 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLVS-Net: A Lightweight Vessels Segmentation Network for Retinal Image Analysis
Dec 08, 2024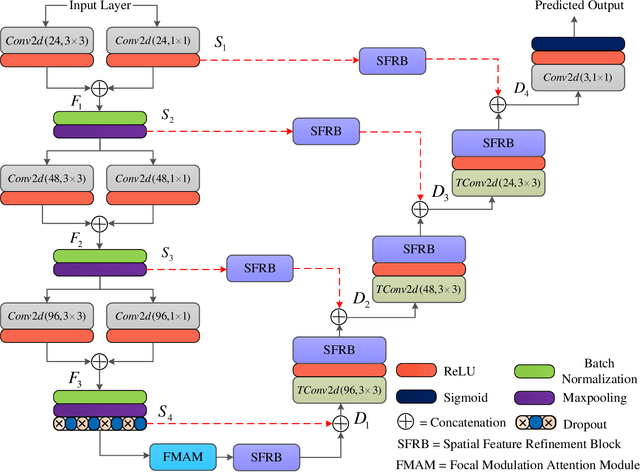
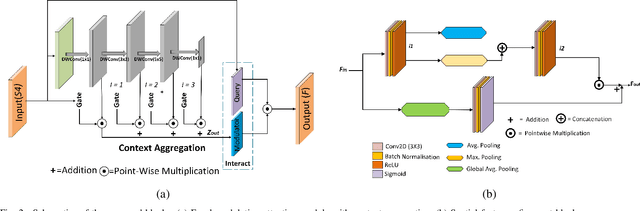
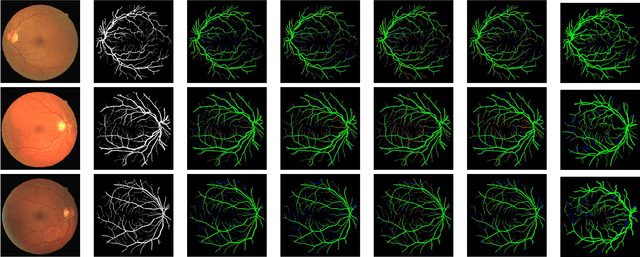

The analysis of retinal images for the diagnosis of various diseases is one of the emerging areas of research. Recently, the research direction has been inclined towards investigating several changes in retinal blood vessels in subjects with many neurological disorders, including dementia. This research focuses on detecting diseases early by improving the performance of models for segmentation of retinal vessels with fewer parameters, which reduces computational costs and supports faster processing. This paper presents a novel lightweight encoder-decoder model that segments retinal vessels to improve the efficiency of disease detection. It incorporates multi-scale convolutional blocks in the encoder to accurately identify vessels of various sizes and thicknesses. The bottleneck of the model integrates the Focal Modulation Attention and Spatial Feature Refinement Blocks to refine and enhance essential features for efficient segmentation. The decoder upsamples features and integrates them with the corresponding feature in the encoder using skip connections and the spatial feature refinement block at every upsampling stage to enhance feature representation at various scales. The estimated computation complexity of our proposed model is around 29.60 GFLOP with 0.71 million parameters and 2.74 MB of memory size, and it is evaluated using public datasets, that is, DRIVE, CHASE\_DB, and STARE. It outperforms existing models with dice scores of 86.44\%, 84.22\%, and 87.88\%, respectively.
