 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLVS-Net: A Lightweight Vessels Segmentation Network for Retinal Image Analysis
Dec 08, 2024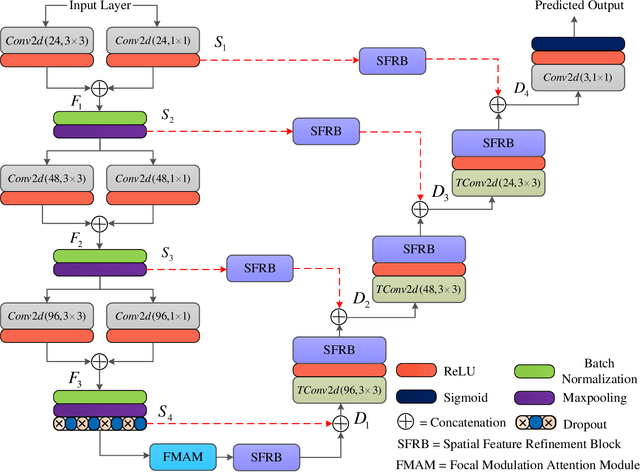
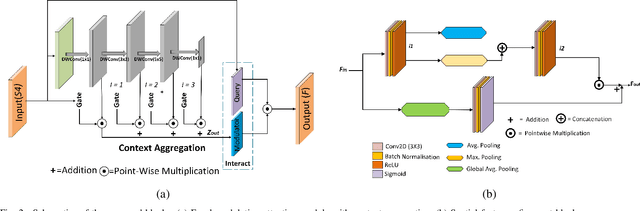
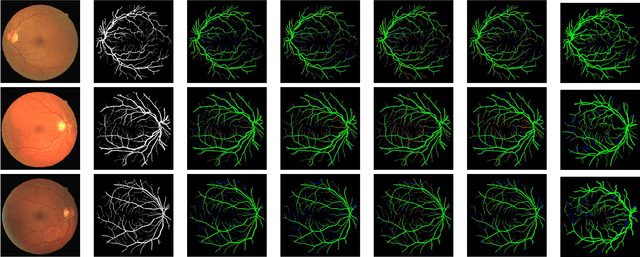

The analysis of retinal images for the diagnosis of various diseases is one of the emerging areas of research. Recently, the research direction has been inclined towards investigating several changes in retinal blood vessels in subjects with many neurological disorders, including dementia. This research focuses on detecting diseases early by improving the performance of models for segmentation of retinal vessels with fewer parameters, which reduces computational costs and supports faster processing. This paper presents a novel lightweight encoder-decoder model that segments retinal vessels to improve the efficiency of disease detection. It incorporates multi-scale convolutional blocks in the encoder to accurately identify vessels of various sizes and thicknesses. The bottleneck of the model integrates the Focal Modulation Attention and Spatial Feature Refinement Blocks to refine and enhance essential features for efficient segmentation. The decoder upsamples features and integrates them with the corresponding feature in the encoder using skip connections and the spatial feature refinement block at every upsampling stage to enhance feature representation at various scales. The estimated computation complexity of our proposed model is around 29.60 GFLOP with 0.71 million parameters and 2.74 MB of memory size, and it is evaluated using public datasets, that is, DRIVE, CHASE\_DB, and STARE. It outperforms existing models with dice scores of 86.44\%, 84.22\%, and 87.88\%, respectively.
TESL-Net: A Transformer-Enhanced CNN for Accurate Skin Lesion Segmentation
Aug 19, 2024



