 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLVS-Net: A Lightweight Vessels Segmentation Network for Retinal Image Analysis
Dec 08, 2024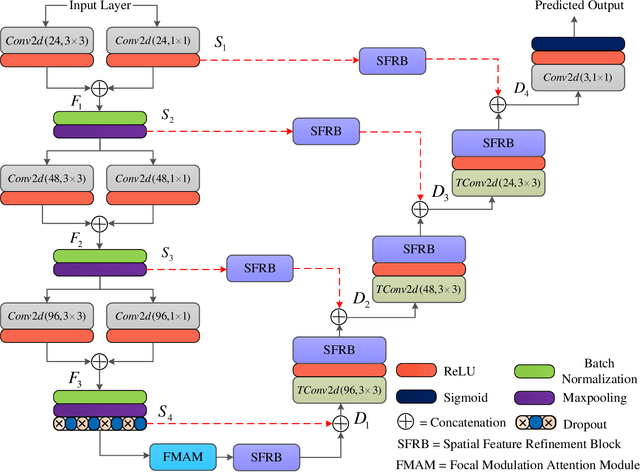
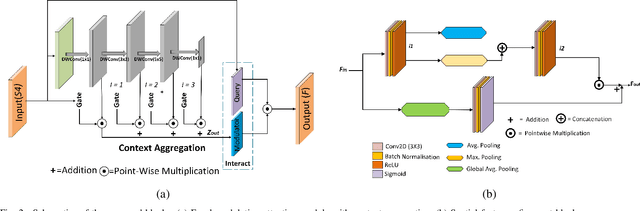
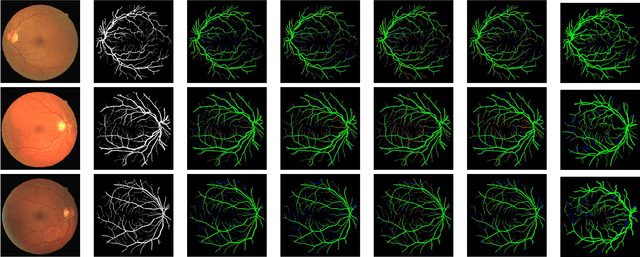

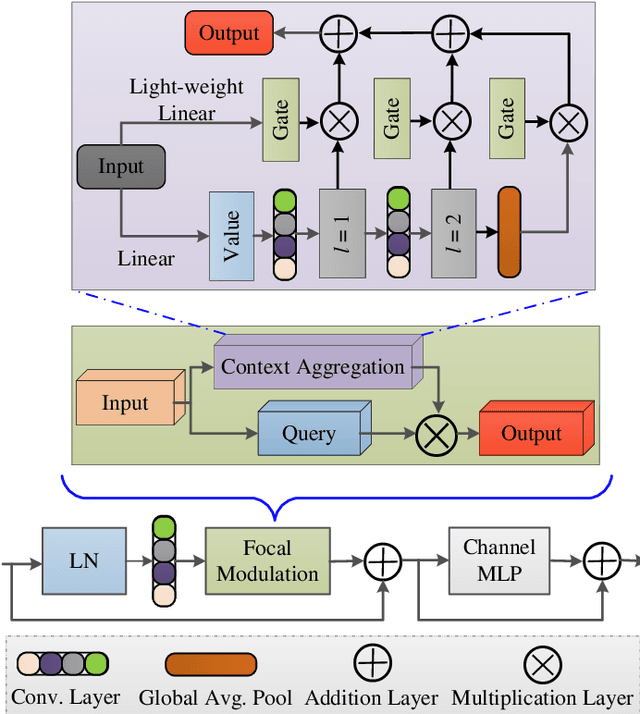
The analysis of retinal images for the diagnosis of various diseases is one of the emerging areas of research. Recently, the research direction has been inclined towards investigating several changes in retinal blood vessels in subjects with many neurological disorders, including dementia. This research focuses on detecting diseases early by improving the performance of models for segmentation of retinal vessels with fewer parameters, which reduces computational costs and supports faster processing. This paper presents a novel lightweight encoder-decoder model that segments retinal vessels to improve the efficiency of disease detection. It incorporates multi-scale convolutional blocks in the encoder to accurately identify vessels of various sizes and thicknesses. The bottleneck of the model integrates the Focal Modulation Attention and Spatial Feature Refinement Blocks to refine and enhance essential features for efficient segmentation. The decoder upsamples features and integrates them with the corresponding feature in the encoder using skip connections and the spatial feature refinement block at every upsampling stage to enhance feature representation at various scales. The estimated computation complexity of our proposed model is around 29.60 GFLOP with 0.71 million parameters and 2.74 MB of memory size, and it is evaluated using public datasets, that is, DRIVE, CHASE\_DB, and STARE. It outperforms existing models with dice scores of 86.44\%, 84.22\%, and 87.88\%, respectively.
TAFM-Net: A Novel Approach to Skin Lesion Segmentation Using Transformer Attention and Focal Modulation
Nov 26, 2024



