 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignal Collapse in One-Shot Pruning: When Sparse Models Fail to Distinguish Neural Representations
Feb 18, 2025Neural network pruning is essential for reducing model complexity to enable deployment on resource constrained hardware. While performance loss of pruned networks is often attributed to the removal of critical parameters, we identify signal collapse a reduction in activation variance across layers as the root cause. Existing one shot pruning methods focus on weight selection strategies and rely on computationally expensive second order approximations. In contrast, we demonstrate that mitigating signal collapse, rather than optimizing weight selection, is key to improving accuracy of pruned networks. We propose REFLOW that addresses signal collapse without updating trainable weights, revealing high quality sparse sub networks within the original parameter space. REFLOW enables magnitude pruning to achieve state of the art performance, restoring ResNeXt101 accuracy from under 4.1% to 78.9% on ImageNet with only 20% of the weights retained, surpassing state of the art approaches.
DRIVE: Dual Gradient-Based Rapid Iterative Pruning
Apr 01, 2024
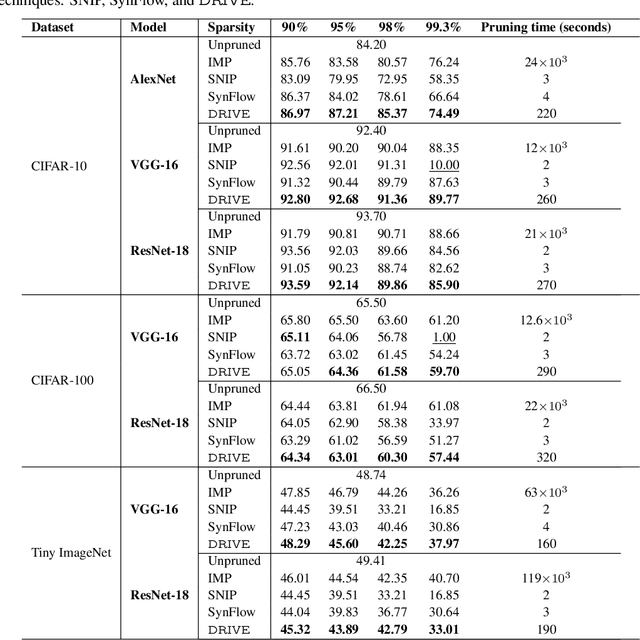
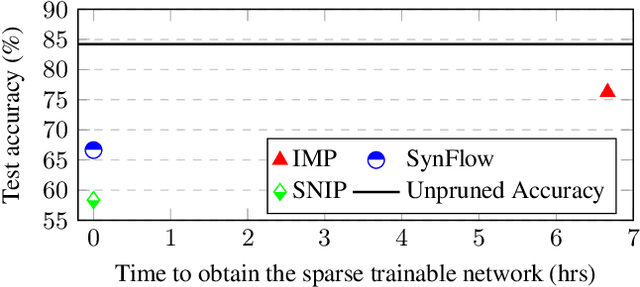
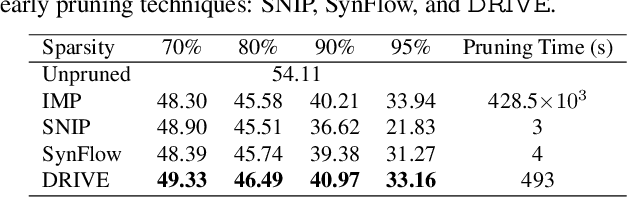
Modern deep neural networks (DNNs) consist of millions of parameters, necessitating high-performance computing during training and inference. Pruning is one solution that significantly reduces the space and time complexities of DNNs. Traditional pruning methods that are applied post-training focus on streamlining inference, but there are recent efforts to leverage sparsity early on by pruning before training. Pruning methods, such as iterative magnitude-based pruning (IMP) achieve up to a 90% parameter reduction while retaining accuracy comparable to the original model. However, this leads to impractical runtime as it relies on multiple train-prune-reset cycles to identify and eliminate redundant parameters. In contrast, training agnostic early pruning methods, such as SNIP and SynFlow offer fast pruning but fall short of the accuracy achieved by IMP at high sparsities. To bridge this gap, we present Dual Gradient-Based Rapid Iterative Pruning (DRIVE), which leverages dense training for initial epochs to counteract the randomness inherent at the initialization. Subsequently, it employs a unique dual gradient-based metric for parameter ranking. It has been experimentally demonstrated for VGG and ResNet architectures on CIFAR-10/100 and Tiny ImageNet, and ResNet on ImageNet that DRIVE consistently has superior performance over other training-agnostic early pruning methods in accuracy. Notably, DRIVE is 43$\times$ to 869$\times$ faster than IMP for pruning.
NeuroFlux: Memory-Efficient CNN Training Using Adaptive Local Learning
Mar 04, 2024



Efficient on-device Convolutional Neural Network (CNN) training in resource-constrained mobile and edge environments is an open challenge. Backpropagation is the standard approach adopted, but it is GPU memory intensive due to its strong inter-layer dependencies that demand intermediate activations across the entire CNN model to be retained in GPU memory. This necessitates smaller batch sizes to make training possible within the available GPU memory budget, but in turn, results in substantially high and impractical training time. We introduce NeuroFlux, a novel CNN training system tailored for memory-constrained scenarios. We develop two novel opportunities: firstly, adaptive auxiliary networks that employ a variable number of filters to reduce GPU memory usage, and secondly, block-specific adaptive batch sizes, which not only cater to the GPU memory constraints but also accelerate the training process. NeuroFlux segments a CNN into blocks based on GPU memory usage and further attaches an auxiliary network to each layer in these blocks. This disrupts the typical layer dependencies under a new training paradigm - $\textit{`adaptive local learning'}$. Moreover, NeuroFlux adeptly caches intermediate activations, eliminating redundant forward passes over previously trained blocks, further accelerating the training process. The results are twofold when compared to Backpropagation: on various hardware platforms, NeuroFlux demonstrates training speed-ups of 2.3$\times$ to 6.1$\times$ under stringent GPU memory budgets, and NeuroFlux generates streamlined models that have 10.9$\times$ to 29.4$\times$ fewer parameters.