 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Distributed Inference-Only Recommender Systems via Bounded Lag Synchronous Collectives
Dec 22, 2025



Recommender systems are enablers of personalized content delivery, and therefore revenue, for many large companies. In the last decade, deep learning recommender models (DLRMs) are the de-facto standard in this field. The main bottleneck in DLRM inference is the lookup of sparse features across huge embedding tables, which are usually partitioned across the aggregate RAM of many nodes. In state-of-the-art recommender systems, the distributed lookup is implemented via irregular all-to-all (alltoallv) communication, and often presents the main bottleneck. Today, most related work sees this operation as a given; in addition, every collective is synchronous in nature. In this work, we propose a novel bounded lag synchronous (BLS) version of the alltoallv operation. The bound can be a parameter allowing slower processes to lag behind entire iterations before the fastest processes block. In special applications such as inference-only DLRM, the accuracy of the application is fully preserved. We implement BLS alltoallv in a new PyTorch Distributed backend and evaluate it with a BLS version of the reference DLRM code. We show that for well balanced, homogeneous-access DLRM runs our BLS technique does not offer notable advantages. But for unbalanced runs, e.g. runs with strongly irregular embedding table accesses or with delays across different processes, our BLS technique improves both the latency and throughput of inference-only DLRM. In the best-case scenario, the proposed reduced synchronisation can mask the delays across processes altogether.
Resource-Efficient Deep Learning: A Survey on Model-, Arithmetic-, and Implementation-Level Techniques
Dec 30, 2021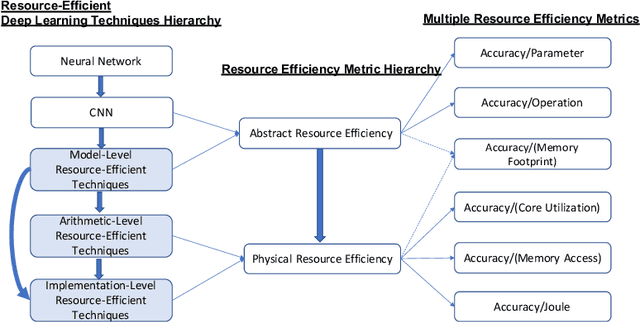
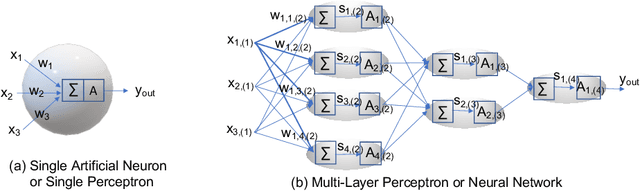
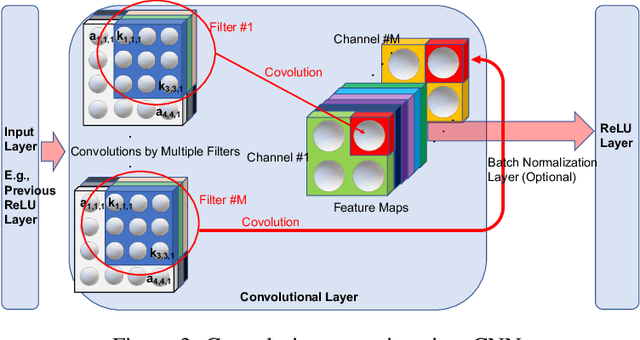
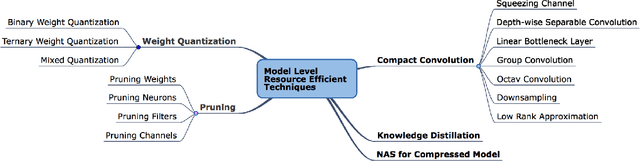
Deep learning is pervasive in our daily life, including self-driving cars, virtual assistants, social network services, healthcare services, face recognition, etc. However, deep neural networks demand substantial compute resources during training and inference. The machine learning community has mainly focused on model-level optimizations such as architectural compression of deep learning models, while the system community has focused on implementation-level optimization. In between, various arithmetic-level optimization techniques have been proposed in the arithmetic community. This article provides a survey on resource-efficient deep learning techniques in terms of model-, arithmetic-, and implementation-level techniques and identifies the research gaps for resource-efficient deep learning techniques across the three different level techniques. Our survey clarifies the influence from higher to lower-level techniques based on our resource-efficiency metric definition and discusses the future trend for resource-efficient deep learning research.