Incorporating modern computer vision techniques into clinical protocols shows promise in improving skin lesion segmentation. The U-Net architecture has been a key model in this area, iteratively improved to address challenges arising from the heterogeneity of dermatologic images due to varying clinical settings, lighting, patient attributes, and hair density. To further improve skin lesion segmentation, we developed TAFM-Net, an innovative model leveraging self-adaptive transformer attention (TA) coupled with focal modulation (FM). Our model integrates an EfficientNetV2B1 encoder, which employs TA to enhance spatial and channel-related saliency, while a densely connected decoder integrates FM within skip connections, enhancing feature emphasis, segmentation performance, and interpretability crucial for medical image analysis. A novel dynamic loss function amalgamates region and boundary information, guiding effective model training. Our model achieves competitive performance, with Jaccard coefficients of 93.64\%, 86.88\% and 92.88\% in the ISIC2016, ISIC2017 and ISIC2018 datasets, respectively, demonstrating its potential in real-world scenarios.
Latent fingerprint enhancement for accurate minutiae detection
Sep 18, 2024Identification of suspects based on partial and smudged fingerprints, commonly referred to as fingermarks or latent fingerprints, presents a significant challenge in the field of fingerprint recognition. Although fixed-length embeddings have shown effectiveness in recognising rolled and slap fingerprints, the methods for matching latent fingerprints have primarily centred around local minutiae-based embeddings, failing to fully exploit global representations for matching purposes. Consequently, enhancing latent fingerprints becomes critical to ensuring robust identification for forensic investigations. Current approaches often prioritise restoring ridge patterns, overlooking the fine-macroeconomic details crucial for accurate fingerprint recognition. To address this, we propose a novel approach that uses generative adversary networks (GANs) to redefine Latent Fingerprint Enhancement (LFE) through a structured approach to fingerprint generation. By directly optimising the minutiae information during the generation process, the model produces enhanced latent fingerprints that exhibit exceptional fidelity to ground-truth instances. This leads to a significant improvement in identification performance. Our framework integrates minutiae locations and orientation fields, ensuring the preservation of both local and structural fingerprint features. Extensive evaluations conducted on two publicly available datasets demonstrate our method's dominance over existing state-of-the-art techniques, highlighting its potential to significantly enhance latent fingerprint recognition accuracy in forensic applications.
AD-Net: Attention-based dilated convolutional residual network with guided decoder for robust skin lesion segmentation
Sep 09, 2024In computer-aided diagnosis tools employed for skin cancer treatment and early diagnosis, skin lesion segmentation is important. However, achieving precise segmentation is challenging due to inherent variations in appearance, contrast, texture, and blurry lesion boundaries. This research presents a robust approach utilizing a dilated convolutional residual network, which incorporates an attention-based spatial feature enhancement block (ASFEB) and employs a guided decoder strategy. In each dilated convolutional residual block, dilated convolution is employed to broaden the receptive field with varying dilation rates. To improve the spatial feature information of the encoder, we employed an attention-based spatial feature enhancement block in the skip connections. The ASFEB in our proposed method combines feature maps obtained from average and maximum-pooling operations. These combined features are then weighted using the active outcome of global average pooling and convolution operations. Additionally, we have incorporated a guided decoder strategy, where each decoder block is optimized using an individual loss function to enhance the feature learning process in the proposed AD-Net. The proposed AD-Net presents a significant benefit by necessitating fewer model parameters compared to its peer methods. This reduction in parameters directly impacts the number of labeled data required for training, facilitating faster convergence during the training process. The effectiveness of the proposed AD-Net was evaluated using four public benchmark datasets. We conducted a Wilcoxon signed-rank test to verify the efficiency of the AD-Net. The outcomes suggest that our method surpasses other cutting-edge methods in performance, even without the implementation of data augmentation strategies.
TBConvL-Net: A Hybrid Deep Learning Architecture for Robust Medical Image Segmentation
Sep 05, 2024