DNNShifter: An Efficient DNN Pruning System for Edge Computing
Sep 13, 2023Deep neural networks (DNNs) underpin many machine learning applications. Production quality DNN models achieve high inference accuracy by training millions of DNN parameters which has a significant resource footprint. This presents a challenge for resources operating at the extreme edge of the network, such as mobile and embedded devices that have limited computational and memory resources. To address this, models are pruned to create lightweight, more suitable variants for these devices. Existing pruning methods are unable to provide similar quality models compared to their unpruned counterparts without significant time costs and overheads or are limited to offline use cases. Our work rapidly derives suitable model variants while maintaining the accuracy of the original model. The model variants can be swapped quickly when system and network conditions change to match workload demand. This paper presents DNNShifter, an end-to-end DNN training, spatial pruning, and model switching system that addresses the challenges mentioned above. At the heart of DNNShifter is a novel methodology that prunes sparse models using structured pruning. The pruned model variants generated by DNNShifter are smaller in size and thus faster than dense and sparse model predecessors, making them suitable for inference at the edge while retaining near similar accuracy as of the original dense model. DNNShifter generates a portfolio of model variants that can be swiftly interchanged depending on operational conditions. DNNShifter produces pruned model variants up to 93x faster than conventional training methods. Compared to sparse models, the pruned model variants are up to 5.14x smaller and have a 1.67x inference latency speedup, with no compromise to sparse model accuracy. In addition, DNNShifter has up to 11.9x lower overhead for switching models and up to 3.8x lower memory utilisation than existing approaches.
