 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe effect of linguistic constraints on the large scale organization of language
Paper and Code
Feb 15, 2011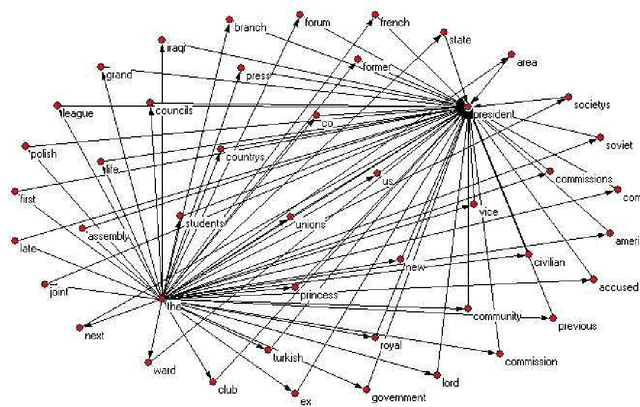
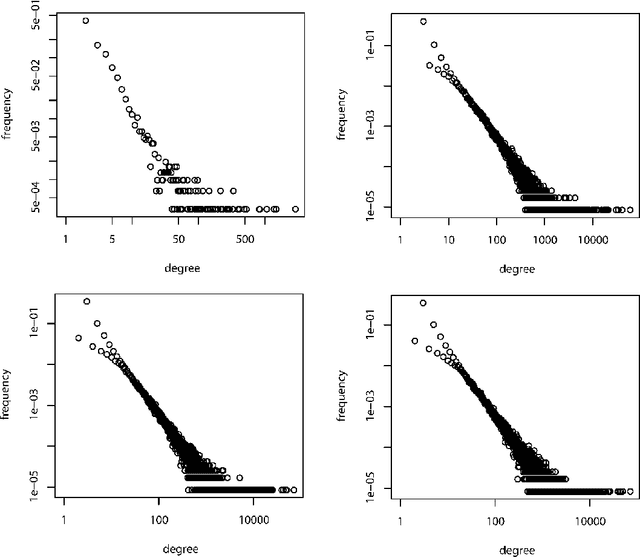
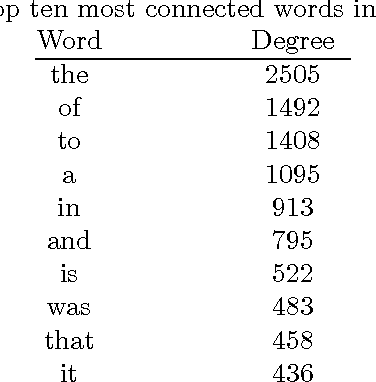
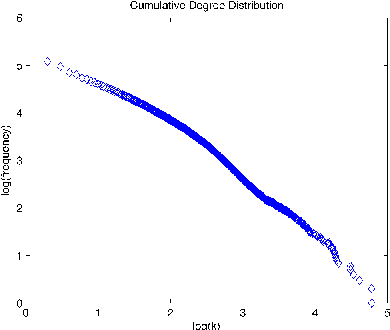
This paper studies the effect of linguistic constraints on the large scale organization of language. It describes the properties of linguistic networks built using texts of written language with the words randomized. These properties are compared to those obtained for a network built over the text in natural order. It is observed that the "random" networks too exhibit small-world and scale-free characteristics. They also show a high degree of clustering. This is indeed a surprising result - one that has not been addressed adequately in the literature. We hypothesize that many of the network statistics reported here studied are in fact functions of the distribution of the underlying data from which the network is built and may not be indicative of the nature of the concerned network.