Deep learning has shown great potential for automated medical image segmentation to improve the precision and speed of disease diagnostics. However, the task presents significant difficulties due to variations in the scale, shape, texture, and contrast of the pathologies. Traditional convolutional neural network (CNN) models have certain limitations when it comes to effectively modelling multiscale context information and facilitating information interaction between skip connections across levels. To overcome these limitations, a novel deep learning architecture is introduced for medical image segmentation, taking advantage of CNNs and vision transformers. Our proposed model, named TBConvL-Net, involves a hybrid network that combines the local features of a CNN encoder-decoder architecture with long-range and temporal dependencies using biconvolutional long-short-term memory (LSTM) networks and vision transformers (ViT). This enables the model to capture contextual channel relationships in the data and account for the uncertainty of segmentation over time. Additionally, we introduce a novel composite loss function that considers both the segmentation robustness and the boundary agreement of the predicted output with the gold standard. Our proposed model shows consistent improvement over the state of the art on ten publicly available datasets of seven different medical imaging modalities.
LSSF-Net: Lightweight Segmentation with Self-Awareness, Spatial Attention, and Focal Modulation
Sep 03, 2024

Accurate segmentation of skin lesions within dermoscopic images plays a crucial role in the timely identification of skin cancer for computer-aided diagnosis on mobile platforms. However, varying shapes of the lesions, lack of defined edges, and the presence of obstructions such as hair strands and marker colors make this challenge more complex. \textcolor{red}Additionally, skin lesions often exhibit subtle variations in texture and color that are difficult to differentiate from surrounding healthy skin, necessitating models that can capture both fine-grained details and broader contextual information. Currently, melanoma segmentation models are commonly based on fully connected networks and U-Nets. However, these models often struggle with capturing the complex and varied characteristics of skin lesions, such as the presence of indistinct boundaries and diverse lesion appearances, which can lead to suboptimal segmentation performance.To address these challenges, we propose a novel lightweight network specifically designed for skin lesion segmentation utilizing mobile devices, featuring a minimal number of learnable parameters (only 0.8 million). This network comprises an encoder-decoder architecture that incorporates conformer-based focal modulation attention, self-aware local and global spatial attention, and split channel-shuffle. The efficacy of our model has been evaluated on four well-established benchmark datasets for skin lesion segmentation: ISIC 2016, ISIC 2017, ISIC 2018, and PH2. Empirical findings substantiate its state-of-the-art performance, notably reflected in a high Jaccard index.
EUIS-Net: A Convolutional Neural Network for Efficient Ultrasound Image Segmentation
Aug 22, 2024



Segmenting ultrasound images is critical for various medical applications, but it offers significant challenges due to ultrasound images' inherent noise and unpredictability. To address these challenges, we proposed EUIS-Net, a CNN network designed to segment ultrasound images efficiently and precisely. The proposed EUIS-Net utilises four encoder-decoder blocks, resulting in a notable decrease in computational complexity while achieving excellent performance. The proposed EUIS-Net integrates both channel and spatial attention mechanisms into the bottleneck to improve feature representation and collect significant contextual information. In addition, EUIS-Net incorporates a region-aware attention module in skip connections, which enhances the ability to concentrate on the region of the injury. To enable thorough information exchange across various network blocks, skip connection aggregation is employed from the network's lowermost to the uppermost block. Comprehensive evaluations are conducted on two publicly available ultrasound image segmentation datasets. The proposed EUIS-Net achieved mean IoU and dice scores of 78. 12\%, 85. 42\% and 84. 73\%, 89. 01\% in the BUSI and DDTI datasets, respectively. The findings of our study showcase the substantial capabilities of EUIS-Net for immediate use in clinical settings and its versatility in various ultrasound imaging tasks.
TESL-Net: A Transformer-Enhanced CNN for Accurate Skin Lesion Segmentation
Aug 19, 2024



Early detection of skin cancer relies on precise segmentation of dermoscopic images of skin lesions. However, this task is challenging due to the irregular shape of the lesion, the lack of sharp borders, and the presence of artefacts such as marker colours and hair follicles. Recent methods for melanoma segmentation are U-Nets and fully connected networks (FCNs). As the depth of these neural network models increases, they can face issues like the vanishing gradient problem and parameter redundancy, potentially leading to a decrease in the Jaccard index of the segmentation model. In this study, we introduced a novel network named TESL-Net for the segmentation of skin lesions. The proposed TESL-Net involves a hybrid network that combines the local features of a CNN encoder-decoder architecture with long-range and temporal dependencies using bi-convolutional long-short-term memory (Bi-ConvLSTM) networks and a Swin transformer. This enables the model to account for the uncertainty of segmentation over time and capture contextual channel relationships in the data. We evaluated the efficacy of TESL-Net in three commonly used datasets (ISIC 2016, ISIC 2017, and ISIC 2018) for the segmentation of skin lesions. The proposed TESL-Net achieves state-of-the-art performance, as evidenced by a significantly elevated Jaccard index demonstrated by empirical results.
A Robust Algorithm for Contactless Fingerprint Enhancement and Matching
Aug 18, 2024



