 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAD-Net: Attention-based dilated convolutional residual network with guided decoder for robust skin lesion segmentation
Sep 09, 2024In computer-aided diagnosis tools employed for skin cancer treatment and early diagnosis, skin lesion segmentation is important. However, achieving precise segmentation is challenging due to inherent variations in appearance, contrast, texture, and blurry lesion boundaries. This research presents a robust approach utilizing a dilated convolutional residual network, which incorporates an attention-based spatial feature enhancement block (ASFEB) and employs a guided decoder strategy. In each dilated convolutional residual block, dilated convolution is employed to broaden the receptive field with varying dilation rates. To improve the spatial feature information of the encoder, we employed an attention-based spatial feature enhancement block in the skip connections. The ASFEB in our proposed method combines feature maps obtained from average and maximum-pooling operations. These combined features are then weighted using the active outcome of global average pooling and convolution operations. Additionally, we have incorporated a guided decoder strategy, where each decoder block is optimized using an individual loss function to enhance the feature learning process in the proposed AD-Net. The proposed AD-Net presents a significant benefit by necessitating fewer model parameters compared to its peer methods. This reduction in parameters directly impacts the number of labeled data required for training, facilitating faster convergence during the training process. The effectiveness of the proposed AD-Net was evaluated using four public benchmark datasets. We conducted a Wilcoxon signed-rank test to verify the efficiency of the AD-Net. The outcomes suggest that our method surpasses other cutting-edge methods in performance, even without the implementation of data augmentation strategies.
TBConvL-Net: A Hybrid Deep Learning Architecture for Robust Medical Image Segmentation
Sep 05, 2024



Deep learning has shown great potential for automated medical image segmentation to improve the precision and speed of disease diagnostics. However, the task presents significant difficulties due to variations in the scale, shape, texture, and contrast of the pathologies. Traditional convolutional neural network (CNN) models have certain limitations when it comes to effectively modelling multiscale context information and facilitating information interaction between skip connections across levels. To overcome these limitations, a novel deep learning architecture is introduced for medical image segmentation, taking advantage of CNNs and vision transformers. Our proposed model, named TBConvL-Net, involves a hybrid network that combines the local features of a CNN encoder-decoder architecture with long-range and temporal dependencies using biconvolutional long-short-term memory (LSTM) networks and vision transformers (ViT). This enables the model to capture contextual channel relationships in the data and account for the uncertainty of segmentation over time. Additionally, we introduce a novel composite loss function that considers both the segmentation robustness and the boundary agreement of the predicted output with the gold standard. Our proposed model shows consistent improvement over the state of the art on ten publicly available datasets of seven different medical imaging modalities.
LMBF-Net: A Lightweight Multipath Bidirectional Focal Attention Network for Multifeatures Segmentation
