 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of AI in Early Detection of Life-Threatening Diseases: A Retinal Imaging Perspective
May 27, 2025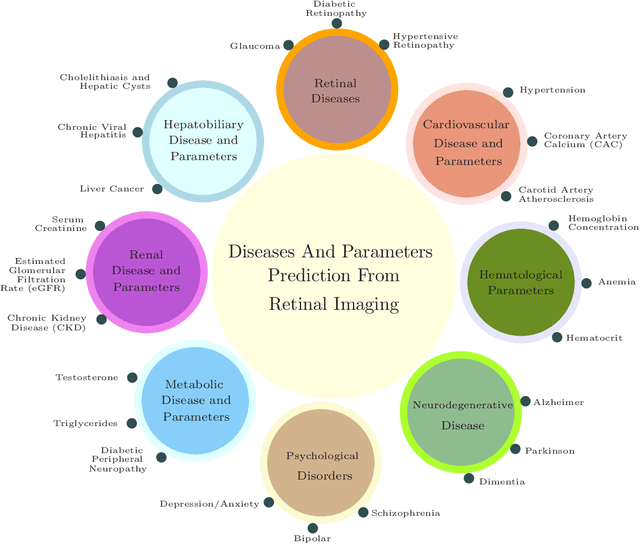
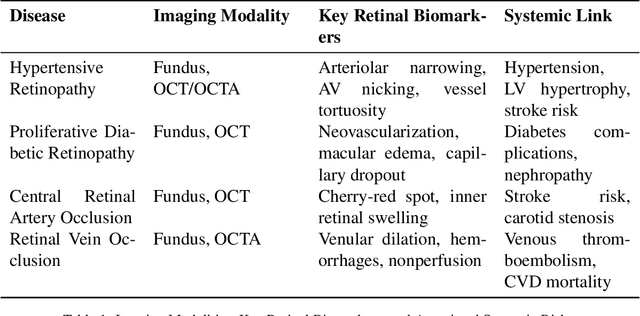
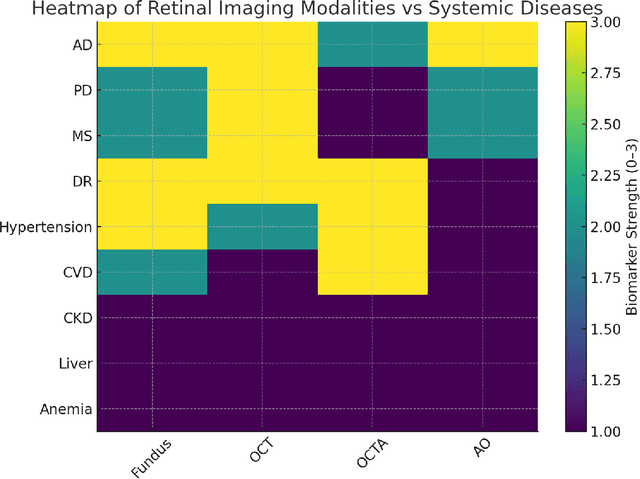
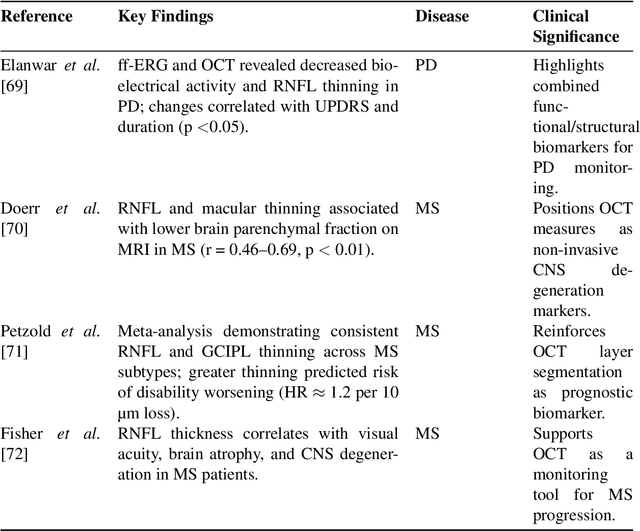
Retinal imaging has emerged as a powerful, non-invasive modality for detecting and quantifying biomarkers of systemic diseases-ranging from diabetes and hypertension to Alzheimer's disease and cardiovascular disorders but current insights remain dispersed across platforms and specialties. Recent technological advances in optical coherence tomography (OCT/OCTA) and adaptive optics (AO) now deliver ultra-high-resolution scans (down to 5 {\mu}m ) with superior contrast and spatial integration, allowing early identification of microvascular abnormalities and neurodegenerative changes. At the same time, AI-driven and machine learning (ML) algorithms have revolutionized the analysis of large-scale retinal datasets, increasing sensitivity and specificity; for example, deep learning models achieve > 90 \% sensitivity for diabetic retinopathy and AUC = 0.89 for the prediction of cardiovascular risk from fundus photographs. The proliferation of mobile health technologies and telemedicine platforms further extends access, reduces costs, and facilitates community-based screening and longitudinal monitoring. Despite these breakthroughs, translation into routine practice is hindered by heterogeneous imaging protocols, limited external validation of AI models, and integration challenges within clinical workflows. In this review, we systematically synthesize the latest OCT/OCT and AO developments, AI/ML approaches, and mHealth/Tele-ophthalmology initiatives and quantify their diagnostic performance across disease domains. Finally, we propose a roadmap for multicenter protocol standardization, prospective validation trials, and seamless incorporation of retinal screening into primary and specialty care pathways-paving the way for precision prevention, early intervention, and ongoing treatment of life-threatening systemic diseases.
TAFM-Net: A Novel Approach to Skin Lesion Segmentation Using Transformer Attention and Focal Modulation
Nov 26, 2024