Compared to contact fingerprint images, contactless fingerprint images exhibit four distinct characteristics: (1) they contain less noise; (2) they have fewer discontinuities in ridge patterns; (3) the ridge-valley pattern is less distinct; and (4) they pose an interoperability problem, as they lack the elastic deformation caused by pressing the finger against the capture device. These properties present significant challenges for the enhancement of contactless fingerprint images. In this study, we propose a novel contactless fingerprint identification solution that enhances the accuracy of minutiae detection through improved frequency estimation and a new region-quality-based minutia extraction algorithm. In addition, we introduce an efficient and highly accurate minutiae-based encoding and matching algorithm. We validate the effectiveness of our approach through extensive experimental testing. Our method achieves a minimum Equal Error Rate (EER) of 2.84\% on the PolyU contactless fingerprint dataset, demonstrating its superior performance compared to existing state-of-the-art techniques. The proposed fingerprint identification method exhibits notable precision and resilience, proving to be an effective and feasible solution for contactless fingerprint-based identification systems.
LMBF-Net: A Lightweight Multipath Bidirectional Focal Attention Network for Multifeatures Segmentation
Jul 03, 2024
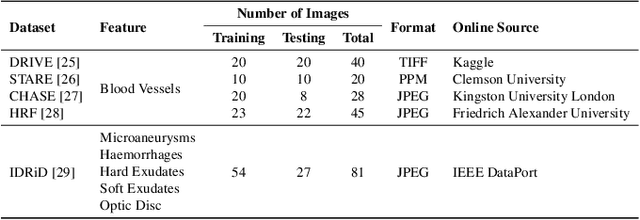
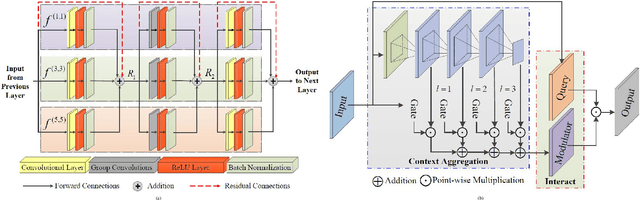
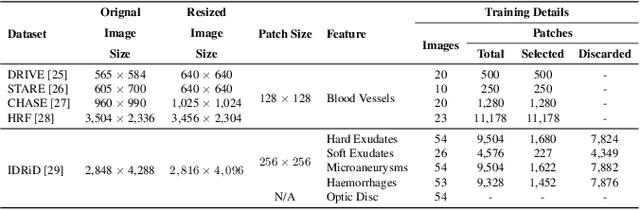
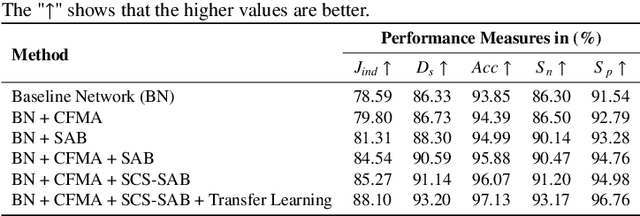
Retinal diseases can cause irreversible vision loss in both eyes if not diagnosed and treated early. Since retinal diseases are so complicated, retinal imaging is likely to show two or more abnormalities. Current deep learning techniques for segmenting retinal images with many labels and attributes have poor detection accuracy and generalisability. This paper presents a multipath convolutional neural network for multifeature segmentation. The proposed network is lightweight and spatially sensitive to information. A patch-based implementation is used to extract local image features, and focal modulation attention blocks are incorporated between the encoder and the decoder for improved segmentation. Filter optimisation is used to prevent filter overlaps and speed up model convergence. A combination of convolution operations and group convolution operations is used to reduce computational costs. This is the first robust and generalisable network capable of segmenting multiple features of fundus images (including retinal vessels, microaneurysms, optic discs, haemorrhages, hard exudates, and soft exudates). The results of our experimental evaluation on more than ten publicly available datasets with multiple features show that the proposed network outperforms recent networks despite having a small number of learnable parameters.