 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast, Scalable, Energy-Efficient Non-element-wise Matrix Multiplication on FPGA
Jul 02, 2024



Modern Neural Network (NN) architectures heavily rely on vast numbers of multiply-accumulate arithmetic operations, constituting the predominant computational cost. Therefore, this paper proposes a high-throughput, scalable and energy efficient non-element-wise matrix multiplication unit on FPGAs as a basic component of the NNs. We firstly streamline inter-layer and intra-layer redundancies of MADDNESS algorithm, a LUT-based approximate matrix multiplication, to design a fast, efficient scalable approximate matrix multiplication module termed "Approximate Multiplication Unit (AMU)". The AMU optimizes LUT-based matrix multiplications further through dedicated memory management and access design, decoupling computational overhead from input resolution and boosting FPGA-based NN accelerator efficiency significantly. The experimental results show that using our AMU achieves up to 9x higher throughput and 112x higher energy efficiency over the state-of-the-art solutions for the FPGA-based Quantised Neural Network (QNN) accelerators.
MAT-CNN-SOPC: Motionless Analysis of Traffic Using Convolutional Neural Networks on System-On-a-Programmable-Chip
Aug 14, 2018
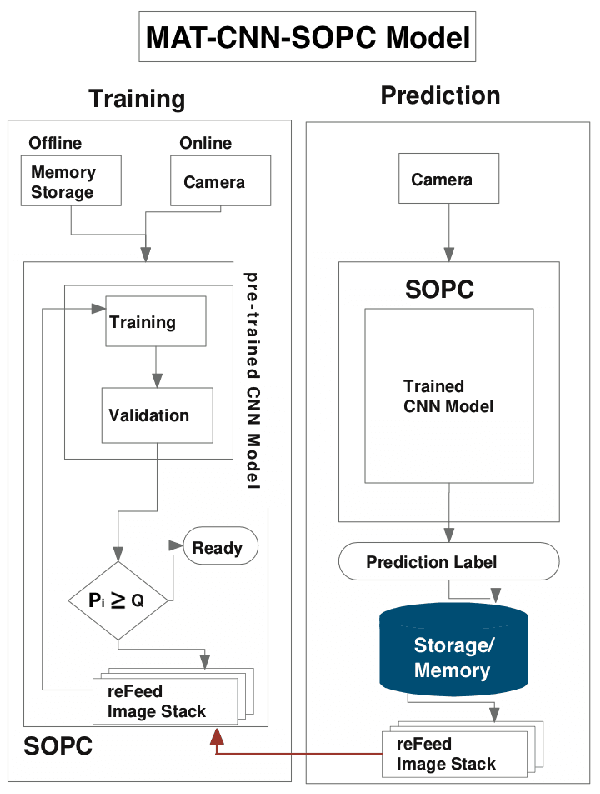
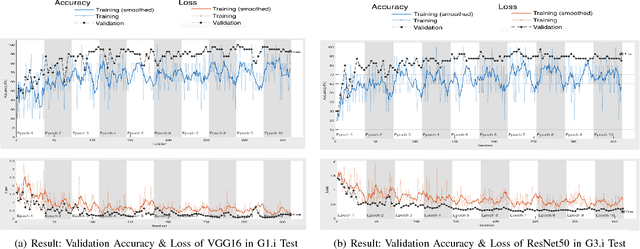
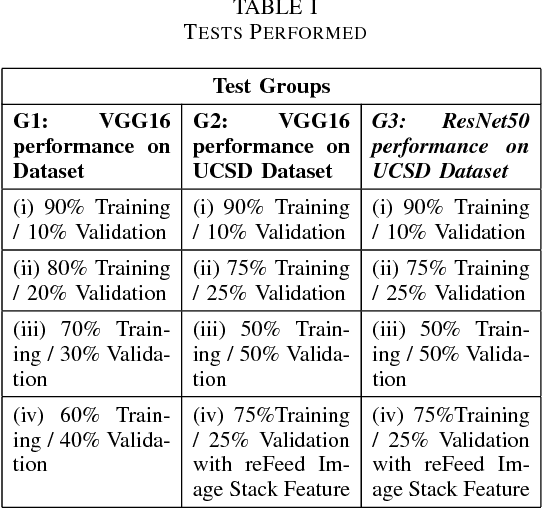
Intelligent Transportation Systems (ITS) have become an important pillar in modern "smart city" framework which demands intelligent involvement of machines. Traffic load recognition can be categorized as an important and challenging issue for such systems. Recently, Convolutional Neural Network (CNN) models have drawn considerable amount of interest in many areas such as weather classification, human rights violation detection through images, due to its accurate prediction capabilities. This work tackles real-life traffic load recognition problem on System-On-a-Programmable-Chip (SOPC) platform and coin it as MAT-CNN- SOPC, which uses an intelligent re-training mechanism of the CNN with known environments. The proposed methodology is capable of enhancing the efficacy of the approach by 2.44x in comparison to the state-of-art and proven through experimental analysis. We have also introduced a mathematical equation, which is capable of quantifying the suitability of using different CNN models over the other for a particular application based implementation.
