 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance of Zero-Shot Time Series Foundation Models on Cloud Data
Feb 18, 2025Time series foundation models (FMs) have emerged as a popular paradigm for zero-shot multi-domain forecasting. FMs are trained on numerous diverse datasets and claim to be effective forecasters across multiple different time series domains, including cloud data. In this work we investigate this claim, exploring the effectiveness of FMs on cloud data. We demonstrate that many well-known FMs fail to generate meaningful or accurate zero-shot forecasts in this setting. We support this claim empirically, showing that FMs are outperformed consistently by simple linear baselines. We also illustrate a number of interesting pathologies, including instances where FMs suddenly output seemingly erratic, random-looking forecasts. Our results suggest a widespread failure of FMs to model cloud data.
Lightweight Online Adaption for Time Series Foundation Model Forecasts
Feb 18, 2025Foundation models (FMs) have emerged as a promising approach for time series forecasting. While effective, FMs typically remain fixed during deployment due to the high computational costs of learning them online. Consequently, deployed FMs fail to adapt their forecasts to current data characteristics, despite the availability of online feedback from newly arriving data. This raises the question of whether FM performance can be enhanced by the efficient usage of this feedback. We propose AdapTS to answer this question. AdapTS is a lightweight mechanism for the online adaption of FM forecasts in response to online feedback. AdapTS consists of two parts: a) the AdapTS-Forecaster which is used to learn the current data distribution; and b) the AdapTS-Weighter which is used to combine the forecasts of the FM and the AdapTS-Forecaster. We evaluate the performance of AdapTS in conjunction with several recent FMs across a suite of standard time series datasets. In all of our experiments we find that using AdapTS improves performance. This work demonstrates how efficient usage of online feedback can be used to improve FM forecasts.
Noisy Early Stopping for Noisy Labels
Sep 10, 2024Training neural network classifiers on datasets contaminated with noisy labels significantly increases the risk of overfitting. Thus, effectively implementing Early Stopping in noisy label environments is crucial. Under ideal circumstances, Early Stopping utilises a validation set uncorrupted by label noise to effectively monitor generalisation during training. However, obtaining a noise-free validation dataset can be costly and challenging to obtain. This study establishes that, in many typical learning environments, a noise-free validation set is not necessary for effective Early Stopping. Instead, near-optimal results can be achieved by monitoring accuracy on a noisy dataset - drawn from the same distribution as the noisy training set. Referred to as `Noisy Early Stopping' (NES), this method simplifies and reduces the cost of implementing Early Stopping. We provide theoretical insights into the conditions under which this method is effective and empirically demonstrate its robust performance across standard benchmarks using common loss functions.
An Analysis of Linear Time Series Forecasting Models
Mar 25, 2024Despite their simplicity, linear models perform well at time series forecasting, even when pitted against deeper and more expensive models. A number of variations to the linear model have been proposed, often including some form of feature normalisation that improves model generalisation. In this paper we analyse the sets of functions expressible using these linear model architectures. In so doing we show that several popular variants of linear models for time series forecasting are equivalent and functionally indistinguishable from standard, unconstrained linear regression. We characterise the model classes for each linear variant. We demonstrate that each model can be reinterpreted as unconstrained linear regression over a suitably augmented feature set, and therefore admit closed-form solutions when using a mean-squared loss function. We provide experimental evidence that the models under inspection learn nearly identical solutions, and finally demonstrate that the simpler closed form solutions are superior forecasters across 72% of test settings.
Label Noise: Correcting a Correction
Jul 24, 2023
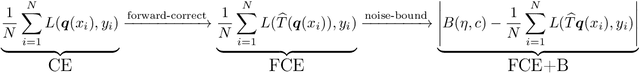


Training neural network classifiers on datasets with label noise poses a risk of overfitting them to the noisy labels. To address this issue, researchers have explored alternative loss functions that aim to be more robust. However, many of these alternatives are heuristic in nature and still vulnerable to overfitting or underfitting. In this work, we propose a more direct approach to tackling overfitting caused by label noise. We observe that the presence of label noise implies a lower bound on the noisy generalised risk. Building upon this observation, we propose imposing a lower bound on the empirical risk during training to mitigate overfitting. Our main contribution is providing theoretical results that yield explicit, easily computable bounds on the minimum achievable noisy risk for different loss functions. We empirically demonstrate that using these bounds significantly enhances robustness in various settings, with virtually no additional computational cost.