 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMosaic: Composite Projection Pruning for Resource-efficient LLMs
Apr 08, 2025Extensive compute and memory requirements limit the deployment of large language models (LLMs) on any hardware. Compression methods, such as pruning, can reduce model size, which in turn reduces resource requirements. State-of-the-art pruning is based on coarse-grained methods. They are time-consuming and inherently remove critical model parameters, adversely impacting the quality of the pruned model. This paper introduces projection pruning, a novel fine-grained method for pruning LLMs. In addition, LLM projection pruning is enhanced by a new approach we refer to as composite projection pruning - the synergistic combination of unstructured pruning that retains accuracy and structured pruning that reduces model size. We develop Mosaic, a novel system to create and deploy pruned LLMs using composite projection pruning. Mosaic is evaluated using a range of performance and quality metrics on multiple hardware platforms, LLMs, and datasets. Mosaic is 7.19x faster in producing models than existing approaches. Mosaic models achieve up to 84.2% lower perplexity and 31.4% higher accuracy than models obtained from coarse-grained pruning. Up to 67% faster inference and 68% lower GPU memory use is noted for Mosaic models.
Rapid Deployment of DNNs for Edge Computing via Structured Pruning at Initialization
Apr 22, 2024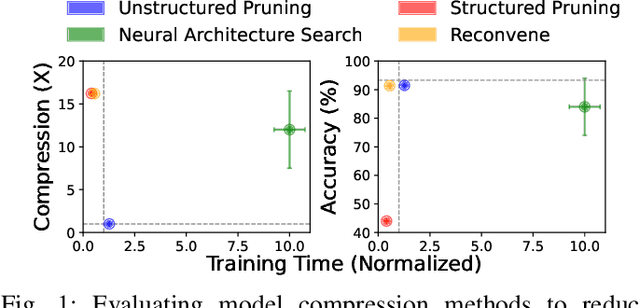
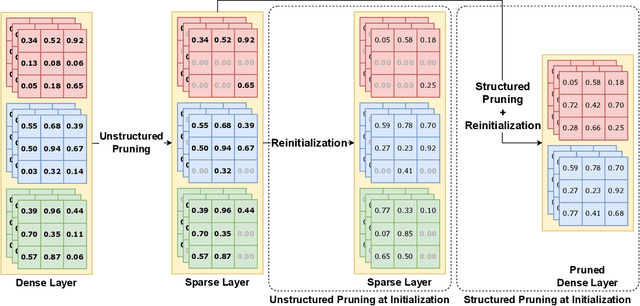
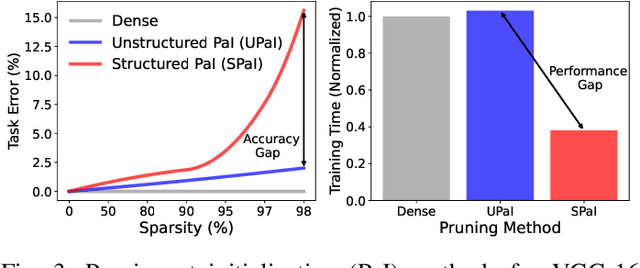
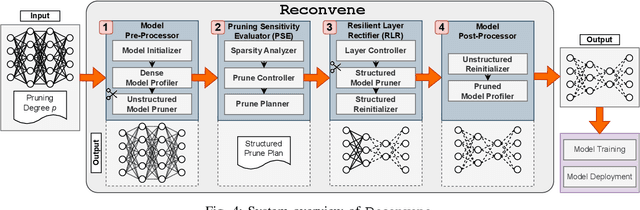
Edge machine learning (ML) enables localized processing of data on devices and is underpinned by deep neural networks (DNNs). However, DNNs cannot be easily run on devices due to their substantial computing, memory and energy requirements for delivering performance that is comparable to cloud-based ML. Therefore, model compression techniques, such as pruning, have been considered. Existing pruning methods are problematic for edge ML since they: (1) Create compressed models that have limited runtime performance benefits (using unstructured pruning) or compromise the final model accuracy (using structured pruning), and (2) Require substantial compute resources and time for identifying a suitable compressed DNN model (using neural architecture search). In this paper, we explore a new avenue, referred to as Pruning-at-Initialization (PaI), using structured pruning to mitigate the above problems. We develop Reconvene, a system for rapidly generating pruned models suited for edge deployments using structured PaI. Reconvene systematically identifies and prunes DNN convolution layers that are least sensitive to structured pruning. Reconvene rapidly creates pruned DNNs within seconds that are up to 16.21x smaller and 2x faster while maintaining the same accuracy as an unstructured PaI counterpart.
DNNShifter: An Efficient DNN Pruning System for Edge Computing
Sep 13, 2023Deep neural networks (DNNs) underpin many machine learning applications. Production quality DNN models achieve high inference accuracy by training millions of DNN parameters which has a significant resource footprint. This presents a challenge for resources operating at the extreme edge of the network, such as mobile and embedded devices that have limited computational and memory resources. To address this, models are pruned to create lightweight, more suitable variants for these devices. Existing pruning methods are unable to provide similar quality models compared to their unpruned counterparts without significant time costs and overheads or are limited to offline use cases. Our work rapidly derives suitable model variants while maintaining the accuracy of the original model. The model variants can be swapped quickly when system and network conditions change to match workload demand. This paper presents DNNShifter, an end-to-end DNN training, spatial pruning, and model switching system that addresses the challenges mentioned above. At the heart of DNNShifter is a novel methodology that prunes sparse models using structured pruning. The pruned model variants generated by DNNShifter are smaller in size and thus faster than dense and sparse model predecessors, making them suitable for inference at the edge while retaining near similar accuracy as of the original dense model. DNNShifter generates a portfolio of model variants that can be swiftly interchanged depending on operational conditions. DNNShifter produces pruned model variants up to 93x faster than conventional training methods. Compared to sparse models, the pruned model variants are up to 5.14x smaller and have a 1.67x inference latency speedup, with no compromise to sparse model accuracy. In addition, DNNShifter has up to 11.9x lower overhead for switching models and up to 3.8x lower memory utilisation than existing approaches.