Incorporating modern computer vision techniques into clinical protocols shows promise in improving skin lesion segmentation. The U-Net architecture has been a key model in this area, iteratively improved to address challenges arising from the heterogeneity of dermatologic images due to varying clinical settings, lighting, patient attributes, and hair density. To further improve skin lesion segmentation, we developed TAFM-Net, an innovative model leveraging self-adaptive transformer attention (TA) coupled with focal modulation (FM). Our model integrates an EfficientNetV2B1 encoder, which employs TA to enhance spatial and channel-related saliency, while a densely connected decoder integrates FM within skip connections, enhancing feature emphasis, segmentation performance, and interpretability crucial for medical image analysis. A novel dynamic loss function amalgamates region and boundary information, guiding effective model training. Our model achieves competitive performance, with Jaccard coefficients of 93.64\%, 86.88\% and 92.88\% in the ISIC2016, ISIC2017 and ISIC2018 datasets, respectively, demonstrating its potential in real-world scenarios.
LSSF-Net: Lightweight Segmentation with Self-Awareness, Spatial Attention, and Focal Modulation
Sep 03, 2024

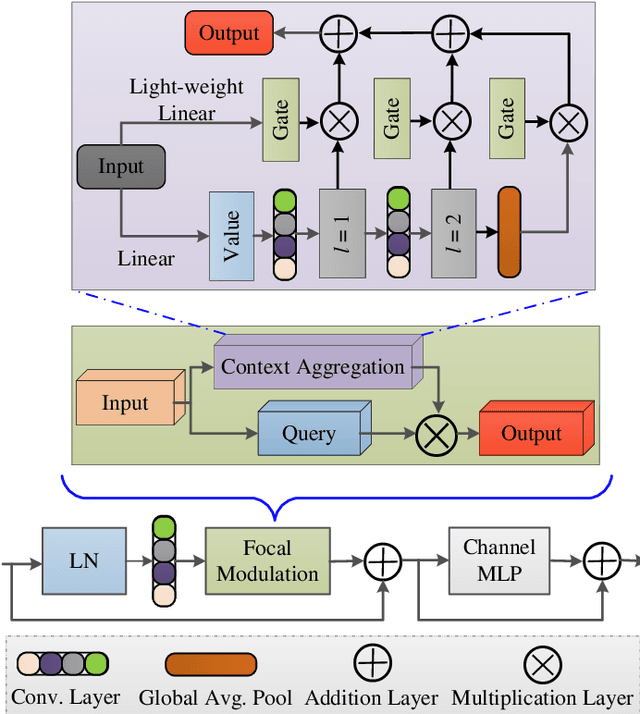
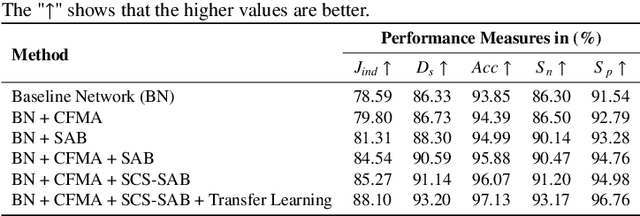
Accurate segmentation of skin lesions within dermoscopic images plays a crucial role in the timely identification of skin cancer for computer-aided diagnosis on mobile platforms. However, varying shapes of the lesions, lack of defined edges, and the presence of obstructions such as hair strands and marker colors make this challenge more complex. \textcolor{red}Additionally, skin lesions often exhibit subtle variations in texture and color that are difficult to differentiate from surrounding healthy skin, necessitating models that can capture both fine-grained details and broader contextual information. Currently, melanoma segmentation models are commonly based on fully connected networks and U-Nets. However, these models often struggle with capturing the complex and varied characteristics of skin lesions, such as the presence of indistinct boundaries and diverse lesion appearances, which can lead to suboptimal segmentation performance.To address these challenges, we