FedFly: Towards Migration in Edge-based Distributed Federated Learning
Nov 02, 2021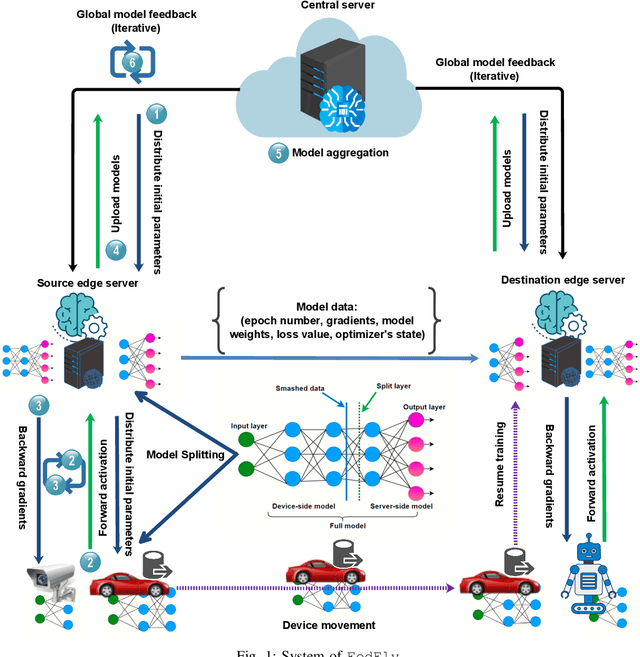
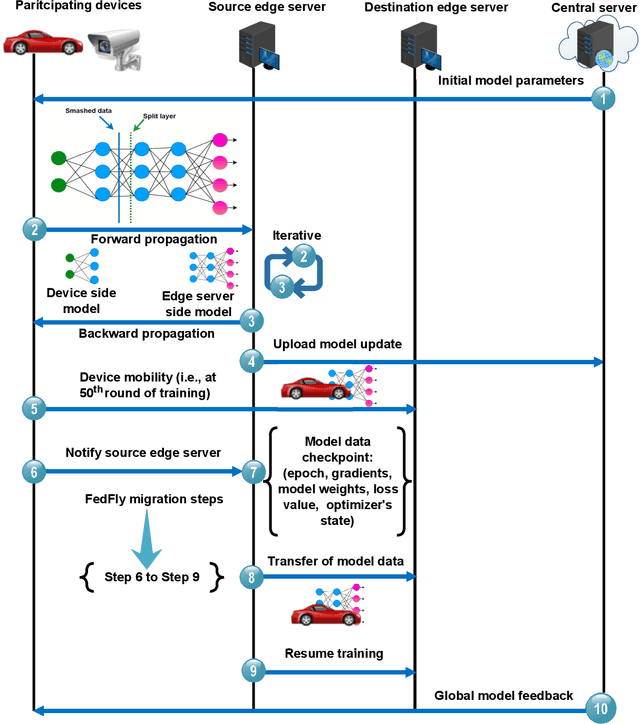
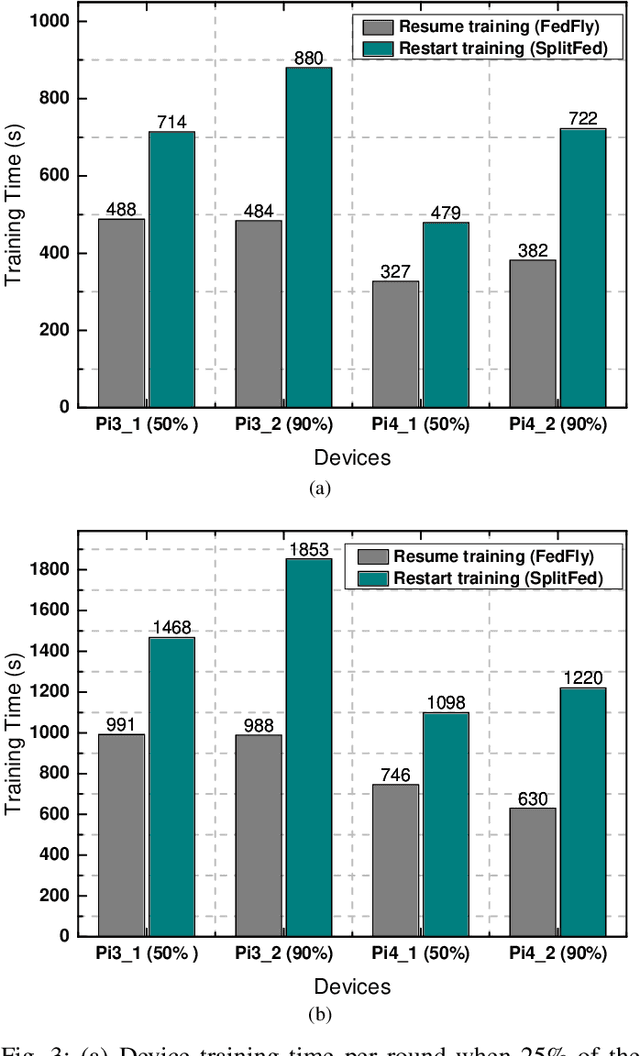
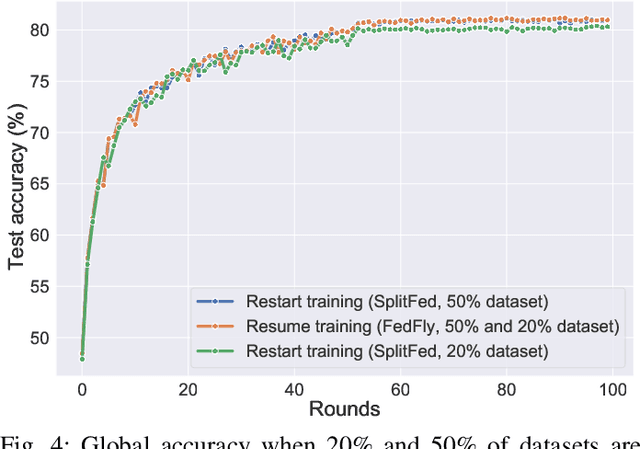
Federated learning (FL) is a privacy-preserving distributed machine learning technique that trains models without having direct access to the original data generated on devices. Since devices may be resource constrained, offloading can be used to improve FL performance by transferring computational workload from devices to edge servers. However, due to mobility, devices participating in FL may leave the network during training and need to connect to a different edge server. This is challenging because the offloaded computations from edge server need to be migrated. In line with this assertion, we present FedFly, which is, to the best of our knowledge, the first work to migrate a deep neural network (DNN) when devices move between edge servers during FL training. Our empirical results on the CIFAR-10 dataset, with both balanced and imbalanced data distribution support our claims that FedFly can reduce training time by up to 33% when a device moves after 50% of the training is completed, and by up to 45% when 90% of the training is completed when compared to state-of-the-art offloading approach in FL. FedFly has negligible overhead of 2 seconds and does not compromise accuracy. Finally, we highlight a number of open research issues for further investigation. FedFly can be downloaded from https://github.com/qub-blesson/FedFly