* 6 pages, 3 figures, 2 tables
A brief experience on journey through hardware developments for image processing and its applications on Cryptography
Dec 27, 2012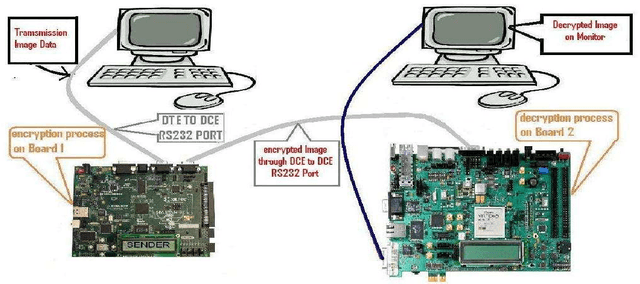
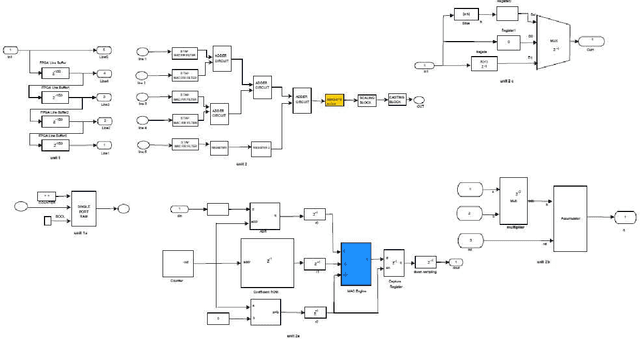
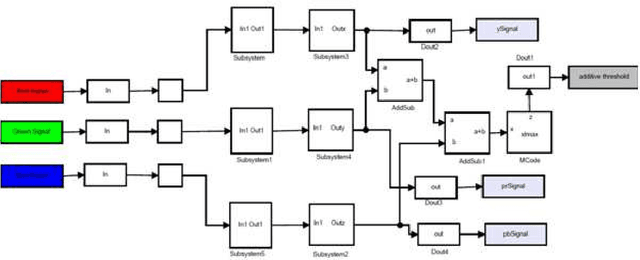
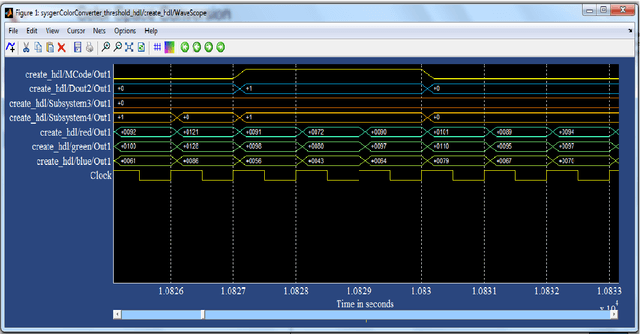
The importance of embedded applications on image and video processing,communication and cryptography domain has been taking a larger space in current research era. Improvement of pictorial information for betterment of human perception like deblurring, de-noising in several fields such as satellite imaging, medical imaging etc are renewed research thrust. Specifically we would like to elaborate our experience on the significance of computer vision as one of the domains where hardware implemented algorithms perform far better than those implemented through software. So far embedded design engineers have successfully implemented their designs by means of Application Specific Integrated Circuits (ASICs) and/or Digital Signal Processors (DSP), however with the advancement of VLSI technology a very powerful hardware device namely the Field Programmable Gate Array (FPGA) combining the key advantages of ASICs and DSPs was developed which have the possibility of reprogramming making them a very attractive device for rapid prototyping.Communication of image and video data in multiple FPGA is no longer far away from the thrust of secured transmission among them, and then the relevance of cryptography is indeed unavoidable. This paper shows how the Xilinx hardware development platform as well Mathworks Matlab can be used to develop hardware based computer vision algorithms and its corresponding crypto transmission channel between multiple FPGA platform from a system level approach, making it favourable for developing a hardware-software co-design environment.