Jul 03, 2024
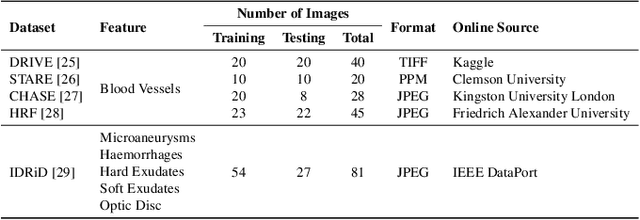
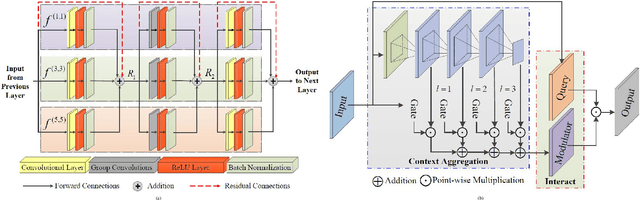
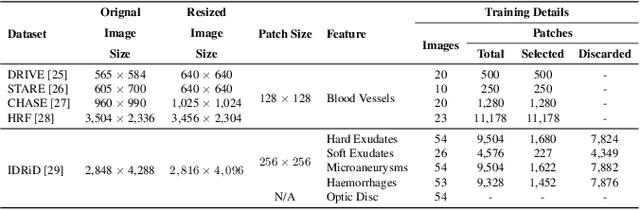
Retinal diseases can cause irreversible vision loss in both eyes if not diagnosed and treated early. Since retinal diseases are so complicated, retinal imaging is likely to show two or more abnormalities. Current deep learning techniques for segmenting retinal images with many labels and attributes have poor detection accuracy and generalisability. This paper presents a multipath convolutional neural network for multifeature segmentation. The proposed network is lightweight and spatially sensitive to information. A patch-based implementation is used to extract local image features, and focal modulation attention blocks are incorporated between the encoder and the decoder for improved segmentation. Filter optimisation is used to prevent filter overlaps and speed up model convergence. A combination of convolution operations and group convolution operations is used to reduce computational costs. This is the first robust and generalisable network capable of segmenting multiple features of fundus images (including retinal vessels, microaneurysms, optic discs, haemorrhages, hard exudates, and soft exudates). The results of our experimental evaluation on more than ten publicly available datasets with multiple features show that the proposed network outperforms recent networks despite having a small number of learnable parameters.
ESDMR-Net: A Lightweight Network With Expand-Squeeze and Dual Multiscale Residual Connections for Medical Image Segmentation
Dec 17, 2023

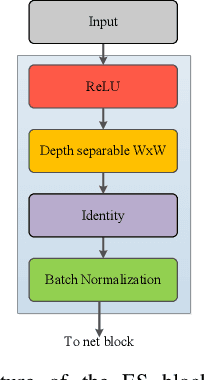

Segmentation is an important task in a wide range of computer vision applications, including medical image analysis. Recent years have seen an increase in the complexity of medical image segmentation approaches based on sophisticated convolutional neural network architectures. This progress has led to incremental enhancements in performance on widely recognised benchmark datasets. However, most of the existing approaches are computationally demanding, which limits their practical applicability. This paper presents an expand-squeeze dual multiscale residual network (ESDMR-Net), which is a fully convolutional network that is particularly well-suited for resource-constrained computing hardware such as mobile devices. ESDMR-Net focuses on extracting multiscale features, enabling the learning of contextual dependencies among semantically distinct features. The ESDMR-Net architecture allows dual-stream information flow within encoder-decoder pairs. The expansion operation (depthwise separable convolution) makes all of the rich features with multiscale information available to the squeeze operation (bottleneck layer), which then extracts the necessary information for the segmentation task. The Expand-Squeeze (ES) block helps the network pay more attention to under-represented classes, which contributes to improved segmentation accuracy. To enhance the flow of information across multiple resolutions or scales, we integrated dual multiscale residual (DMR) blocks into the skip connection. This integration enables the decoder to access features from various levels of abstraction, ultimately resulting in more comprehensive feature representations. We present experiments on seven datasets from five distinct examples of applications. Our model achieved the best results despite having significantly fewer trainable parameters, with a reduction of two or even three orders of magnitude.