propose a novel lightweight network specifically designed for skin lesion segmentation utilizing mobile devices, featuring a minimal number of learnable parameters (only 0.8 million). This network comprises an encoder-decoder architecture that incorporates conformer-based focal modulation attention, self-aware local and global spatial attention, and split channel-shuffle. The efficacy of our model has been evaluated on four well-established benchmark datasets for skin lesion segmentation: ISIC 2016, ISIC 2017, ISIC 2018, and PH2. Empirical findings substantiate its state-of-the-art performance, notably reflected in a high Jaccard index.
LMBF-Net: A Lightweight Multipath Bidirectional Focal Attention Network for Multifeatures Segmentation
Jul 03, 2024
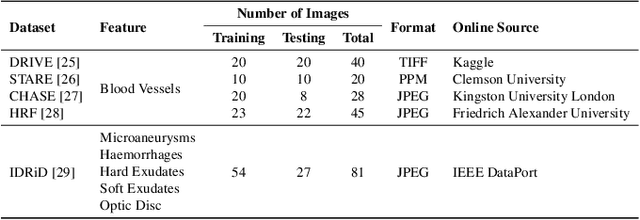
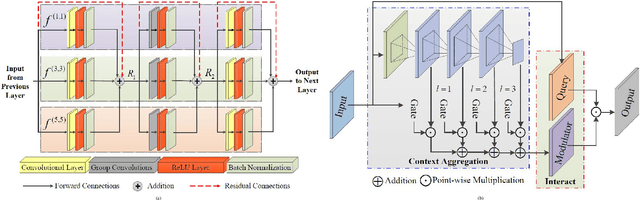
Retinal diseases can cause irreversible vision loss in both eyes if not diagnosed and treated early. Since retinal diseases are so complicated, retinal imaging is likely to show two or more abnormalities. Current deep learning techniques for segmenting retinal images with many labels and attributes have poor detection accuracy and generalisability. This paper presents a multipath convolutional neural network for multifeature segmentation. The proposed network is lightweight and spatially sensitive to information. A patch-based implementation is used to extract local image features, and focal modulation attention blocks are incorporated between the encoder and the decoder for improved segmentation. Filter optimisation is used to prevent filter overlaps and speed up model convergence. A combination of convolution operations and group convolution operations is used to reduce computational costs. This is the first robust and generalisable network capable of segmenting multiple features of fundus images (including retinal vessels, microaneurysms, optic discs, haemorrhages, hard exudates, and soft exudates). The results of our experimental evaluation on more than ten publicly available datasets with multiple features show that the proposed network outperforms recent networks despite having a small number of learnable parameters.
ESDMR-Net: A Lightweight Network With Expand-Squeeze and Dual Multiscale Residual Connections for Medical Image Segmentation
Dec 17, 2023