FedAdapt: Adaptive Offloading for IoT Devices in Federated Learning
Jul 09, 2021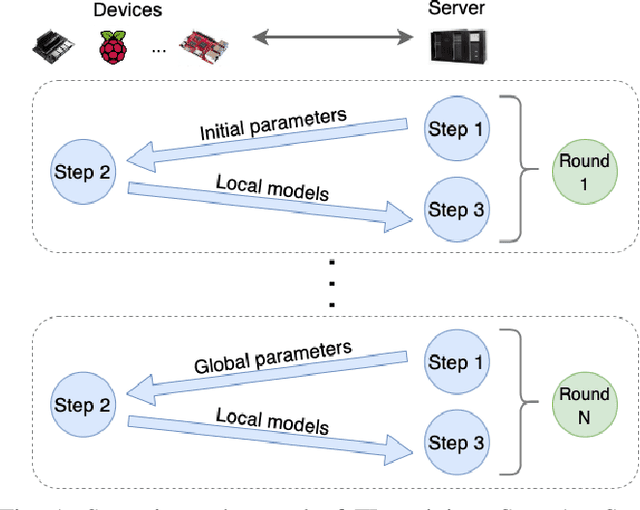
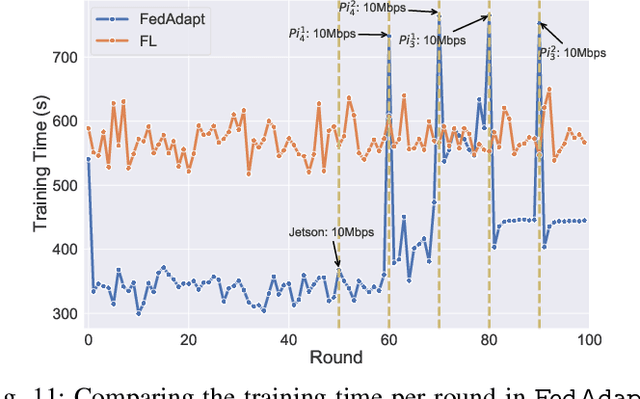

Applying Federated Learning (FL) on Internet-of-Things devices is necessitated by the large volumes of data they produce and growing concerns of data privacy. However, there are three challenges that need to be addressed to make FL efficient: (i) execute on devices with limited computational capabilities, (ii) account for stragglers due to computational heterogeneity of devices, and (iii) adapt to the changing network bandwidths. This paper presents FedAdapt, an adaptive offloading FL framework to mitigate the aforementioned challenges. FedAdapt accelerates local training in computationally constrained devices by leveraging layer offloading of deep neural networks (DNNs) to servers. Further, FedAdapt adopts reinforcement learning-based optimization and clustering to adaptively identify which layers of the DNN should be offloaded for each individual device on to a server to tackle the challenges of computational heterogeneity and changing network bandwidth. Experimental studies are carried out on a lab-based testbed comprising five IoT devices. By offloading a DNN from the device to the server FedAdapt reduces the training time of a typical IoT device by over half compared to classic FL. The training time of extreme stragglers and the overall training time can be reduced by up to 57%. Furthermore, with changing network bandwidth, FedAdapt is demonstrated to reduce the training time by up to 40% when compared to classic FL, without sacrificing accuracy. FedAdapt can be downloaded from https://github.com/qub-blesson/FedAdapt.
