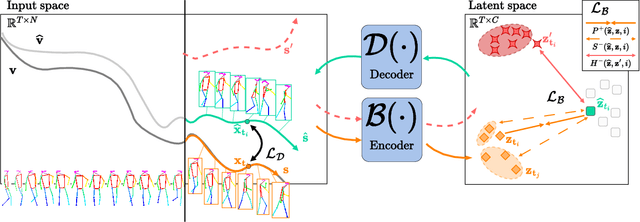
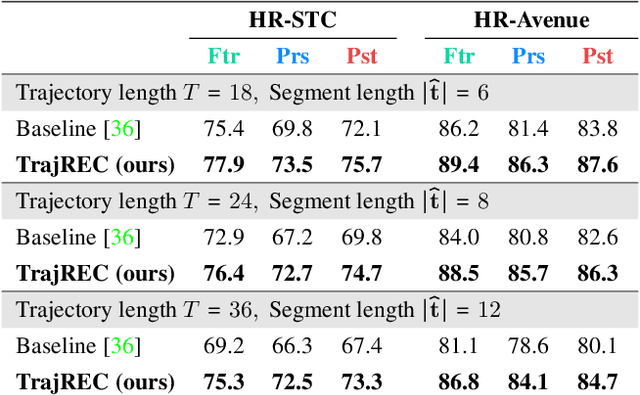
Video anomaly detection deals with the recognition of abnormal events in videos. Apart from the visual signal, video anomaly detection has also been addressed with the use of skeleton sequences. We propose a holistic representation of skeleton trajectories to learn expected motions across segments at different times. Our approach uses multitask learning to reconstruct any continuous unobserved temporal segment of the trajectory allowing the extrapolation of past or future segments and the interpolation of in-between segments. We use an end-to-end attention-based encoder-decoder. We encode temporally occluded trajectories, jointly learn latent representations of the occluded segments, and reconstruct trajectories based on expected motions across different temporal segments. Extensive experiments on three trajectory-based video anomaly detection datasets show the advantages and effectiveness of our approach with state-of-the-art results on anomaly detection in skeleton trajectories.
Leaping Into Memories: Space-Time Deep Feature Synthesis
Mar 29, 2023



The success of deep learning models has led to their adaptation and adoption by prominent video understanding methods. The majority of these approaches encode features in a joint space-time modality for which the inner workings and learned representations are difficult to visually interpret. We propose LEArned Preconscious Synthesis (LEAPS), an architecture-agnostic method for synthesizing videos from the internal spatiotemporal representations of models. Using a stimulus video and a target class, we prime a fixed space-time model and iteratively optimize a video initialized with random noise. We incorporate additional regularizers to improve the feature diversity of the synthesized videos as well as the cross-frame temporal coherence of motions. We quantitatively and qualitatively evaluate the applicability of LEAPS by inverting a range of spatiotemporal convolutional and attention-based architectures trained on Kinetics-400, which to the best of our knowledge has not been previously accomplished.