LMBiS-Net: A Lightweight Multipath Bidirectional Skip Connection based CNN for Retinal Blood Vessel Segmentation
Sep 10, 2023Blinding eye diseases are often correlated with altered retinal morphology, which can be clinically identified by segmenting retinal structures in fundus images. However, current methodologies often fall short in accurately segmenting delicate vessels. Although deep learning has shown promise in medical image segmentation, its reliance on repeated convolution and pooling operations can hinder the representation of edge information, ultimately limiting overall segmentation accuracy. In this paper, we propose a lightweight pixel-level CNN named LMBiS-Net for the segmentation of retinal vessels with an exceptionally low number of learnable parameters \textbf{(only 0.172 M)}. The network used multipath feature extraction blocks and incorporates bidirectional skip connections for the information flow between the encoder and decoder. Additionally, we have optimized the efficiency of the model by carefully selecting the number of filters to avoid filter overlap. This optimization significantly reduces training time and enhances computational efficiency. To assess the robustness and generalizability of LMBiS-Net, we performed comprehensive evaluations on various aspects of retinal images. Specifically, the model was subjected to rigorous tests to accurately segment retinal vessels, which play a vital role in ophthalmological diagnosis and treatment. By focusing on the retinal blood vessels, we were able to thoroughly analyze the performance and effectiveness of the LMBiS-Net model. The results of our tests demonstrate that LMBiS-Net is not only robust and generalizable but also capable of maintaining high levels of segmentation accuracy. These characteristics highlight the potential of LMBiS-Net as an efficient tool for high-speed and accurate segmentation of retinal images in various clinical applications.
EDDense-Net: Fully Dense Encoder Decoder Network for Joint Segmentation of Optic Cup and Disc
Aug 20, 2023



Glaucoma is an eye disease that causes damage to the optic nerve, which can lead to visual loss and permanent blindness. Early glaucoma detection is therefore critical in order to avoid permanent blindness. The estimation of the cup-to-disc ratio (CDR) during an examination of the optical disc (OD) is used for the diagnosis of glaucoma. In this paper, we present the EDDense-Net segmentation network for the joint segmentation of OC and OD. The encoder and decoder in this network are made up of dense blocks with a grouped convolutional layer in each block, allowing the network to acquire and convey spatial information from the image while simultaneously reducing the network's complexity. To reduce spatial information loss, the optimal number of filters in all convolution layers were utilised. In semantic segmentation, dice pixel classification is employed in the decoder to alleviate the problem of class imbalance. The proposed network was evaluated on two publicly available datasets where it outperformed existing state-of-the-art methods in terms of accuracy and efficiency. For the diagnosis and analysis of glaucoma, this method can be used as a second opinion system to assist medical ophthalmologists.
Progressive Class-Wise Attention (PCA) Approach for Diagnosing Skin Lesions
Jun 11, 2023
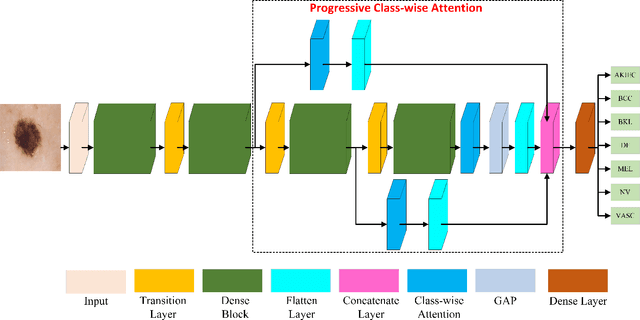


Skin cancer holds the highest incidence rate among all cancers globally. The importance of early detection cannot be overstated, as late-stage cases can be lethal. Classifying skin lesions, however, presents several challenges due to the many variations they can exhibit, such as differences in colour, shape, and size, significant variation within the same class, and notable similarities between different classes. This paper introduces a novel class-wise attention technique that equally regards each class while unearthing more specific details about skin lesions. This attention mechanism is progressively used to amalgamate discriminative feature details from multiple scales. The introduced technique demonstrated impressive performance, surpassing more than 15 cutting-edge methods including the winners of HAM1000 and ISIC 2019 leaderboards. It achieved an impressive accuracy rate of 97.40% on the HAM10000 dataset and 94.9% on the ISIC 2019 dataset.
