 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdjoint-based shape optimization of a ship hull using a Conditional Variational Autoencoder (CVAE) assisted propulsion surrogate model
Feb 17, 2026Adjoint-based shape optimization of ship hulls is a powerful tool for addressing high-dimensional design problems in naval architecture, particularly in minimizing the ship resistance. However, its application to vessels that employ complex propulsion systems introduces significant challenges. They arise from the need for transient simulations extending over long periods of time with small time steps and from the reverse temporal propagation of the primal and adjoint solutions. These challenges place considerable demands on the required storage and computing power, which significantly hamper the use of adjoint methods in the industry. To address this issue, we propose a machine learning-assisted optimization framework that employs a Conditional Variational Autoencoder-based surrogate model of the propulsion system. The surrogate model replicates the time-averaged flow field induced by a Voith Schneider Propeller and replaces the geometrically and time-resolved propeller with a data-driven approximation. Primal flow verification examples demonstrate that the surrogate model achieves significant computational savings while maintaining the necessary accuracy of the resolved propeller. Optimization studies show that ignoring the propulsion system can yield designs that perform worse than the initial shape. In contrast, the proposed method produces shapes that achieve more than an 8\% reduction in resistance.
Real-time Adapting Routing (RAR): Improving Efficiency Through Continuous Learning in Software Powered by Layered Foundation Models
Nov 14, 2024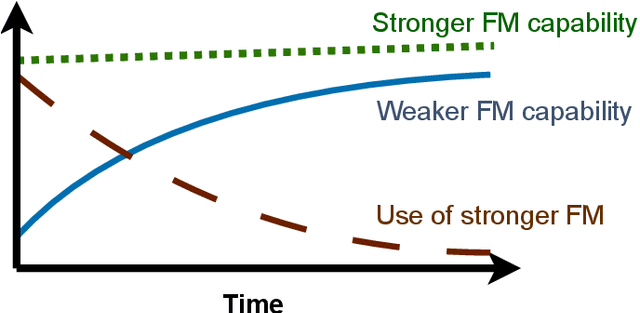
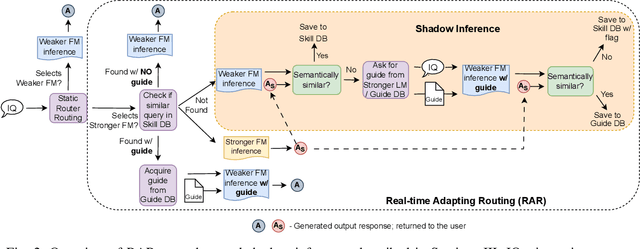
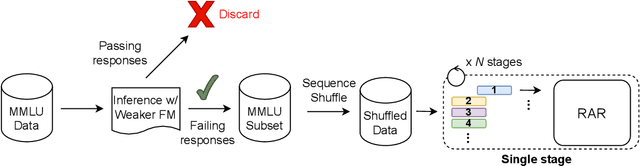
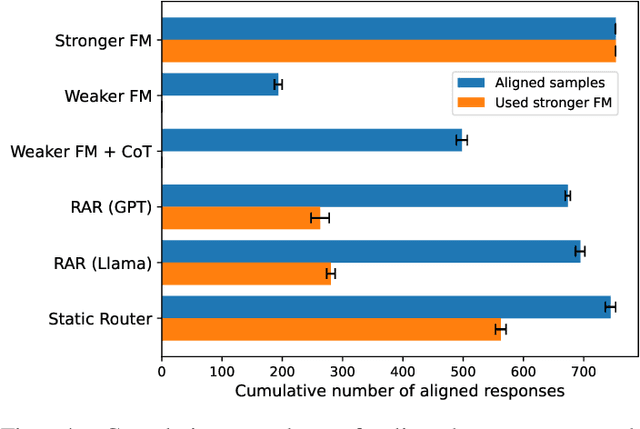
To balance the quality and inference cost of a Foundation Model (FM, such as large language models (LLMs)) powered software, people often opt to train a routing model that routes requests to FMs with different sizes and capabilities. Existing routing models rely on learning the optimal routing decision from carefully curated data, require complex computations to be updated, and do not consider the potential evolution of weaker FMs. In this paper, we propose Real-time Adaptive Routing (RAR), an approach to continuously adapt FM routing decisions while using guided in-context learning to enhance the capabilities of weaker FM. The goal is to reduce reliance on stronger, more expensive FMs. We evaluate our approach on different subsets of the popular MMLU benchmark. Over time, our approach routes 50.2% fewer requests to computationally expensive models while maintaining around 90.5% of the general response quality. In addition, the guides generated from stronger models have shown intra-domain generalization and led to a better quality of responses compared to an equivalent approach with a standalone weaker FM.