Play It Back: Iterative Attention for Audio Recognition
Oct 20, 2022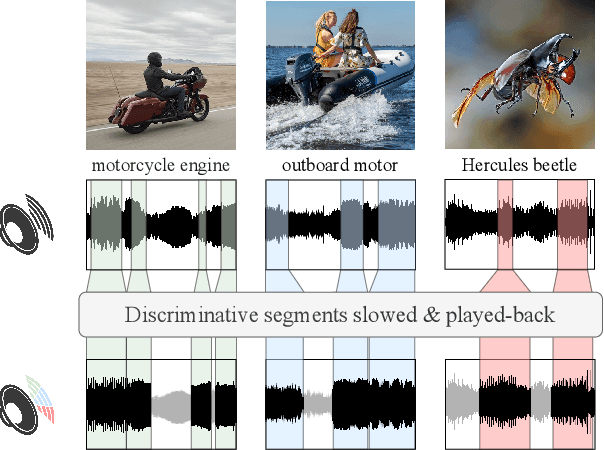
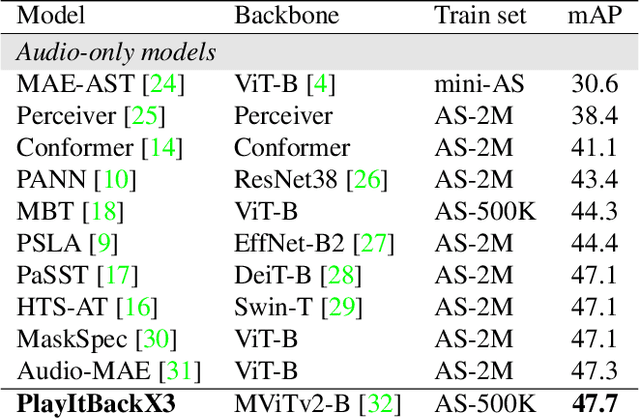
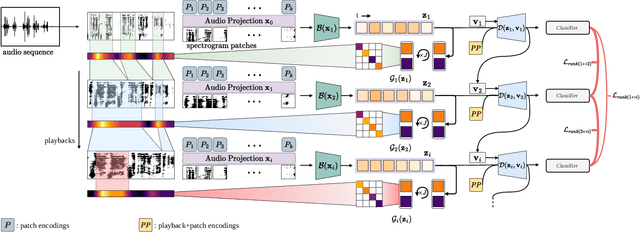
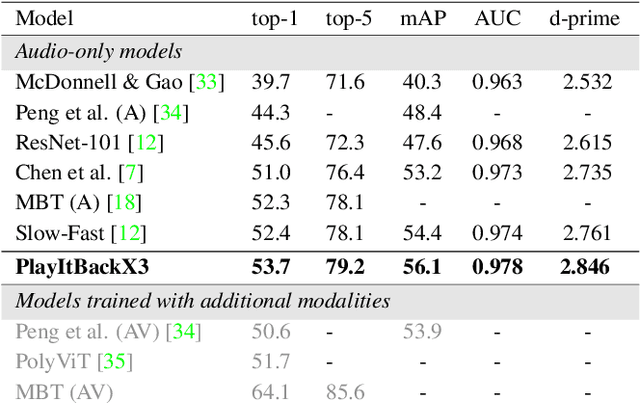
A key function of auditory cognition is the association of characteristic sounds with their corresponding semantics over time. Humans attempting to discriminate between fine-grained audio categories, often replay the same discriminative sounds to increase their prediction confidence. We propose an end-to-end attention-based architecture that through selective repetition attends over the most discriminative sounds across the audio sequence. Our model initially uses the full audio sequence and iteratively refines the temporal segments replayed based on slot attention. At each playback, the selected segments are replayed using a smaller hop length which represents higher resolution features within these segments. We show that our method can consistently achieve state-of-the-art performance across three audio-classification benchmarks: AudioSet, VGG-Sound, and EPIC-KITCHENS-100.
Temporal Progressive Attention for Early Action Prediction
Apr 28, 2022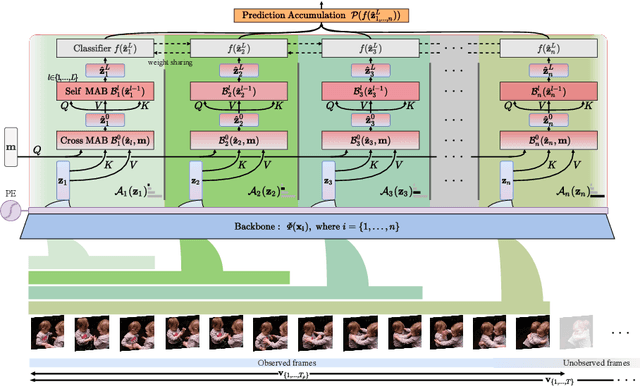
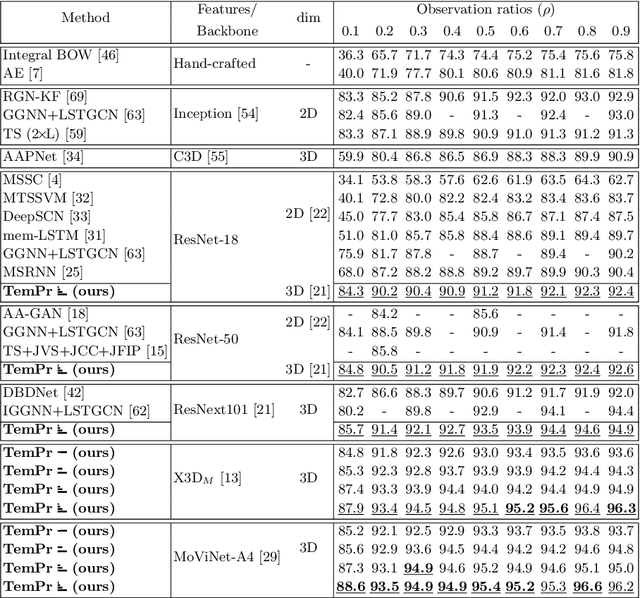
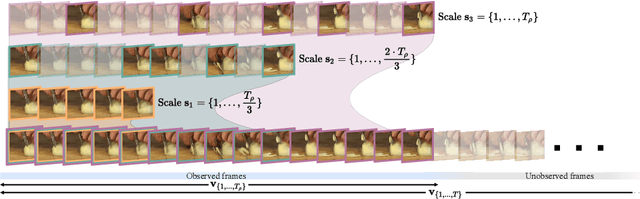
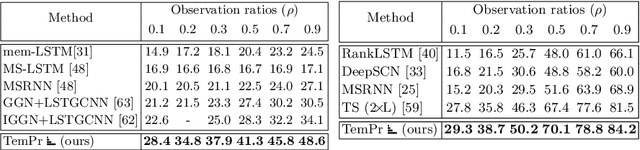
Early action prediction deals with inferring the ongoing action from partially-observed videos, typically at the outset of the video. We propose a bottleneck-based attention model that captures the evolution of the action, through progressive sampling over fine-to-coarse scales. Our proposed Temporal Progressive (TemPr) model is composed of multiple attention towers, one for each scale. The predicted action label is based on the collective agreement considering confidences of these attention towers. Extensive experiments over three video datasets showcase state-of-the-art performance on the task of Early Action Prediction across a range of backbone architectures. We demonstrate the effectiveness and consistency of TemPr through detailed ablations.