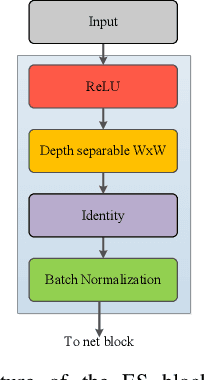

Segmentation is an important task in a wide range of computer vision applications, including medical image analysis. Recent years have seen an increase in the complexity of medical image segmentation approaches based on sophisticated convolutional neural network architectures. This progress has led to incremental enhancements in performance on widely recognised benchmark datasets. However, most of the existing approaches are computationally demanding, which limits their practical applicability. This paper presents an expand-squeeze dual multiscale residual network (ESDMR-Net), which is a fully convolutional network that is particularly well-suited for resource-constrained computing hardware such as mobile devices. ESDMR-Net focuses on extracting multiscale features, enabling the learning of contextual dependencies among semantically distinct features. The ESDMR-Net architecture allows dual-stream information flow within encoder-decoder pairs. The expansion operation (depthwise separable convolution) makes all of the rich features with multiscale information available to the squeeze operation (bottleneck layer), which then extracts the necessary information for the segmentation task. The Expand-Squeeze (ES) block helps the network pay more attention to under-represented classes, which contributes to improved segmentation accuracy. To enhance the flow of information across multiple resolutions or scales, we integrated dual multiscale residual (DMR) blocks into the skip connection. This integration enables the decoder to access features from various levels of abstraction, ultimately resulting in more comprehensive feature representations. We present experiments on seven datasets from five distinct examples of applications. Our model achieved the best results despite having significantly fewer trainable parameters, with a reduction of two or even three orders of magnitude.
Hardware Implementation of Multimodal Biometric using Fingerprint and Iris
Jan 16, 2022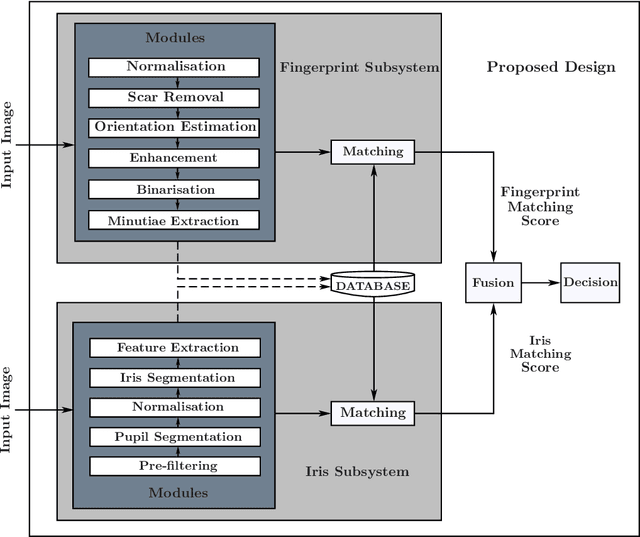

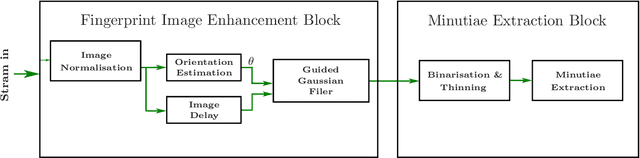
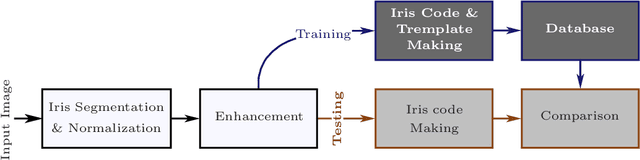
In this paper, a hardware architecture of a multimodal biometric system is presented that massively exploits the inherent parallelism. The proposed system is based on multiple biometric fusion that uses two biometric traits, fingerprint and iris. Each biometric trait is first optimised at the software level, by addressing some of the issues that directly affect the FAR and FRR. Then the hardware architectures for both biometric traits are presented, followed by a final multimodal hardware architecture. To the best of the author's knowledge, no other FPGA-based design exits that used these two traits.
RC-Net: A Convolutional Neural Network for Retinal Vessel Segmentation
Dec 21, 2021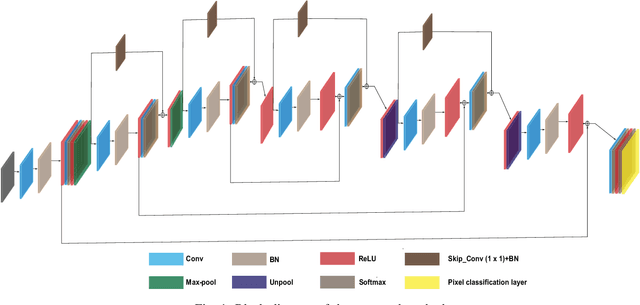

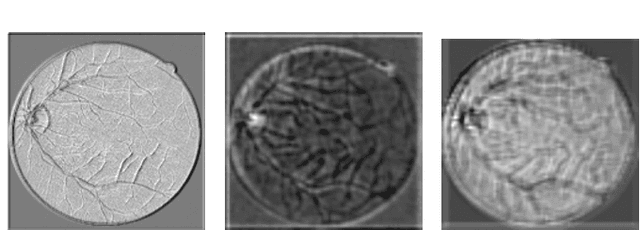

Over recent years, increasingly complex approaches based on sophisticated convolutional neural network architectures have been slowly pushing performance on well-established benchmark datasets. In this paper, we take a step back to examine the real need for such complexity. We present RC-Net, a fully convolutional network, where the number of filters per layer is optimized to reduce feature overlapping and complexity. We also used skip connections to keep spatial information loss to a minimum by keeping the number of pooling operations in the network to a minimum. Two publicly available retinal vessel segmentation datasets were used in our experiments. In our experiments, RC-Net is quite competitive, outperforming alternatives vessels segmentation methods with two or even three orders of magnitude less trainable parameters.