DAM: Towards A Foundation Model for Time Series Forecasting
Jul 25, 2024It is challenging to scale time series forecasting models such that they forecast accurately for multiple distinct domains and datasets, all with potentially different underlying collection procedures (e.g., sample resolution), patterns (e.g., periodicity), and prediction requirements (e.g., reconstruction vs. forecasting). We call this general task universal forecasting. Existing methods usually assume that input data is regularly sampled, and they forecast to pre-determined horizons, resulting in failure to generalise outside of the scope of their training. We propose the DAM - a neural model that takes randomly sampled histories and outputs an adjustable basis composition as a continuous function of time for forecasting to non-fixed horizons. It involves three key components: (1) a flexible approach for using randomly sampled histories from a long-tail distribution, that enables an efficient global perspective of the underlying temporal dynamics while retaining focus on the recent history; (2) a transformer backbone that is trained on these actively sampled histories to produce, as representational output, (3) the basis coefficients of a continuous function of time. We show that a single univariate DAM, trained on 25 time series datasets, either outperformed or closely matched existing SoTA models at multivariate long-term forecasting across 18 datasets, including 8 held-out for zero-shot transfer, even though these models were trained to specialise for each dataset-horizon combination. This single DAM excels at zero-shot transfer and very-long-term forecasting, performs well at imputation, is interpretable via basis function composition and attention, can be tuned for different inference-cost requirements, is robust to missing and irregularly sampled data {by design}.
Remaining Useful Life Prediction for Aircraft Engines using LSTM
Jan 15, 2024This study uses a Long Short-Term Memory (LSTM) network to predict the remaining useful life (RUL) of jet engines from time-series data, crucial for aircraft maintenance and safety. The LSTM model's performance is compared with a Multilayer Perceptron (MLP) on the C-MAPSS dataset from NASA, which contains jet engine run-to-failure events. The LSTM learns from temporal sequences of sensor data, while the MLP learns from static data snapshots. The LSTM model consistently outperforms the MLP in prediction accuracy, demonstrating its superior ability to capture temporal dependencies in jet engine degradation patterns. The software for this project is in https://github.com/AneesPeringal/rul-prediction.git.
