 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision Tree Induction Through LLMs via Semantically-Aware Evolution
Mar 18, 2025Decision trees are a crucial class of models offering robust predictive performance and inherent interpretability across various domains, including healthcare, finance, and logistics. However, current tree induction methods often face limitations such as suboptimal solutions from greedy methods or prohibitive computational costs and limited applicability of exact optimization approaches. To address these challenges, we propose an evolutionary optimization method for decision tree induction based on genetic programming (GP). Our key innovation is the integration of semantic priors and domain-specific knowledge about the search space into the optimization algorithm. To this end, we introduce $\texttt{LLEGO}$, a framework that incorporates semantic priors into genetic search operators through the use of Large Language Models (LLMs), thereby enhancing search efficiency and targeting regions of the search space that yield decision trees with superior generalization performance. This is operationalized through novel genetic operators that work with structured natural language prompts, effectively utilizing LLMs as conditional generative models and sources of semantic knowledge. Specifically, we introduce $\textit{fitness-guided}$ crossover to exploit high-performing regions, and $\textit{diversity-guided}$ mutation for efficient global exploration of the search space. These operators are controlled by corresponding hyperparameters that enable a more nuanced balance between exploration and exploitation across the search space. Empirically, we demonstrate across various benchmarks that $\texttt{LLEGO}$ evolves superior-performing trees compared to existing tree induction methods, and exhibits significantly more efficient search performance compared to conventional GP approaches.
You can't handle the truth: Data-centric insights improve pseudo-labeling
Jun 19, 2024Pseudo-labeling is a popular semi-supervised learning technique to leverage unlabeled data when labeled samples are scarce. The generation and selection of pseudo-labels heavily rely on labeled data. Existing approaches implicitly assume that the labeled data is gold standard and 'perfect'. However, this can be violated in reality with issues such as mislabeling or ambiguity. We address this overlooked aspect and show the importance of investigating labeled data quality to improve any pseudo-labeling method. Specifically, we introduce a novel data characterization and selection framework called DIPS to extend pseudo-labeling. We select useful labeled and pseudo-labeled samples via analysis of learning dynamics. We demonstrate the applicability and impact of DIPS for various pseudo-labeling methods across an extensive range of real-world tabular and image datasets. Additionally, DIPS improves data efficiency and reduces the performance distinctions between different pseudo-labelers. Overall, we highlight the significant benefits of a data-centric rethinking of pseudo-labeling in real-world settings.
DAGnosis: Localized Identification of Data Inconsistencies using Structures
Feb 28, 2024



Identification and appropriate handling of inconsistencies in data at deployment time is crucial to reliably use machine learning models. While recent data-centric methods are able to identify such inconsistencies with respect to the training set, they suffer from two key limitations: (1) suboptimality in settings where features exhibit statistical independencies, due to their usage of compressive representations and (2) lack of localization to pin-point why a sample might be flagged as inconsistent, which is important to guide future data collection. We solve these two fundamental limitations using directed acyclic graphs (DAGs) to encode the training set's features probability distribution and independencies as a structure. Our method, called DAGnosis, leverages these structural interactions to bring valuable and insightful data-centric conclusions. DAGnosis unlocks the localization of the causes of inconsistencies on a DAG, an aspect overlooked by previous approaches. Moreover, we show empirically that leveraging these interactions (1) leads to more accurate conclusions in detecting inconsistencies, as well as (2) provides more detailed insights into why some samples are flagged.
Time Series Diffusion in the Frequency Domain
Feb 08, 2024Fourier analysis has been an instrumental tool in the development of signal processing. This leads us to wonder whether this framework could similarly benefit generative modelling. In this paper, we explore this question through the scope of time series diffusion models. More specifically, we analyze whether representing time series in the frequency domain is a useful inductive bias for score-based diffusion models. By starting from the canonical SDE formulation of diffusion in the time domain, we show that a dual diffusion process occurs in the frequency domain with an important nuance: Brownian motions are replaced by what we call mirrored Brownian motions, characterized by mirror symmetries among their components. Building on this insight, we show how to adapt the denoising score matching approach to implement diffusion models in the frequency domain. This results in frequency diffusion models, which we compare to canonical time diffusion models. Our empirical evaluation on real-world datasets, covering various domains like healthcare and finance, shows that frequency diffusion models better capture the training distribution than time diffusion models. We explain this observation by showing that time series from these datasets tend to be more localized in the frequency domain than in the time domain, which makes them easier to model in the former case. All our observations point towards impactful synergies between Fourier analysis and diffusion models.