Early detection of skin cancer relies on precise segmentation of dermoscopic images of skin lesions. However, this task is challenging due to the irregular shape of the lesion, the lack of sharp borders, and the presence of artefacts such as marker colours and hair follicles. Recent methods for melanoma segmentation are U-Nets and fully connected networks (FCNs). As the depth of these neural network models increases, they can face issues like the vanishing gradient problem and parameter redundancy, potentially leading to a decrease in the Jaccard index of the segmentation model. In this study, we introduced a novel network named TESL-Net for the segmentation of skin lesions. The proposed TESL-Net involves a hybrid network that combines the local features of a CNN encoder-decoder architecture with long-range and temporal dependencies using bi-convolutional long-short-term memory (Bi-ConvLSTM) networks and a Swin transformer. This enables the model to account for the uncertainty of segmentation over time and capture contextual channel relationships in the data. We evaluated the efficacy of TESL-Net in three commonly used datasets (ISIC 2016, ISIC 2017, and ISIC 2018) for the segmentation of skin lesions. The proposed TESL-Net achieves state-of-the-art performance, as evidenced by a significantly elevated Jaccard index demonstrated by empirical results.
Human Gait Recognition using Deep Learning: A Comprehensive Review
Sep 18, 2023
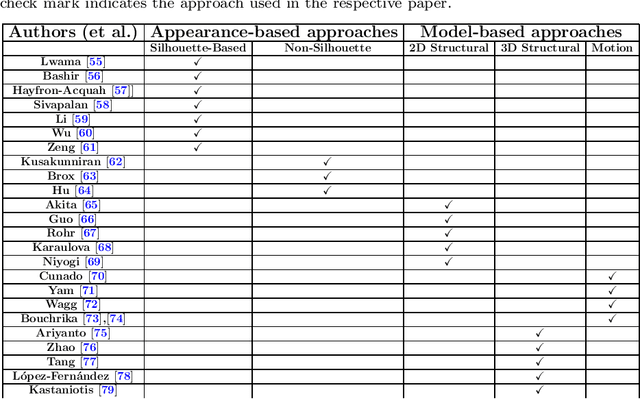
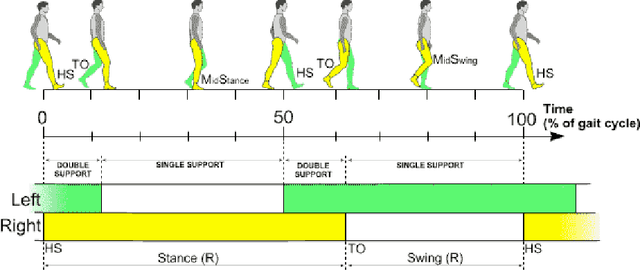
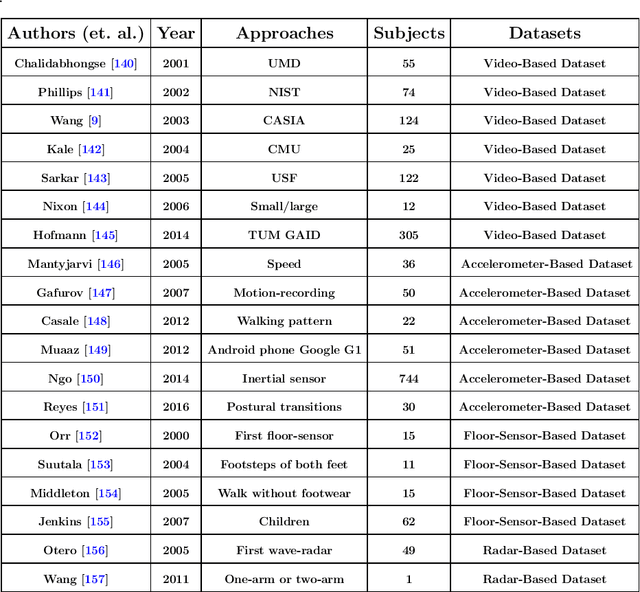
Gait recognition (GR) is a growing biometric modality used for person identification from a distance through visual cameras. GR provides a secure and reliable alternative to fingerprint and face recognition, as it is harder to distinguish between false and authentic signals. Furthermore, its resistance to spoofing makes GR suitable for all types of environments. With the rise of deep learning, steadily improving strides have been made in GR technology with promising results in various contexts. As video surveillance becomes more prevalent, new obstacles arise, such as ensuring uniform performance evaluation across different protocols, reliable recognition despite shifting lighting conditions, fluctuations in gait patterns, and protecting privacy.This survey aims to give an overview of GR and analyze the environmental elements and complications that could affect it in comparison to other biometric recognition systems. The primary goal is to examine the existing deep learning (DL) techniques employed for human GR that may generate new research opportunities.
EDDense-Net: Fully Dense Encoder Decoder Network for Joint Segmentation of Optic Cup and Disc
Aug 20, 2023



Glaucoma is an eye disease that causes damage to the optic nerve, which can lead to visual loss and permanent blindness. Early glaucoma detection is therefore critical in order to avoid permanent blindness. The estimation of the cup-to-disc ratio (CDR) during an examination of the optical disc (OD) is used for the diagnosis of glaucoma. In this paper, we present the EDDense-Net segmentation network for the joint segmentation of OC and OD. The encoder and decoder in this network are made up of dense blocks with a grouped convolutional layer in each block, allowing the network to acquire and convey spatial information from the image while simultaneously reducing the network's complexity. To reduce spatial information loss, the optimal number of filters in all convolution layers were utilised. In semantic segmentation, dice pixel classification is employed in the decoder to alleviate the problem of class imbalance. The proposed network was evaluated on two publicly available datasets where it outperformed existing state-of-the-art methods in terms of accuracy and efficiency. For the diagnosis and analysis of glaucoma, this method can be used as a second opinion system to assist medical ophthalmologists.