 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLVS-Net: A Lightweight Vessels Segmentation Network for Retinal Image Analysis
Dec 08, 2024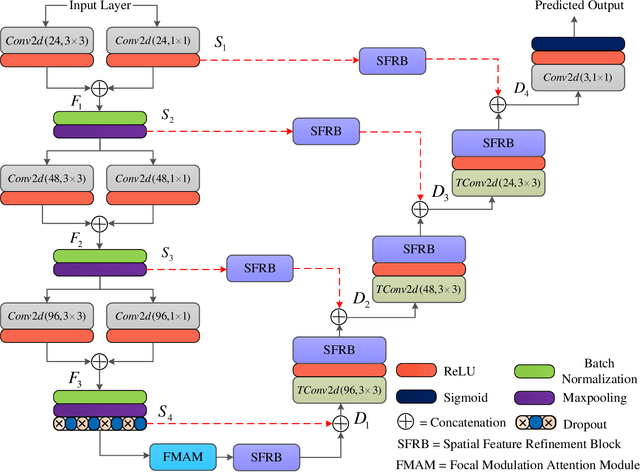
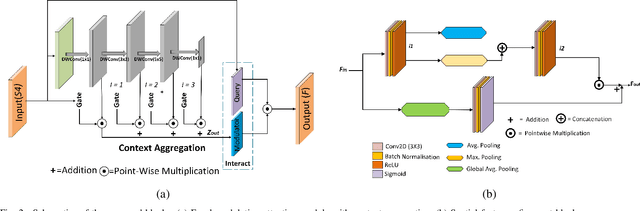
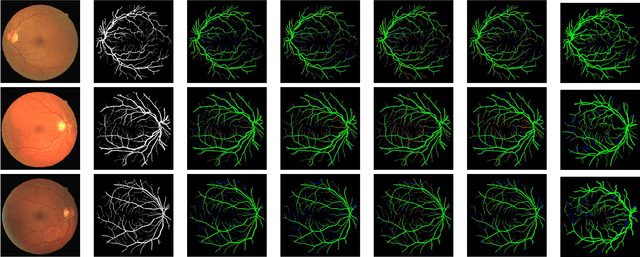

The analysis of retinal images for the diagnosis of various diseases is one of the emerging areas of research. Recently, the research direction has been inclined towards investigating several changes in retinal blood vessels in subjects with many neurological disorders, including dementia. This research focuses on detecting diseases early by improving the performance of models for segmentation of retinal vessels with fewer parameters, which reduces computational costs and supports faster processing. This paper presents a novel lightweight encoder-decoder model that segments retinal vessels to improve the efficiency of disease detection. It incorporates multi-scale convolutional blocks in the encoder to accurately identify vessels of various sizes and thicknesses. The bottleneck of the model integrates the Focal Modulation Attention and Spatial Feature Refinement Blocks to refine and enhance essential features for efficient segmentation. The decoder upsamples features and integrates them with the corresponding feature in the encoder using skip connections and the spatial feature refinement block at every upsampling stage to enhance feature representation at various scales. The estimated computation complexity of our proposed model is around 29.60 GFLOP with 0.71 million parameters and 2.74 MB of memory size, and it is evaluated using public datasets, that is, DRIVE, CHASE\_DB, and STARE. It outperforms existing models with dice scores of 86.44\%, 84.22\%, and 87.88\%, respectively.
Emotion Recognition on large video dataset based on Convolutional Feature Extractor and Recurrent Neural Network
Jun 19, 2020



For many years, the emotion recognition task has remained one of the most interesting and important problems in the field of human-computer interaction. In this study, we consider the emotion recognition task as a classification as well as a regression task by processing encoded emotions in different datasets using deep learning models. Our model combines convolutional neural network (CNN) with recurrent neural network (RNN) to predict dimensional emotions on video data. At the first step, CNN extracts feature vectors from video frames. In the second step, we fed these feature vectors to train RNN for exploiting the temporal dynamics of video. Furthermore, we analyzed how each neural network contributes to the system's overall performance. The experiments are performed on publicly available datasets including the largest modern Aff-Wild2 database. It contains over sixty hours of video data. We discovered the problem of overfitting of the model on an unbalanced dataset with an illustrative example using confusion matrices. The problem is solved by downsampling technique to balance the dataset. By significantly decreasing training data, we balance the dataset, thereby, the overall performance of the model is improved. Hence, the study qualitatively describes the abilities of deep learning models exploring enough amount of data to predict facial emotions. Our proposed method is implemented using Tensorflow Keras.