LDMRes-Net: Enabling Real-Time Disease Monitoring through Efficient Image Segmentation
Jun 09, 2023



Retinal eye diseases can lead to irreversible vision loss in both eyes if not diagnosed and treated earlier. Owing to the complexities of retinal diseases, the likelihood that retinal images would contain two or more abnormalities is very high. The current deep learning algorithms used for segmenting retinal images with multiple labels and features suffer from inadequate detection accuracy and a lack of generalizability. In this paper, we propose a lightweight and efficient network, featuring dual multi-residual connections to enhance segmentation performance while minimizing computational cost. The proposed network is evaluated on eight publicly available retinal image datasets and achieved promising segmentation results, which demonstrate the effectiveness of the proposed network for retinal image analysis tasks. The proposed network's lightweight and efficient design makes it a promising candidate for real-time retinal image analysis applications.
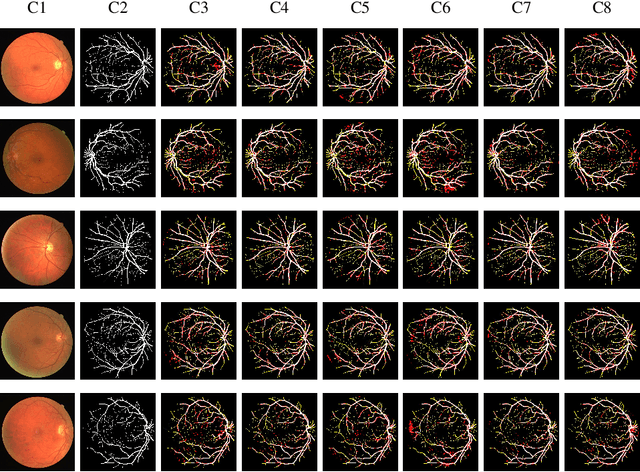
Retinal Vessel Segmentation via a Multi-resolution Contextual Network and Adversarial Learning
Apr 25, 2023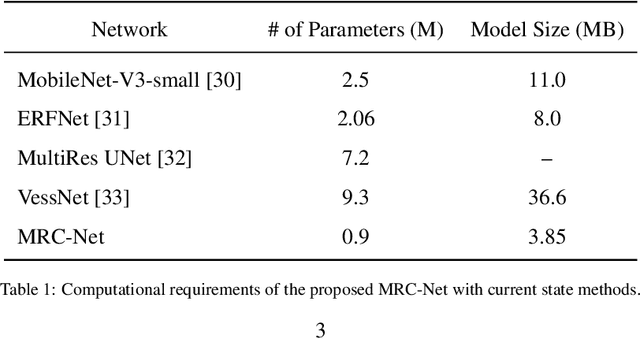
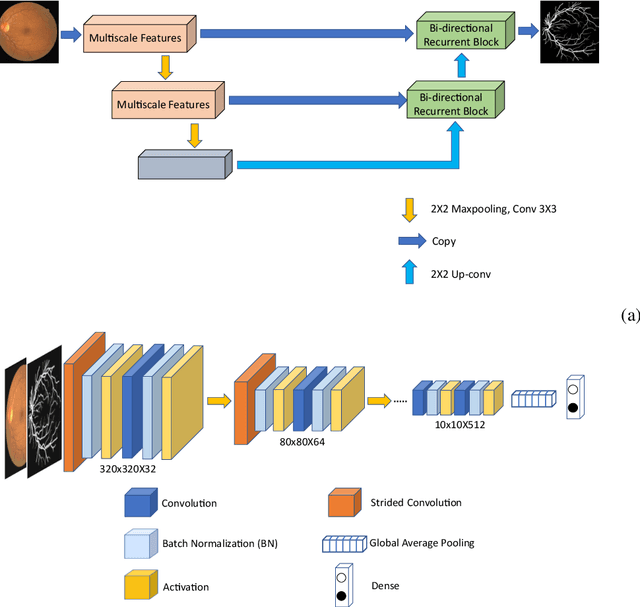
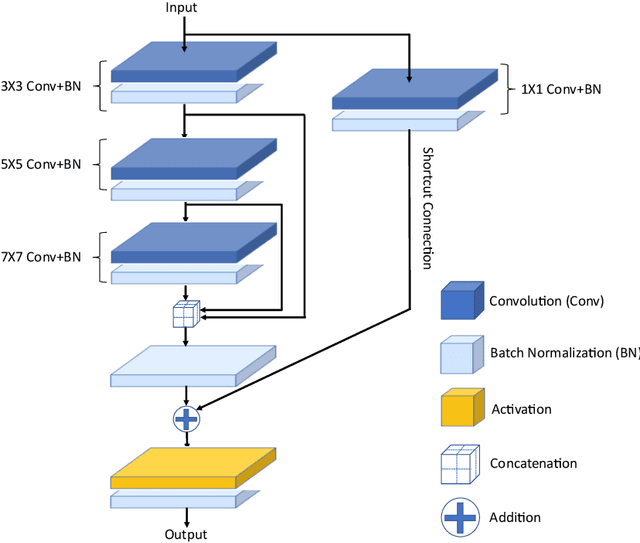
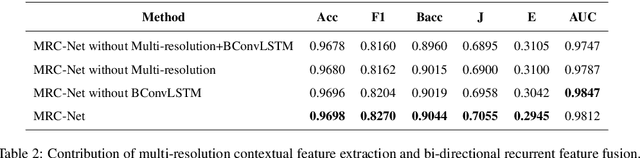
Timely and affordable computer-aided diagnosis of retinal diseases is pivotal in precluding blindness. Accurate retinal vessel segmentation plays an important role in disease progression and diagnosis of such vision-threatening diseases. To this end, we propose a Multi-resolution Contextual Network (MRC-Net) that addresses these issues by extracting multi-scale features to learn contextual dependencies between semantically different features and using bi-directional recurrent learning to model former-latter