How Does It Function? Characterizing Long-term Trends in Production Serverless Workloads
Dec 15, 2023This paper releases and analyzes two new Huawei cloud serverless traces. The traces span a period of over 7 months with over 1.4 trillion function invocations combined. The first trace is derived from Huawei's internal workloads and contains detailed per-second statistics for 200 functions running across multiple Huawei cloud data centers. The second trace is a representative workload from Huawei's public FaaS platform. This trace contains per-minute arrival rates for over 5000 functions running in a single Huawei data center. We present the internals of a production FaaS platform by characterizing resource consumption, cold-start times, programming languages used, periodicity, per-second versus per-minute burstiness, correlations, and popularity. Our findings show that there is considerable diversity in how serverless functions behave: requests vary by up to 9 orders of magnitude across functions, with some functions executed over 1 billion times per day; scheduling time, execution time and cold-start distributions vary across 2 to 4 orders of magnitude and have very long tails; and function invocation counts demonstrate strong periodicity for many individual functions and on an aggregate level. Our analysis also highlights the need for further research in estimating resource reservations and time-series prediction to account for the huge diversity in how serverless functions behave. Datasets and code available at https://github.com/sir-lab/data-release
The effect of linguistic constraints on the large scale organization of language
Feb 15, 2011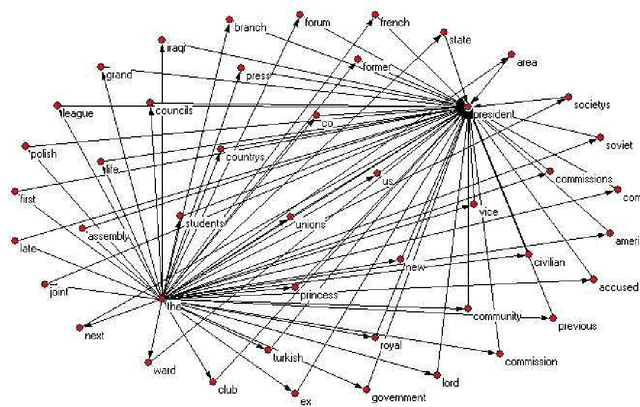
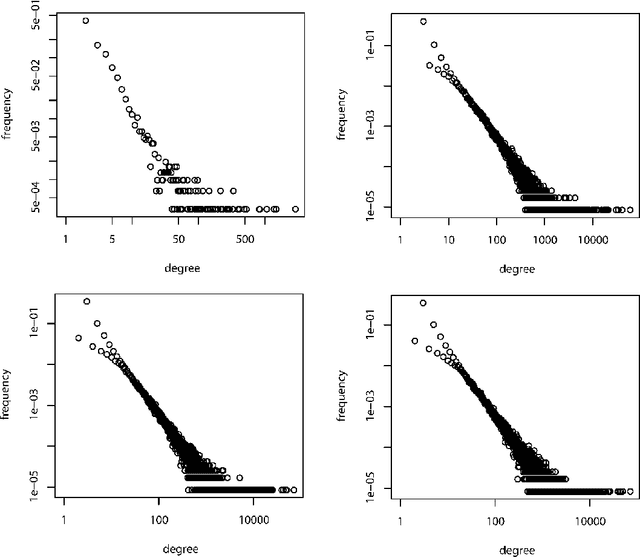
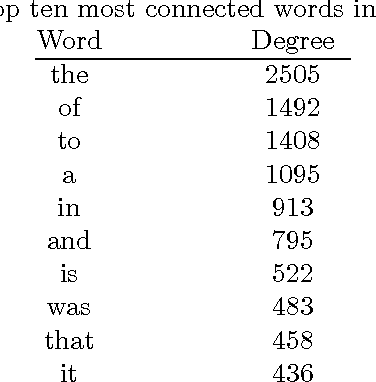
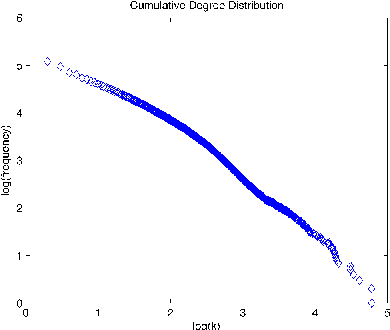
This paper studies the effect of linguistic constraints on the large scale organization of language. It describes the properties of linguistic networks built using texts of written language with the words randomized. These properties are compared to those obtained for a network built over the text in natural order. It is observed that the "random" networks too exhibit small-world and scale-free characteristics. They also show a high degree of clustering. This is indeed a surprising result - one that has not been addressed adequately in the literature. We hypothesize that many of the network statistics reported here studied are in fact functions of the distribution of the underlying data from which the network is built and may not be indicative of the nature of the concerned network.