A Case For Adaptive Deep Neural Networks in Edge Computing
Aug 04, 2020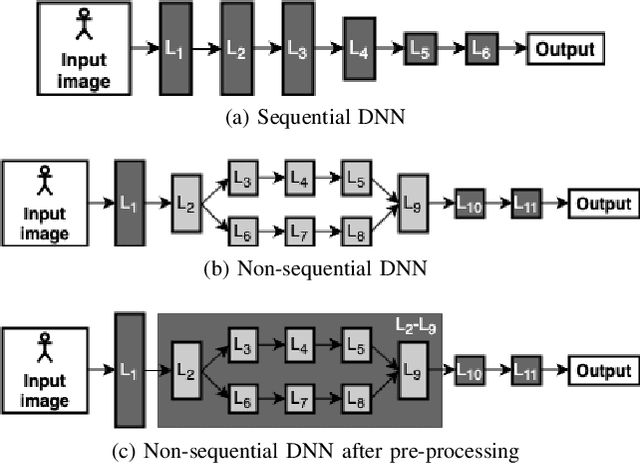
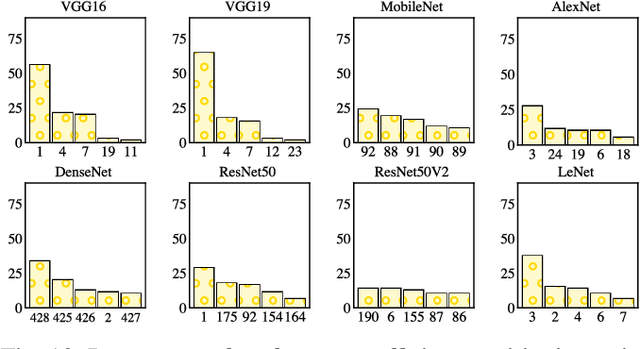
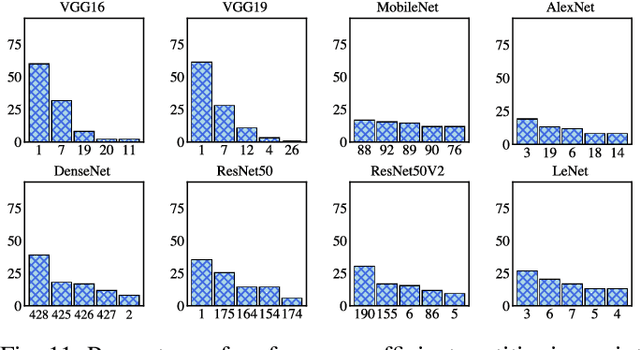
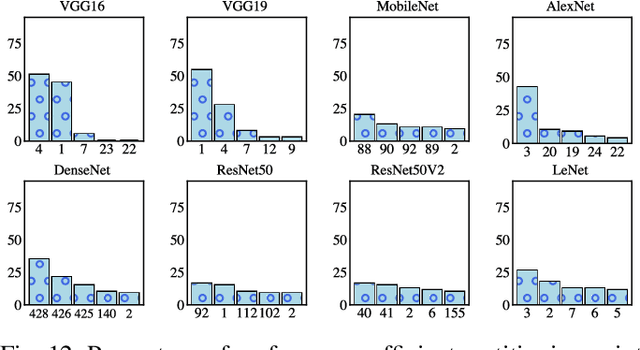
Edge computing offers an additional layer of compute infrastructure closer to the data source before raw data from privacy-sensitive and performance-critical applications is transferred to a cloud data center. Deep Neural Networks (DNNs) are one class of applications that are reported to benefit from collaboratively computing between the edge and the cloud. A DNN is partitioned such that specific layers of the DNN are deployed onto the edge and the cloud to meet performance and privacy objectives. However, there is limited understanding of: (a) whether and how evolving operational conditions (increased CPU and memory utilization at the edge or reduced data transfer rates between the edge and the cloud) affect the performance of already deployed DNNs, and (b) whether a new partition configuration is required to maximize performance. A DNN that adapts to changing operational conditions is referred to as an `adaptive DNN'. This paper investigates whether there is a case for adaptive DNNs in edge computing by considering three questions: (i) Are DNNs sensitive to operational conditions? (ii) How sensitive are DNNs to operational conditions? (iii) Do individual or a combination of operational conditions equally affect DNNs? The exploration is carried out in the context of 8 pre-trained DNN models and the results presented are from analyzing nearly 2 million data points. The results highlight that network conditions affects DNN performance more than CPU or memory related operational conditions. Repartitioning is noted to provide a performance gain in a number of cases, thus demonstrating the need for adaptive DNNs.