 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRIVE: Dual Gradient-Based Rapid Iterative Pruning
Paper and Code
Apr 01, 2024
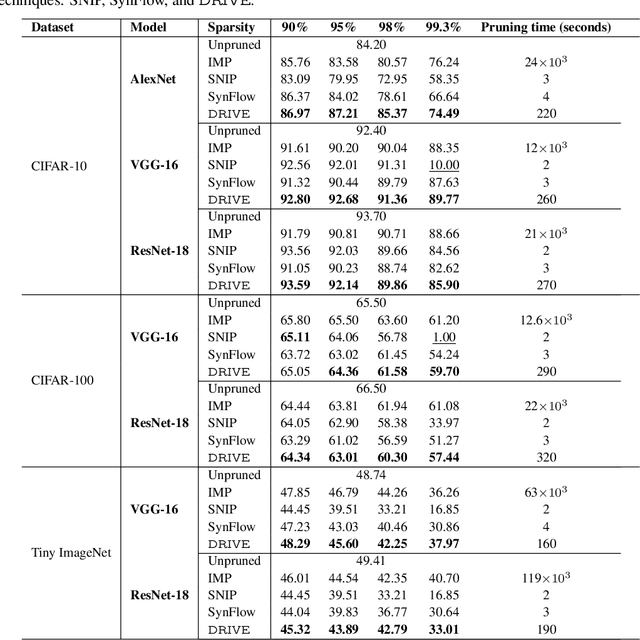
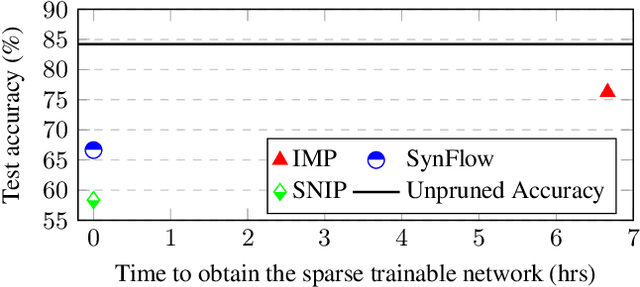
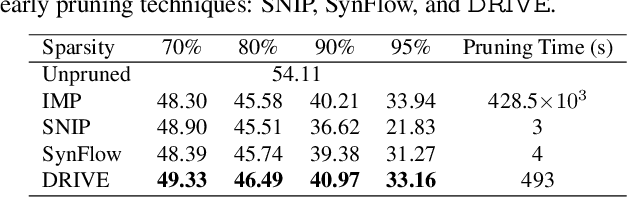
Modern deep neural networks (DNNs) consist of millions of parameters, necessitating high-performance computing during training and inference. Pruning is one solution that significantly reduces the space and time complexities of DNNs. Traditional pruning methods that are applied post-training focus on streamlining inference, but there are recent efforts to leverage sparsity early on by pruning before training. Pruning methods, such as iterative magnitude-based pruning (IMP) achieve up to a 90% parameter reduction while retaining accuracy comparable to the original model. However, this leads to impractical runtime as it relies on multiple train-prune-reset cycles to identify and eliminate redundant parameters. In contrast, training agnostic early pruning methods, such as SNIP and SynFlow offer fast pruning but fall short of the accuracy achieved by IMP at high sparsities. To bridge this gap, we present Dual Gradient-Based Rapid Iterative Pruning (DRIVE), which leverages dense training for initial epochs to counteract the randomness inherent at the initialization. Subsequently, it employs a unique dual gradient-based metric for parameter ranking. It has been experimentally demonstrated for VGG and ResNet architectures on CIFAR-10/100 and Tiny ImageNet, and ResNet on ImageNet that DRIVE consistently has superior performance over other training-agnostic early pruning methods in accuracy. Notably, DRIVE is 43$\times$ to 869$\times$ faster than IMP for pruning.