and latter-former dependencies. Another key idea is training in adversarial settings for foreground segmentation improvement through optimization of the region-based scores. This novel strategy boosts the performance of the segmentation network in terms of the Dice score (and correspondingly Jaccard index) while keeping the number of trainable parameters comparatively low. We have evaluated our method on three benchmark datasets, including DRIVE, STARE, and CHASE, demonstrating its superior performance as compared with competitive approaches elsewhere in the literature.
Neural Network Compression by Joint Sparsity Promotion and Redundancy Reduction
Oct 14, 2022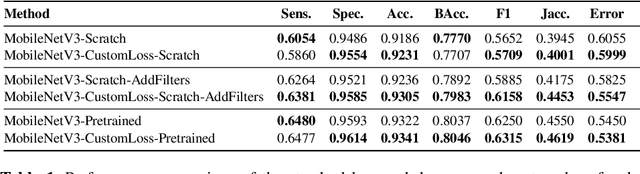
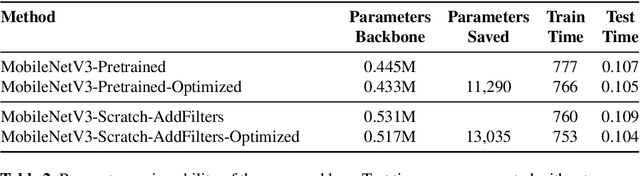

Compression of convolutional neural network models has recently been dominated by pruning approaches. A class of previous works focuses solely on pruning the unimportant filters to achieve network compression. Another important direction is the design of sparsity-inducing constraints which has also been explored in isolation. This paper presents a novel training scheme based on composite constraints that prune redundant filters and minimize their effect on overall network learning via sparsity promotion. Also, as opposed to prior works that employ pseudo-norm-based sparsity-inducing constraints, we propose a sparse scheme based on gradient counting in our framework. Our tests on several pixel-wise segmentation benchmarks show that the number of neurons and the memory footprint of networks in the test phase are significantly reduced without affecting performance. MobileNetV3 and UNet, two well-known architectures, are used to test the proposed scheme. Our network compression method not only results in reduced parameters but also achieves improved performance compared to MobileNetv3, which is an already optimized architecture.