AdaPool: Exponential Adaptive Pooling for Information-Retaining Downsampling
Nov 02, 2021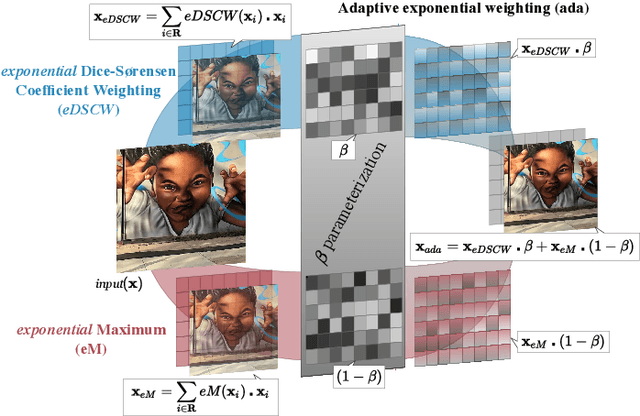
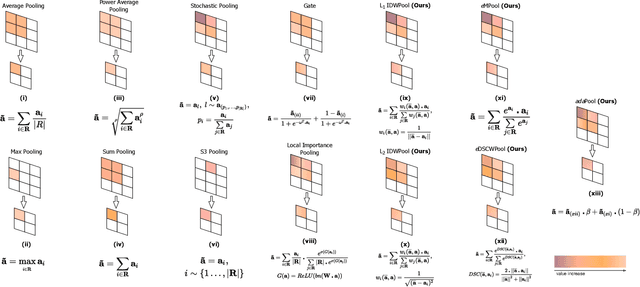


Pooling layers are essential building blocks of Convolutional Neural Networks (CNNs) that reduce computational overhead and increase the receptive fields of proceeding convolutional operations. They aim to produce downsampled volumes that closely resemble the input volume while, ideally, also being computationally and memory efficient. It is a challenge to meet both requirements jointly. To this end, we propose an adaptive and exponentially weighted pooling method named adaPool. Our proposed method uses a parameterized fusion of two sets of pooling kernels that are based on the exponent of the Dice-Sorensen coefficient and the exponential maximum, respectively. A key property of adaPool is its bidirectional nature. In contrast to common pooling methods, weights can be used to upsample a downsampled activation map. We term this method adaUnPool. We demonstrate how adaPool improves the preservation of detail through a range of tasks including image and video classification and object detection. We then evaluate adaUnPool on image and video frame super-resolution and frame interpolation tasks. For benchmarking, we introduce Inter4K, a novel high-quality, high frame-rate video dataset. Our combined experiments demonstrate that adaPool systematically achieves better results across tasks and backbone architectures, while introducing a minor additional computational and memory overhead.
Efficient Modelling Across Time of Human Actions and Interactions
Oct 05, 2021


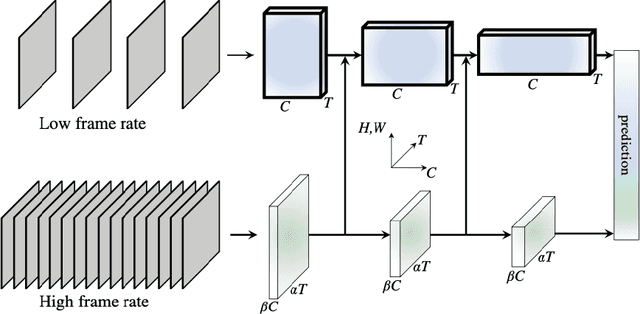
This thesis focuses on video understanding for human action and interaction recognition. We start by identifying the main challenges related to action recognition from videos and review how they have been addressed by current methods. Based on these challenges, and by focusing on the temporal aspect of actions, we argue that current fixed-sized spatio-temporal kernels in 3D convolutional neural networks (CNNs) can be improved to better deal with temporal variations in the input. Our contributions are based on the enlargement of the convolutional receptive fields through the introduction of spatio-temporal size-varying segments of videos, as well as the discovery of the local feature relevance over the entire video sequence. The resulting extracted features encapsulate information that includes the importance of local features across multiple temporal durations, as well as the entire video sequence. Subsequently, we study how we can better handle variations between classes of actions, by enhancing their feature differences over different layers of the architecture. The hierarchical extraction of features models variations of relatively similar classes the same as very dissimilar classes. Therefore, distinctions between similar classes are less likely to be modelled. The proposed approach regularises feature maps by amplifying features that correspond to the class of the video that is processed. We move away from class-agnostic networks and make early predictions based on feature amplification mechanism. The proposed approaches are evaluated on several benchmark action recognition datasets and show competitive results. In terms of performance, we compete with the state-of-the-art while being more efficient in terms of GFLOPs. Finally, we present a human-understandable approach aimed at providing visual explanations for features learned over spatio-temporal networks.