Curated LLM: Synergy of LLMs and Data Curation for tabular augmentation in ultra low-data regimes
Dec 19, 2023Machine Learning (ML) in low-data settings remains an underappreciated yet crucial problem. This challenge is pronounced in low-to-middle income countries where access to large datasets is often limited or even absent. Hence, data augmentation methods to increase the sample size of datasets needed for ML are key to unlocking the transformative potential of ML in data-deprived regions and domains. Unfortunately, the limited training set constrains traditional tabular synthetic data generators in their ability to generate a large and diverse augmented dataset needed for ML tasks. To address this technical challenge, we introduce CLLM, which leverages the prior knowledge of Large Language Models (LLMs) for data augmentation in the low-data regime. While diverse, not all the data generated by LLMs will help increase utility for a downstream task, as for any generative model. Consequently, we introduce a principled curation process, leveraging learning dynamics, coupled with confidence and uncertainty metrics, to obtain a high-quality dataset. Empirically, on multiple real-world datasets, we demonstrate the superior performance of LLMs in the low-data regime compared to conventional generators. We further show our curation mechanism improves the downstream performance for all generators, including LLMs. Additionally, we provide insights and understanding into the LLM generation and curation mechanism, shedding light on the features that enable them to output high-quality augmented datasets. CLLM paves the way for wider usage of ML in data scarce domains and regions, by allying the strengths of LLMs with a robust data-centric approach.
Active Preference-Based Gaussian Process Regression for Reward Learning
Jun 03, 2020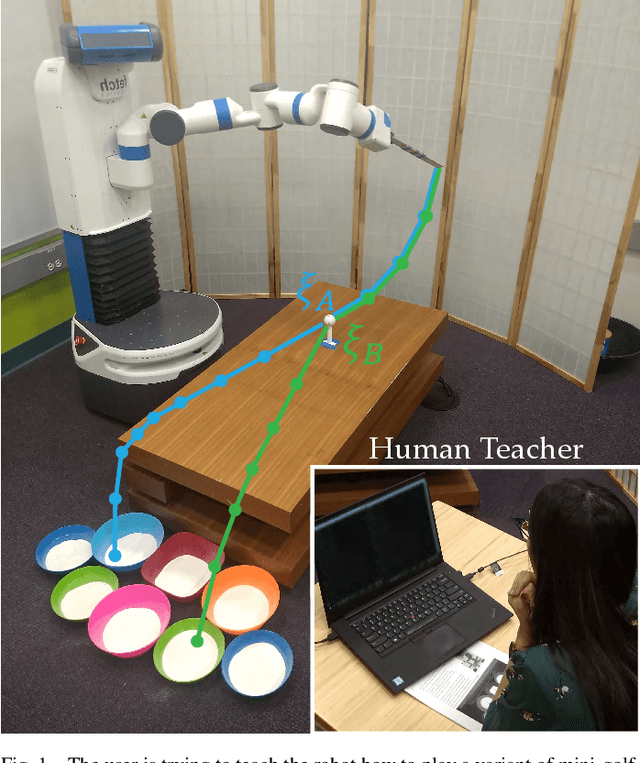

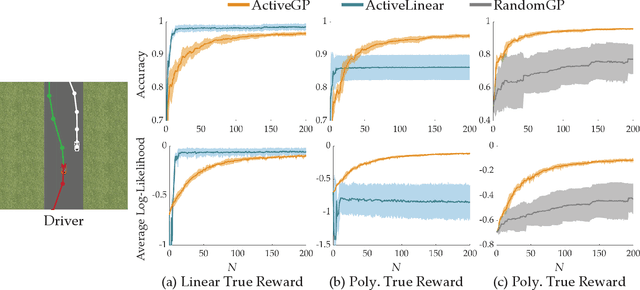
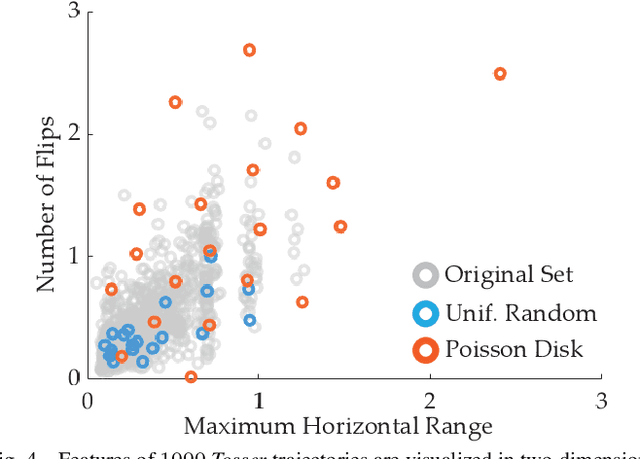
Designing reward functions is a challenging problem in AI and robotics. Humans usually have a difficult time directly specifying all the desirable behaviors that a robot needs to optimize. One common approach is to learn reward functions from collected expert demonstrations. However, learning reward functions from demonstrations introduces many challenges: some methods require highly structured models, e.g. reward functions that are linear in some predefined set of features, while others adopt less structured reward functions that on the other hand require tremendous amount of data. In addition, humans tend to have a difficult time providing demonstrations on robots with high degrees of freedom, or even quantifying reward values for given demonstrations. To address these challenges, we present a preference-based learning approach, where as an alternative, the human feedback is only in the form of comparisons between trajectories. Furthermore, we do not assume highly constrained structures on the reward function. Instead, we model the reward function using a Gaussian Process (GP) and propose a mathematical formulation to actively find a GP using only human preferences. Our approach enables us to tackle both inflexibility and data-inefficiency problems within a preference-based learning framework. Our results in simulations and a user study suggest that our approach can efficiently learn expressive reward functions for robotics tasks.